 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedCARE: Federated Unlearning with Conflict-Aware Projection and Relearning-Resistant Recovery
Jan 30, 2026Federated learning (FL) enables collaborative model training without centralizing raw data, but privacy regulations such as the right to be forgotten require FL systems to remove the influence of previously used training data upon request. Retraining a federated model from scratch is prohibitively expensive, motivating federated unlearning (FU). However, existing FU methods suffer from high unlearning overhead, utility degradation caused by entangled knowledge, and unintended relearning during post-unlearning recovery. In this paper, we propose FedCARE, a unified and low overhead FU framework that enables conflict-aware unlearning and relearning-resistant recovery. FedCARE leverages gradient ascent for efficient forgetting when target data are locally available and employs data free model inversion to construct class level proxies of shared knowledge. Based on these insights, FedCARE integrates a pseudo-sample generator, conflict-aware projected gradient ascent for utility preserving unlearning, and a recovery strategy that suppresses rollback toward the pre-unlearning model. FedCARE supports client, instance, and class level unlearning with modest overhead. Extensive experiments on multiple datasets and model architectures under both IID and non-IID settings show that FedCARE achieves effective forgetting, improved utility retention, and reduced relearning risk compared to state of the art FU baselines.
Benchmarking and Understanding Compositional Relational Reasoning of LLMs
Dec 17, 2024



Compositional relational reasoning (CRR) is a hallmark of human intelligence, but we lack a clear understanding of whether and how existing transformer large language models (LLMs) can solve CRR tasks. To enable systematic exploration of the CRR capability of LLMs, we first propose a new synthetic benchmark called Generalized Associative Recall (GAR) by integrating and generalizing the essence of several tasks in mechanistic interpretability (MI) study in a unified framework. Evaluation shows that GAR is challenging enough for existing LLMs, revealing their fundamental deficiency in CRR. Meanwhile, it is easy enough for systematic MI study. Then, to understand how LLMs solve GAR tasks, we use attribution patching to discover the core circuits reused by Vicuna-33B across different tasks and a set of vital attention heads. Intervention experiments show that the correct functioning of these heads significantly impacts task performance. Especially, we identify two classes of heads whose activations represent the abstract notion of true and false in GAR tasks respectively. They play a fundamental role in CRR across various models and tasks. The dataset and code are available at https://github.com/Caiyun-AI/GAR.
Improving Transformers with Dynamically Composable Multi-Head Attention
May 14, 2024



Multi-Head Attention (MHA) is a key component of Transformer. In MHA, attention heads work independently, causing problems such as low-rank bottleneck of attention score matrices and head redundancy. We propose Dynamically Composable Multi-Head Attention (DCMHA), a parameter and computation efficient attention architecture that tackles the shortcomings of MHA and increases the expressive power of the model by dynamically composing attention heads. At the core of DCMHA is a $\it{Compose}$ function that transforms the attention score and weight matrices in an input-dependent way. DCMHA can be used as a drop-in replacement of MHA in any transformer architecture to obtain the corresponding DCFormer. DCFormer significantly outperforms Transformer on different architectures and model scales in language modeling, matching the performance of models with ~1.7x-2.0x compute. For example, DCPythia-6.9B outperforms open source Pythia-12B on both pretraining perplexity and downstream task evaluation. The code and models are available at https://github.com/Caiyun-AI/DCFormer.
The Hidden Shape of Stories Reveals Positivity Bias and Gender Bias
Nov 12, 2018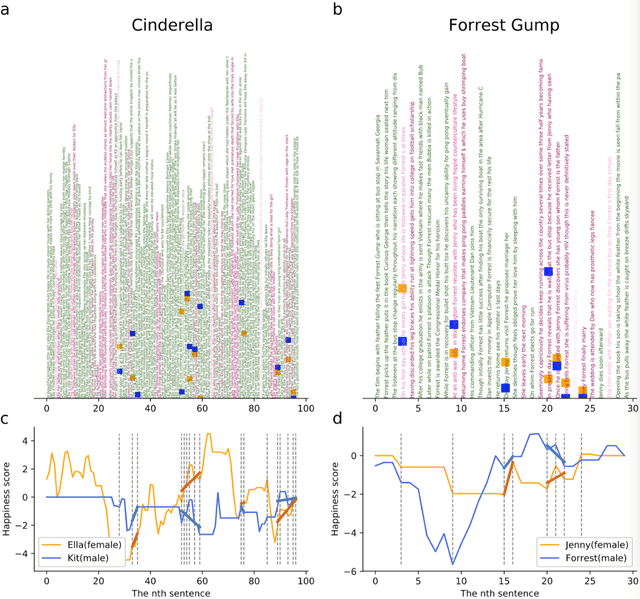
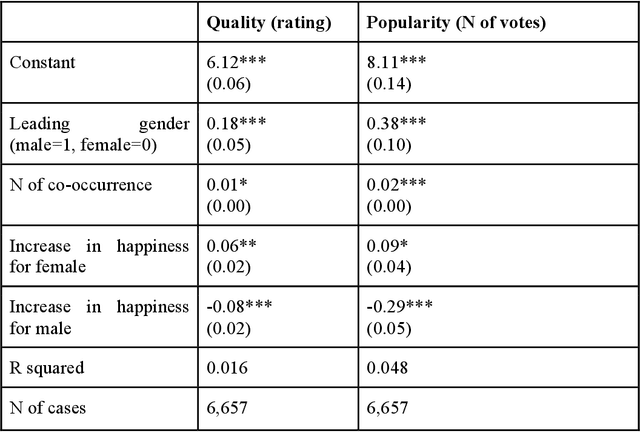
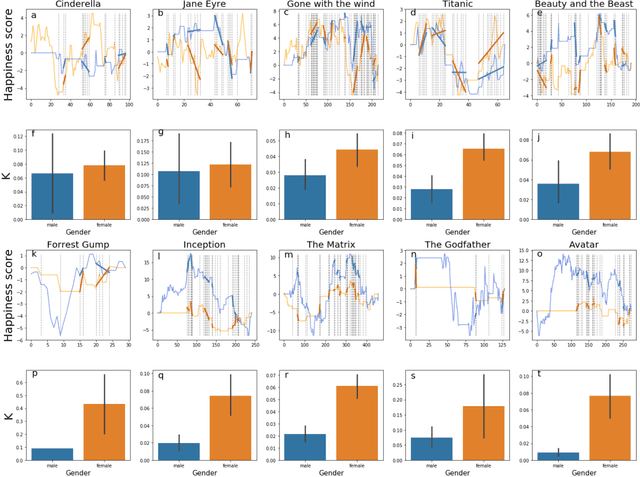
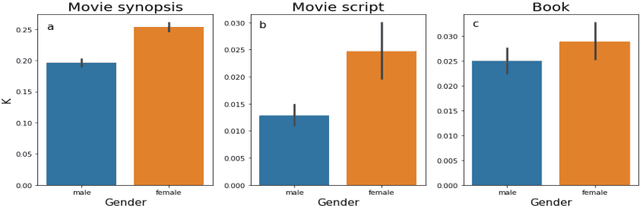
To capture the shape of stories is crucial for understanding the mind of human beings. In this research, we use word emdeddings methods, a widely used tool in natural language processing and machine learning, in order to quantify and compare emotional arcs of stories over time. Based on trained Google News word2vec vectors and film scripts corpora (N =1109), we form the fundamental building blocks of story emotional trajectories. The results demonstrate that there exists only one universal pattern of story shapes in movies. Furthermore, there exists a positivity and gender bias in story narratives. More interestingly, the audience reveals a completely different preference from content producers.
Improving the Universality and Learnability of Neural Programmer-Interpreters with Combinator Abstraction
Feb 08, 2018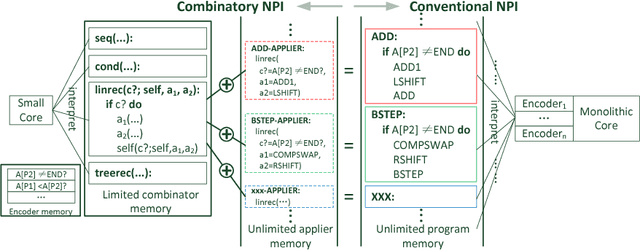


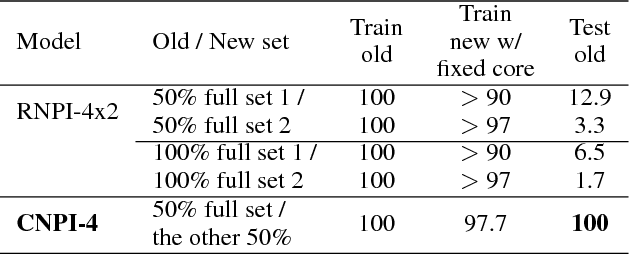
To overcome the limitations of Neural Programmer-Interpreters (NPI) in its universality and learnability, we propose the incorporation of combinator abstraction into neural programing and a new NPI architecture to support this abstraction, which we call Combinatory Neural Programmer-Interpreter (CNPI). Combinator abstraction dramatically reduces the number and complexity of programs that need to be interpreted by the core controller of CNPI, while still allowing the CNPI to represent and interpret arbitrary complex programs by the collaboration of the core with the other components. We propose a small set of four combinators to capture the most pervasive programming patterns. Due to the finiteness and simplicity of this combinator set and the offloading of some burden of interpretation from the core, we are able construct a CNPI that is universal with respect to the set of all combinatorizable programs, which is adequate for solving most algorithmic tasks. Moreover, besides supervised training on execution traces, CNPI can be trained by policy gradient reinforcement learning with appropriately designed curricula.
An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks
Mar 04, 2015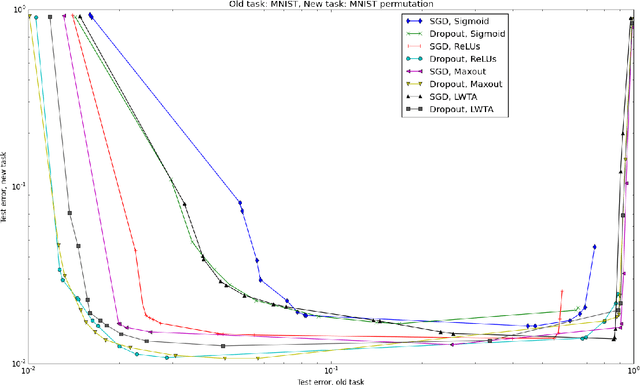
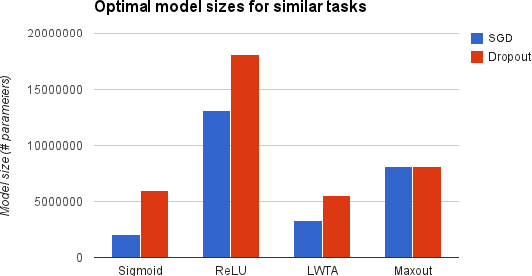
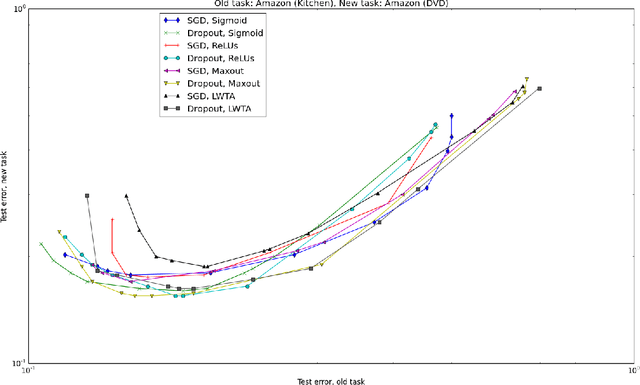
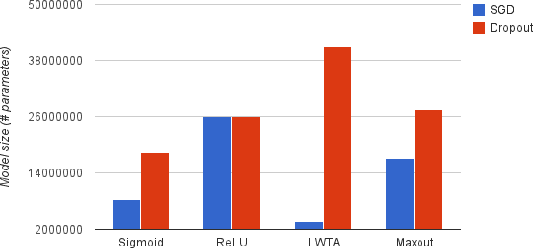
Catastrophic forgetting is a problem faced by many machine learning models and algorithms. When trained on one task, then trained on a second task, many machine learning models "forget" how to perform the first task. This is widely believed to be a serious problem for neural networks. Here, we investigate the extent to which the catastrophic forgetting problem occurs for modern neural networks, comparing both established and recent gradient-based training algorithms and activation functions. We also examine the effect of the relationship between the first task and the second task on catastrophic forgetting. We find that it is always best to train using the dropout algorithm--the dropout algorithm is consistently best at adapting to the new task, remembering the old task, and has the best tradeoff curve between these two extremes. We find that different tasks and relationships between tasks result in very different rankings of activation function performance. This suggests the choice of activation function should always be cross-validated.