 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Scarcity in Recommendation Systems: A Survey
Dec 08, 2023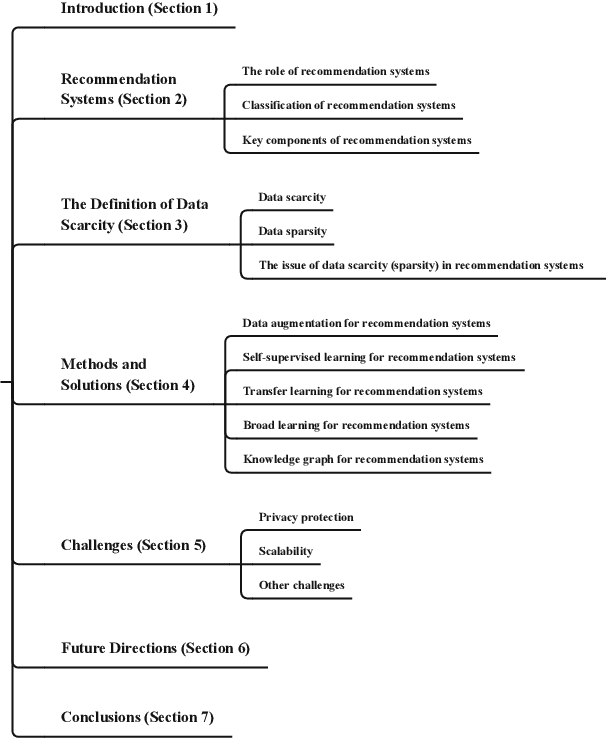
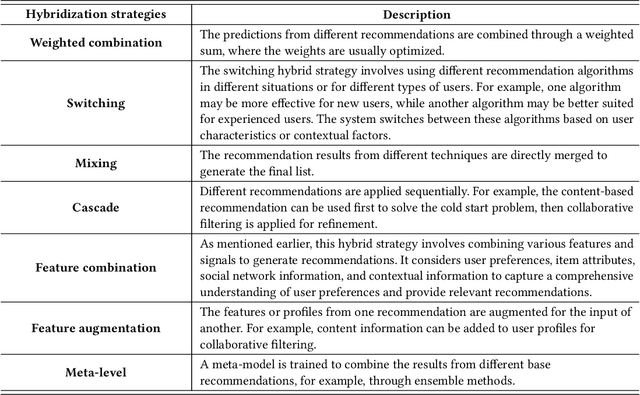
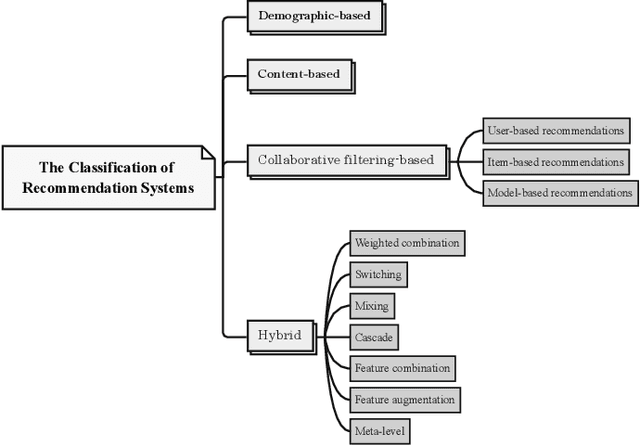
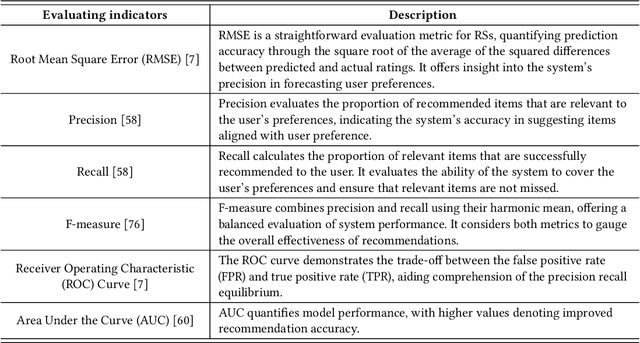
The prevalence of online content has led to the widespread adoption of recommendation systems (RSs), which serve diverse purposes such as news, advertisements, and e-commerce recommendations. Despite their significance, data scarcity issues have significantly impaired the effectiveness of existing RS models and hindered their progress. To address this challenge, the concept of knowledge transfer, particularly from external sources like pre-trained language models, emerges as a potential solution to alleviate data scarcity and enhance RS development. However, the practice of knowledge transfer in RSs is intricate. Transferring knowledge between domains introduces data disparities, and the application of knowledge transfer in complex RS scenarios can yield negative consequences if not carefully designed. Therefore, this article contributes to this discourse by addressing the implications of data scarcity on RSs and introducing various strategies, such as data augmentation, self-supervised learning, transfer learning, broad learning, and knowledge graph utilization, to mitigate this challenge. Furthermore, it delves into the challenges and future direction within the RS domain, offering insights that are poised to facilitate the development and implementation of robust RSs, particularly when confronted with data scarcity. We aim to provide valuable guidance and inspiration for researchers and practitioners, ultimately driving advancements in the field of RS.