 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Whole-Body Dancing with Humanoid Robots -- A Model-Based Control Approach
Apr 05, 2026This paper presents an integrated model-based framework for generating and executing dynamic whole-body dance motions on humanoid robots. The framework operates in two stages: offline motion generation and online motion execution, both leveraging future state prediction to enable robust and dynamic dance motions in real-world environments. In the offline motion generation stage, human dance demonstrations are captured via a motion capture (MoCap) system, retargeted to the robot by solving a Quadratic Programming (QP) problem, and further refined using Trajectory Optimization (TO) to ensure dynamic feasibility. In the online motion execution stage, a centroidal dynamics-based Model Predictive Control (MPC) framework tracks the planned motions in real time and proactively adjusts swing foot placement to adapt to real world disturbances. We validate our framework on the full-size humanoid robot Kuavo 4Pro, demonstrating the dynamic dance motions both in simulation and in a four-minute live public performance with a team of four robots. Experimental results show that longer prediction horizons improve both motion expressiveness in planning and stability in execution.
Multimodal Mixture-of-Experts with Retrieval Augmentation for Protein Active Site Identification
Mar 02, 2026Accurate identification of protein active sites at the residue level is crucial for understanding protein function and advancing drug discovery. However, current methods face two critical challenges: vulnerability in single-instance prediction due to sparse training data, and inadequate modality reliability estimation that leads to performance degradation when unreliable modalities dominate fusion processes. To address these challenges, we introduce Multimodal Mixture-of-Experts with Retrieval Augmentation (MERA), the first retrieval-augmented framework for protein active site identification. MERA employs hierarchical multi-expert retrieval that dynamically aggregates contextual information from chain, sequence, and active-site perspectives through residue-level mixture-of-experts gating. To prevent modality degradation, we propose a reliability-aware fusion strategy based on Dempster-Shafer evidence theory that quantifies modality trustworthiness through belief mass functions and learnable discounting coefficients, enabling principled multimodal integration. Extensive experiments on ProTAD-Gen and TS125 datasets demonstrate that MERA achieves state-of-the-art performance, with 90% AUPRC on active site prediction and significant gains on peptide-binding site identification, validating the effectiveness of retrieval-augmented multi-expert modeling and reliability-guided fusion.
ECO: Energy-Constrained Optimization with Reinforcement Learning for Humanoid Walking
Feb 06, 2026Achieving stable and energy-efficient locomotion is essential for humanoid robots to operate continuously in real-world applications. Existing MPC and RL approaches often rely on energy-related metrics embedded within a multi-objective optimization framework, which require extensive hyperparameter tuning and often result in suboptimal policies. To address these challenges, we propose ECO (Energy-Constrained Optimization), a constrained RL framework that separates energy-related metrics from rewards, reformulating them as explicit inequality constraints. This method provides a clear and interpretable physical representation of energy costs, enabling more efficient and intuitive hyperparameter tuning for improved energy efficiency. ECO introduces dedicated constraints for energy consumption and reference motion, enforced by the Lagrangian method, to achieve stable, symmetric, and energy-efficient walking for humanoid robots. We evaluated ECO against MPC, standard RL with reward shaping, and four state-of-the-art constrained RL methods. Experiments, including sim-to-sim and sim-to-real transfers on the kid-sized humanoid robot BRUCE, demonstrate that ECO significantly reduces energy consumption compared to baselines while maintaining robust walking performance. These results highlight a substantial advancement in energy-efficient humanoid locomotion. All experimental demonstrations can be found on the project website: https://sites.google.com/view/eco-humanoid.
Graph Diffusion Network for Drug-Gene Prediction
Feb 13, 2025


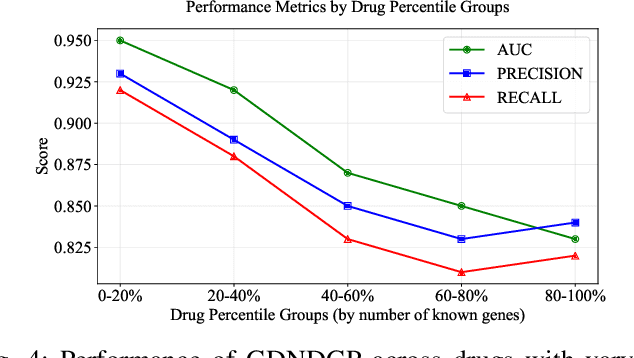
Predicting drug-gene associations is crucial for drug development and disease treatment. While graph neural networks (GNN) have shown effectiveness in this task, they face challenges with data sparsity and efficient contrastive learning implementation. We introduce a graph diffusion network for drug-gene prediction (GDNDGP), a framework that addresses these limitations through two key innovations. First, it employs meta-path-based homogeneous graph learning to capture drug-drug and gene-gene relationships, ensuring similar entities share embedding spaces. Second, it incorporates a parallel diffusion network that generates hard negative samples during training, eliminating the need for exhaustive negative sample retrieval. Our model achieves superior performance on the DGIdb 4.0 dataset and demonstrates strong generalization capability on tripartite drug-gene-disease networks. Results show significant improvements over existing methods in drug-gene prediction tasks, particularly in handling complex heterogeneous relationships. The source code is publicly available at https://github.com/csjywu1/GDNDGP.
ADKGD: Anomaly Detection in Knowledge Graphs with Dual-Channel Training
Jan 13, 2025
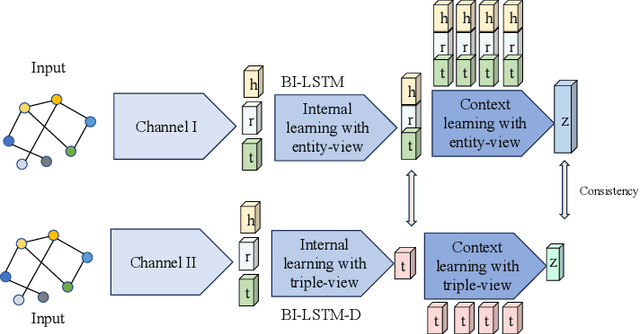

In the current development of large language models (LLMs), it is important to ensure the accuracy and reliability of the underlying data sources. LLMs are critical for various applications, but they often suffer from hallucinations and inaccuracies due to knowledge gaps in the training data. Knowledge graphs (KGs), as a powerful structural tool, could serve as a vital external information source to mitigate the aforementioned issues. By providing a structured and comprehensive understanding of real-world data, KGs enhance the performance and reliability of LLMs. However, it is common that errors exist in KGs while extracting triplets from unstructured data to construct KGs. This could lead to degraded performance in downstream tasks such as question-answering and recommender systems. Therefore, anomaly detection in KGs is essential to identify and correct these errors. This paper presents an anomaly detection algorithm in knowledge graphs with dual-channel learning (ADKGD). ADKGD leverages a dual-channel learning approach to enhance representation learning from both the entity-view and triplet-view perspectives. Furthermore, using a cross-layer approach, our framework integrates internal information aggregation and context information aggregation. We introduce a kullback-leibler (KL)-loss component to improve the accuracy of the scoring function between the dual channels. To evaluate ADKGD's performance, we conduct empirical studies on three real-world KGs: WN18RR, FB15K, and NELL-995. Experimental results demonstrate that ADKGD outperforms the state-of-the-art anomaly detection algorithms. The source code and datasets are publicly available at https://github.com/csjywu1/ADKGD.
Graph Contrastive Learning on Multi-label Classification for Recommendations
Jan 13, 2025



In business analysis, providing effective recommendations is essential for enhancing company profits. The utilization of graph-based structures, such as bipartite graphs, has gained popularity for their ability to analyze complex data relationships. Link prediction is crucial for recommending specific items to users. Traditional methods in this area often involve identifying patterns in the graph structure or using representational techniques like graph neural networks (GNNs). However, these approaches encounter difficulties as the volume of data increases. To address these challenges, we propose a model called Graph Contrastive Learning for Multi-label Classification (MCGCL). MCGCL leverages contrastive learning to enhance recommendation effectiveness. The model incorporates two training stages: a main task and a subtask. The main task is holistic user-item graph learning to capture user-item relationships. The homogeneous user-user (item-item) subgraph is constructed to capture user-user and item-item relationships in the subtask. We assessed the performance using real-world datasets from Amazon Reviews in multi-label classification tasks. Comparative experiments with state-of-the-art methods confirm the effectiveness of MCGCL, highlighting its potential for improving recommendation systems.
CDM-MPC: An Integrated Dynamic Planning and Control Framework for Bipedal Robots Jumping
May 20, 2024



Performing acrobatic maneuvers like dynamic jumping in bipedal robots presents significant challenges in terms of actuation, motion planning, and control. Traditional approaches to these tasks often simplify dynamics to enhance computational efficiency, potentially overlooking critical factors such as the control of centroidal angular momentum (CAM) and the variability of centroidal composite rigid body inertia (CCRBI). This paper introduces a novel integrated dynamic planning and control framework, termed centroidal dynamics model-based model predictive control (CDM-MPC), designed for robust jumping control that fully considers centroidal momentum and non-constant CCRBI. The framework comprises an optimization-based kinodynamic motion planner and an MPC controller for real-time trajectory tracking and replanning. Additionally, a centroidal momentum-based inverse kinematics (IK) solver and a landing heuristic controller are developed to ensure stability during high-impact landings. The efficacy of the CDM-MPC framework is validated through extensive testing on the full-sized humanoid robot KUAVO in both simulations and experiments.
Data Scarcity in Recommendation Systems: A Survey
Dec 08, 2023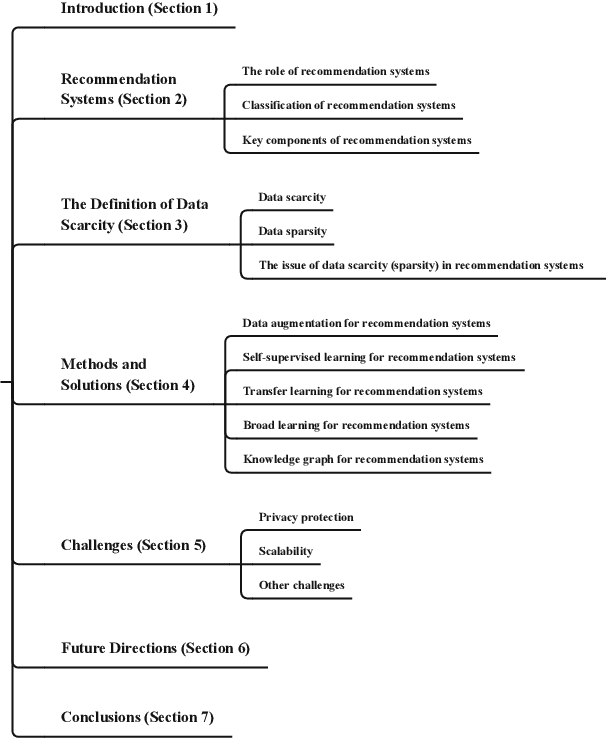
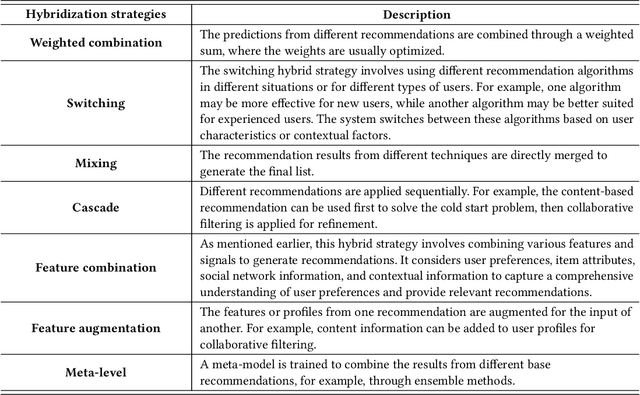
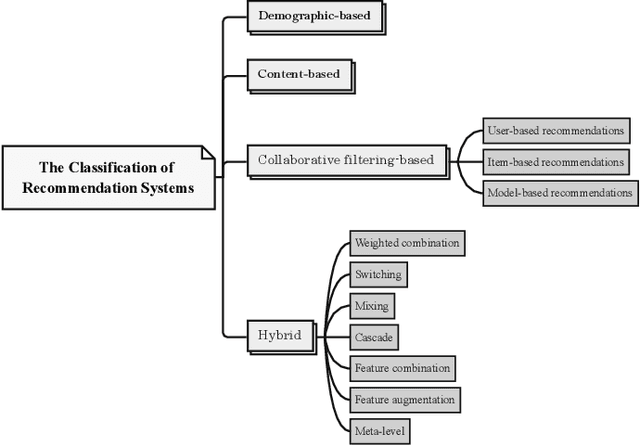
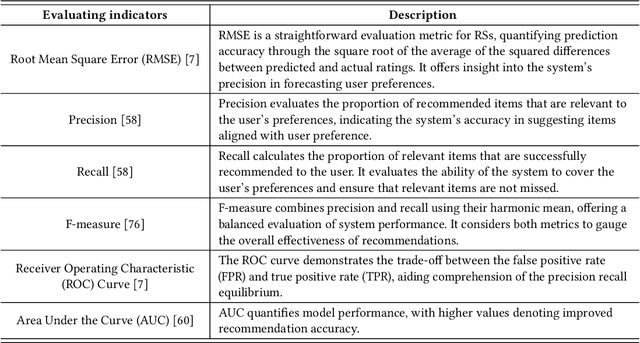
The prevalence of online content has led to the widespread adoption of recommendation systems (RSs), which serve diverse purposes such as news, advertisements, and e-commerce recommendations. Despite their significance, data scarcity issues have significantly impaired the effectiveness of existing RS models and hindered their progress. To address this challenge, the concept of knowledge transfer, particularly from external sources like pre-trained language models, emerges as a potential solution to alleviate data scarcity and enhance RS development. However, the practice of knowledge transfer in RSs is intricate. Transferring knowledge between domains introduces data disparities, and the application of knowledge transfer in complex RS scenarios can yield negative consequences if not carefully designed. Therefore, this article contributes to this discourse by addressing the implications of data scarcity on RSs and introducing various strategies, such as data augmentation, self-supervised learning, transfer learning, broad learning, and knowledge graph utilization, to mitigate this challenge. Furthermore, it delves into the challenges and future direction within the RS domain, offering insights that are poised to facilitate the development and implementation of robust RSs, particularly when confronted with data scarcity. We aim to provide valuable guidance and inspiration for researchers and practitioners, ultimately driving advancements in the field of RS.
Large Language Models in Law: A Survey
Nov 26, 2023The advent of artificial intelligence (AI) has significantly impacted the traditional judicial industry. Moreover, recently, with the development of AI-generated content (AIGC), AI and law have found applications in various domains, including image recognition, automatic text generation, and interactive chat. With the rapid emergence and growing popularity of large models, it is evident that AI will drive transformation in the traditional judicial industry. However, the application of legal large language models (LLMs) is still in its nascent stage. Several challenges need to be addressed. In this paper, we aim to provide a comprehensive survey of legal LLMs. We not only conduct an extensive survey of LLMs, but also expose their applications in the judicial system. We first provide an overview of AI technologies in the legal field and showcase the recent research in LLMs. Then, we discuss the practical implementation presented by legal LLMs, such as providing legal advice to users and assisting judges during trials. In addition, we explore the limitations of legal LLMs, including data, algorithms, and judicial practice. Finally, we summarize practical recommendations and propose future development directions to address these challenges.
Large Language Models in Education: Vision and Opportunities
Nov 22, 2023


With the rapid development of artificial intelligence technology, large language models (LLMs) have become a hot research topic. Education plays an important role in human social development and progress. Traditional education faces challenges such as individual student differences, insufficient allocation of teaching resources, and assessment of teaching effectiveness. Therefore, the applications of LLMs in the field of digital/smart education have broad prospects. The research on educational large models (EduLLMs) is constantly evolving, providing new methods and approaches to achieve personalized learning, intelligent tutoring, and educational assessment goals, thereby improving the quality of education and the learning experience. This article aims to investigate and summarize the application of LLMs in smart education. It first introduces the research background and motivation of LLMs and explains the essence of LLMs. It then discusses the relationship between digital education and EduLLMs and summarizes the current research status of educational large models. The main contributions are the systematic summary and vision of the research background, motivation, and application of large models for education (LLM4Edu). By reviewing existing research, this article provides guidance and insights for educators, researchers, and policy-makers to gain a deep understanding of the potential and challenges of LLM4Edu. It further provides guidance for further advancing the development and application of LLM4Edu, while still facing technical, ethical, and practical challenges requiring further research and exploration.