 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBonnet: Ultra-fast whole-body bone segmentation from CT scans
Jan 30, 2026This work proposes Bonnet, an ultra-fast sparse-volume pipeline for whole-body bone segmentation from CT scans. Accurate bone segmentation is important for surgical planning and anatomical analysis, but existing 3D voxel-based models such as nnU-Net and STU-Net require heavy computation and often take several minutes per scan, which limits time-critical use. The proposed Bonnet addresses this by integrating a series of novel framework components including HU-based bone thresholding, patch-wise inference with a sparse spconv-based U-Net, and multi-window fusion into a full-volume prediction. Trained on TotalSegmentator and evaluated without additional tuning on RibSeg, CT-Pelvic1K, and CT-Spine1K, Bonnet achieves high Dice across ribs, pelvis, and spine while running in only 2.69 seconds per scan on an RTX A6000. Compared to strong voxel baselines, Bonnet attains a similar accuracy but reduces inference time by roughly 25x on the same hardware and tiling setup. The toolkit and pre-trained models will be released at https://github.com/HINTLab/Bonnet.
Align Your Rhythm: Generating Highly Aligned Dance Poses with Gating-Enhanced Rhythm-Aware Feature Representation
Mar 21, 2025Automatically generating natural, diverse and rhythmic human dance movements driven by music is vital for virtual reality and film industries. However, generating dance that naturally follows music remains a challenge, as existing methods lack proper beat alignment and exhibit unnatural motion dynamics. In this paper, we propose Danceba, a novel framework that leverages gating mechanism to enhance rhythm-aware feature representation for music-driven dance generation, which achieves highly aligned dance poses with enhanced rhythmic sensitivity. Specifically, we introduce Phase-Based Rhythm Extraction (PRE) to precisely extract rhythmic information from musical phase data, capitalizing on the intrinsic periodicity and temporal structures of music. Additionally, we propose Temporal-Gated Causal Attention (TGCA) to focus on global rhythmic features, ensuring that dance movements closely follow the musical rhythm. We also introduce Parallel Mamba Motion Modeling (PMMM) architecture to separately model upper and lower body motions along with musical features, thereby improving the naturalness and diversity of generated dance movements. Extensive experiments confirm that Danceba outperforms state-of-the-art methods, achieving significantly better rhythmic alignment and motion diversity. Project page: https://danceba.github.io/ .
Optimizing Knowledge Integration in Retrieval-Augmented Generation with Self-Selection
Feb 10, 2025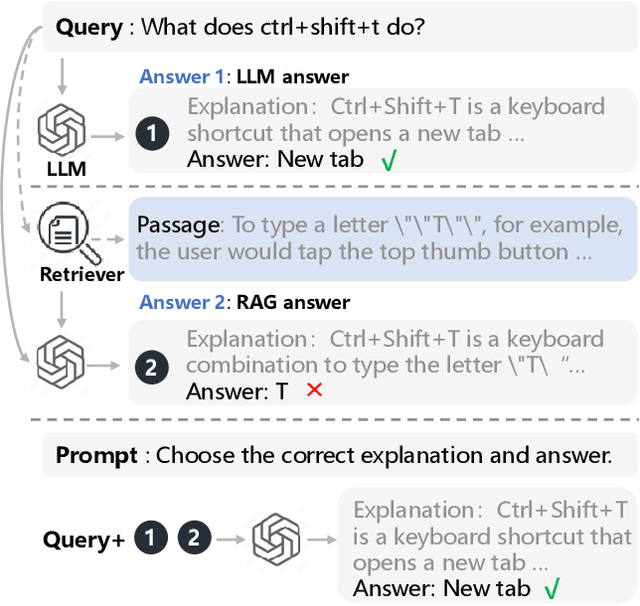
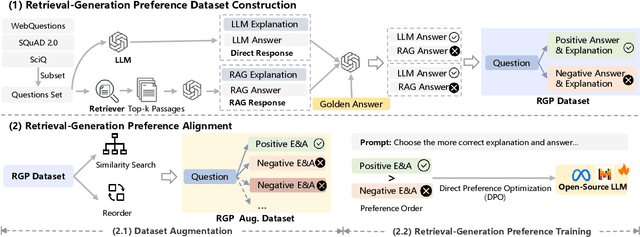
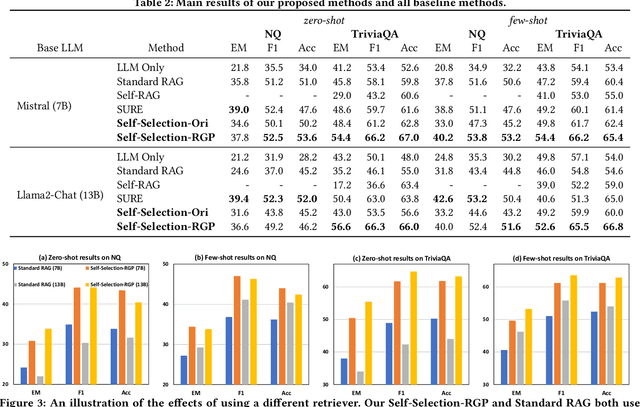
Retrieval-Augmented Generation (RAG), which integrates external knowledge into Large Language Models (LLMs), has proven effective in enabling LLMs to produce more accurate and reliable responses. However, it remains a significant challenge how to effectively integrate external retrieved knowledge with internal parametric knowledge in LLMs. In this work, we propose a novel Self-Selection RAG framework, where the LLM is made to select from pairwise responses generated with internal parametric knowledge solely and with external retrieved knowledge together to achieve enhanced accuracy. To this end, we devise a Self-Selection-RGP method to enhance the capabilities of the LLM in both generating and selecting the correct answer, by training the LLM with Direct Preference Optimization (DPO) over a curated Retrieval Generation Preference (RGP) dataset. Experimental results with two open-source LLMs (i.e., Llama2-13B-Chat and Mistral-7B) well demonstrate the superiority of our approach over other baseline methods on Natural Questions (NQ) and TrivialQA datasets.
Iterative or Innovative? A Problem-Oriented Perspective for Code Optimization
Jun 17, 2024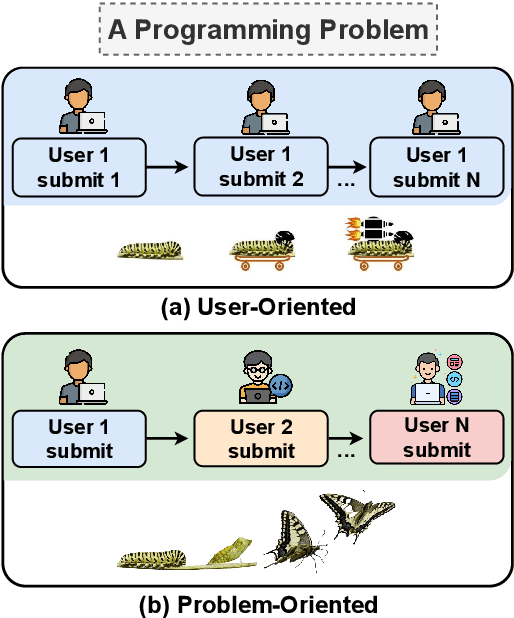



Large language models (LLMs) have demonstrated strong capabilities in solving a wide range of programming tasks. However, LLMs have rarely been explored for code optimization. In this paper, we explore code optimization with a focus on performance enhancement, specifically aiming to optimize code for minimal execution time. The recently proposed first PIE dataset for performance optimization constructs program optimization pairs based on iterative submissions from the same programmer for the same problem. However, this approach restricts LLMs to local performance improvements, neglecting global algorithmic innovation. Therefore, we adopt a completely different perspective by reconstructing the optimization pairs into a problem-oriented approach. This allows for the integration of various ingenious ideas from different programmers tackling the same problem. Experimental results demonstrate that adapting LLMs to problem-oriented optimization pairs significantly enhances their optimization capabilities. Meanwhile, we identified performance bottlenecks within the problem-oriented perspective. By employing model merge, we further overcame bottlenecks and ultimately elevated the program optimization ratio ($51.76\%\rightarrow76.65\%$) and speedup ($2.65\times\rightarrow5.09\times$) to new levels.
Uncovering LLM-Generated Code: A Zero-Shot Synthetic Code Detector via Code Rewriting
May 30, 2024



Large Language Models (LLMs) have exhibited remarkable proficiency in generating code. However, the misuse of LLM-generated (Synthetic) code has prompted concerns within both educational and industrial domains, highlighting the imperative need for the development of synthetic code detectors. Existing methods for detecting LLM-generated content are primarily tailored for general text and often struggle with code content due to the distinct grammatical structure of programming languages and massive "low-entropy" tokens. Building upon this, our work proposes a novel zero-shot synthetic code detector based on the similarity between the code and its rewritten variants. Our method relies on the intuition that the differences between the LLM-rewritten and original codes tend to be smaller when the original code is synthetic. We utilize self-supervised contrastive learning to train a code similarity model and assess our approach on two synthetic code detection benchmarks. Our results demonstrate a notable enhancement over existing synthetic content detectors designed for general texts, with an improvement of 20.5% in the APPS benchmark and 29.1% in the MBPP benchmark.
Quantification of cardiac capillarization in single-immunostained myocardial slices using weakly supervised instance segmentation
Nov 30, 2023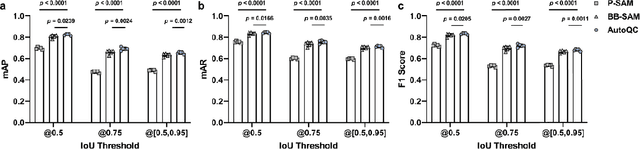



Decreased myocardial capillary density has been reported as an important histopathological feature associated with various heart disorders. Quantitative assessment of cardiac capillarization typically involves double immunostaining of cardiomyocytes (CMs) and capillaries in myocardial slices. In contrast, single immunostaining of basement membrane components is a straightforward approach to simultaneously label CMs and capillaries, presenting fewer challenges in background staining. However, subsequent image analysis always requires manual work in identifying and segmenting CMs and capillaries. Here, we developed an image analysis tool, AutoQC, to automatically identify and segment CMs and capillaries in immunofluorescence images of collagen type IV, a predominant basement membrane protein within the myocardium. In addition, commonly used capillarization-related measurements can be derived from segmentation masks. AutoQC features a weakly supervised instance segmentation algorithm by leveraging the power of a pre-trained segmentation model via prompt engineering. AutoQC outperformed YOLOv8-Seg, a state-of-the-art instance segmentation model, in both instance segmentation and capillarization assessment. Furthermore, the training of AutoQC required only a small dataset with bounding box annotations instead of pixel-wise annotations, leading to a reduced workload during network training. AutoQC provides an automated solution for quantifying cardiac capillarization in basement-membrane-immunostained myocardial slices, eliminating the need for manual image analysis once it is trained.
CP-BCS: Binary Code Summarization Guided by Control Flow Graph and Pseudo Code
Oct 24, 2023Automatically generating function summaries for binaries is an extremely valuable but challenging task, since it involves translating the execution behavior and semantics of the low-level language (assembly code) into human-readable natural language. However, most current works on understanding assembly code are oriented towards generating function names, which involve numerous abbreviations that make them still confusing. To bridge this gap, we focus on generating complete summaries for binary functions, especially for stripped binary (no symbol table and debug information in reality). To fully exploit the semantics of assembly code, we present a control flow graph and pseudo code guided binary code summarization framework called CP-BCS. CP-BCS utilizes a bidirectional instruction-level control flow graph and pseudo code that incorporates expert knowledge to learn the comprehensive binary function execution behavior and logic semantics. We evaluate CP-BCS on 3 different binary optimization levels (O1, O2, and O3) for 3 different computer architectures (X86, X64, and ARM). The evaluation results demonstrate CP-BCS is superior and significantly improves the efficiency of reverse engineering.
Tram: A Token-level Retrieval-augmented Mechanism for Source Code Summarization
May 18, 2023



Automatically generating human-readable text describing the functionality of a program is the intent of source code summarization. Although Neural Language Models achieve significant performance in this field, an emerging trend is combining neural models with external knowledge. Most previous approaches rely on the sentence-level retrieval and combination paradigm (retrieval of similar code snippets and use of the corresponding code and summary pairs) on the encoder side. However, this paradigm is coarse-grained and cannot directly take advantage of the high-quality retrieved summary tokens on the decoder side. In this paper, we explore a fine-grained token-level retrieval-augmented mechanism on the decoder side to help the vanilla neural model generate a better code summary. Furthermore, to mitigate the limitation of token-level retrieval on capturing contextual code semantics, we propose to integrate code semantics into summary tokens. Extensive experiments and human evaluation reveal that our token-level retrieval-augmented approach significantly improves performance and is more interpretive.
On the Calibration and Uncertainty with Pólya-Gamma Augmentation for Dialog Retrieval Models
Mar 15, 2023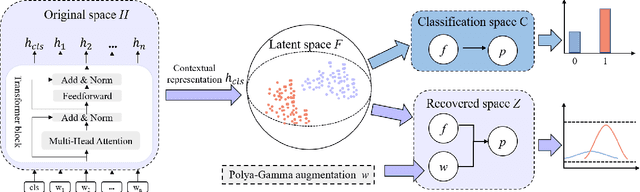
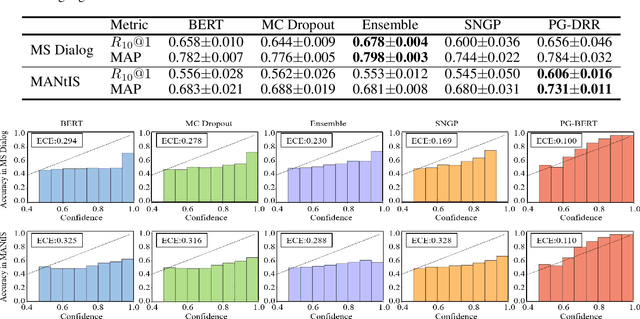


Deep neural retrieval models have amply demonstrated their power but estimating the reliability of their predictions remains challenging. Most dialog response retrieval models output a single score for a response on how relevant it is to a given question. However, the bad calibration of deep neural network results in various uncertainty for the single score such that the unreliable predictions always misinform user decisions. To investigate these issues, we present an efficient calibration and uncertainty estimation framework PG-DRR for dialog response retrieval models which adds a Gaussian Process layer to a deterministic deep neural network and recovers conjugacy for tractable posterior inference by P\'{o}lya-Gamma augmentation. Finally, PG-DRR achieves the lowest empirical calibration error (ECE) in the in-domain datasets and the distributional shift task while keeping $R_{10}@1$ and MAP performance.
Efficient Uncertainty Estimation with Gaussian Process for Reliable Dialog Response Retrieval
Mar 15, 2023
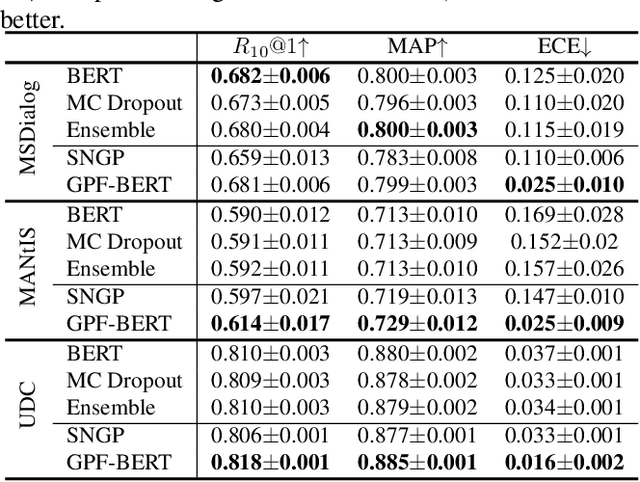


Deep neural networks have achieved remarkable performance in retrieval-based dialogue systems, but they are shown to be ill calibrated. Though basic calibration methods like Monte Carlo Dropout and Ensemble can calibrate well, these methods are time-consuming in the training or inference stages. To tackle these challenges, we propose an efficient uncertainty calibration framework GPF-BERT for BERT-based conversational search, which employs a Gaussian Process layer and the focal loss on top of the BERT architecture to achieve a high-quality neural ranker. Extensive experiments are conducted to verify the effectiveness of our method. In comparison with basic calibration methods, GPF-BERT achieves the lowest empirical calibration error (ECE) in three in-domain datasets and the distributional shift tasks, while yielding the highest $R_{10}@1$ and MAP performance on most cases. In terms of time consumption, our GPF-BERT has an 8$\times$ speedup.