 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Statistics for Generative Image Detection
Oct 25, 2023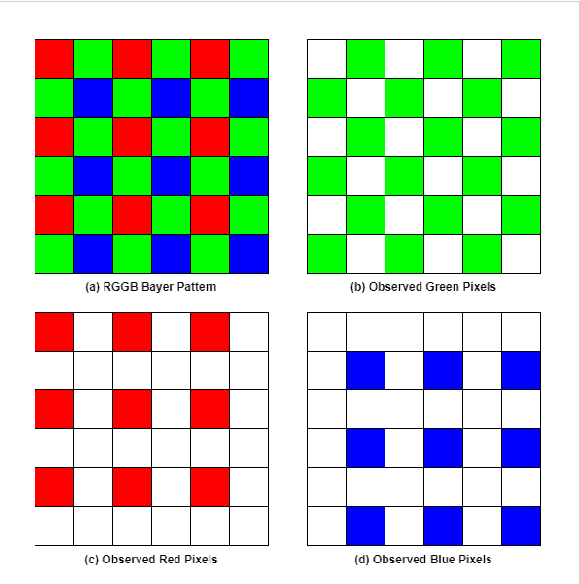
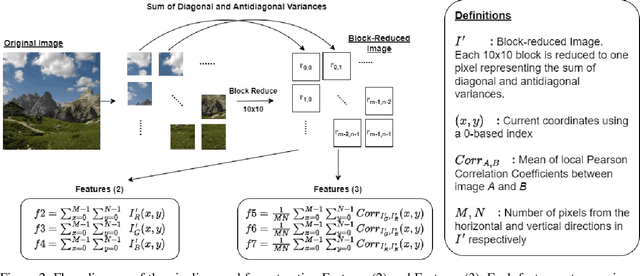
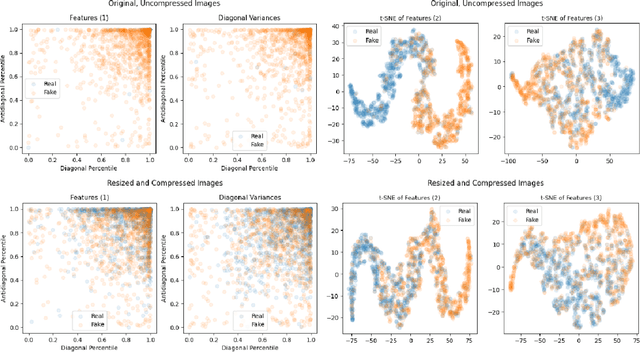
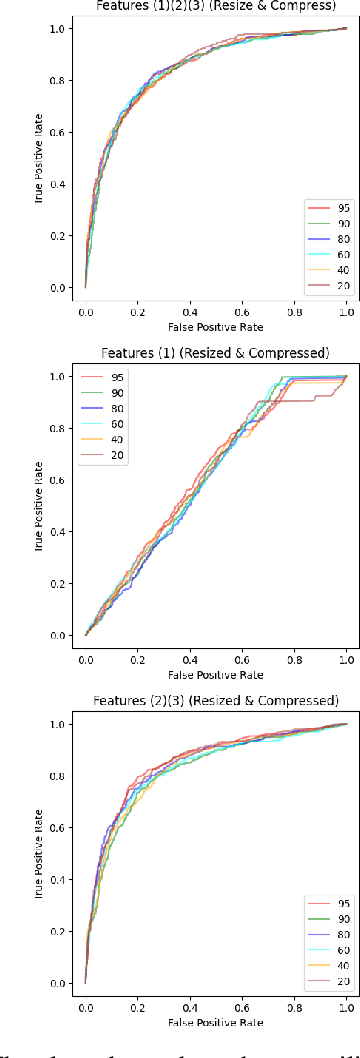
Diffusion models (DMs) are generative models that learn to synthesize images from Gaussian noise. DMs can be trained to do a variety of tasks such as image generation and image super-resolution. Researchers have made significant improvement in the capability of synthesizing photorealistic images in the past few years. These successes also hasten the need to address the potential misuse of synthesized images. In this paper, we highlight the effectiveness of computing local statistics, as opposed to global statistics, in distinguishing digital camera images from DM-generated images. We hypothesized that local statistics should be used to address the spatial non-stationarity problem in images. We show that our approach produced promising results and it is also robust to various perturbations such as image resizing and JPEG compression.
Mugs: A Multi-Granular Self-Supervised Learning Framework
Mar 27, 2022
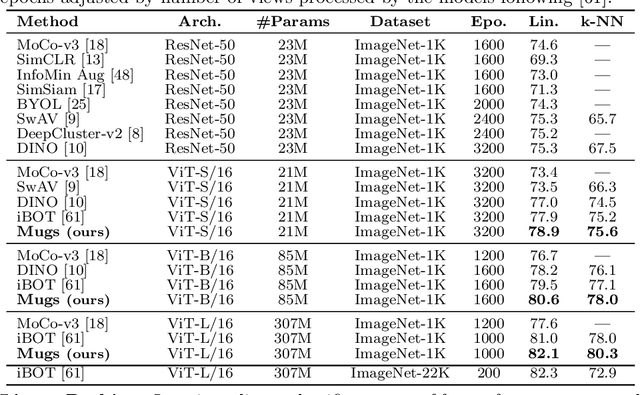
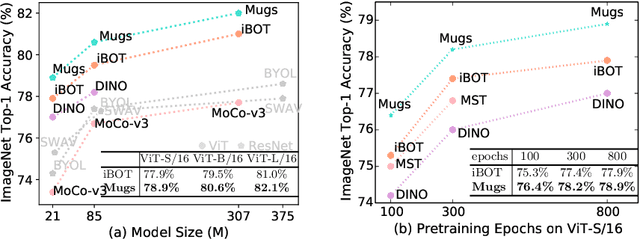
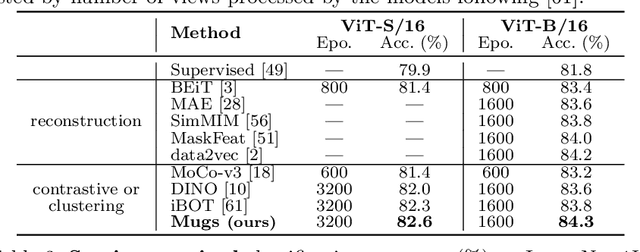
In self-supervised learning, multi-granular features are heavily desired though rarely investigated, as different downstream tasks (e.g., general and fine-grained classification) often require different or multi-granular features, e.g.~fine- or coarse-grained one or their mixture. In this work, for the first time, we propose an effective MUlti-Granular Self-supervised learning (Mugs) framework to explicitly learn multi-granular visual features. Mugs has three complementary granular supervisions: 1) an instance discrimination supervision (IDS), 2) a novel local-group discrimination supervision (LGDS), and 3) a group discrimination supervision (GDS). IDS distinguishes different instances to learn instance-level fine-grained features. LGDS aggregates features of an image and its neighbors into a local-group feature, and pulls local-group features from different crops of the same image together and push them away for others. It provides complementary instance supervision to IDS via an extra alignment on local neighbors, and scatters different local-groups separately to increase discriminability. Accordingly, it helps learn high-level fine-grained features at a local-group level. Finally, to prevent similar local-groups from being scattered randomly or far away, GDS brings similar samples close and thus pulls similar local-groups together, capturing coarse-grained features at a (semantic) group level. Consequently, Mugs can capture three granular features that often enjoy higher generality on diverse downstream tasks over single-granular features, e.g.~instance-level fine-grained features in contrastive learning. By only pretraining on ImageNet-1K, Mugs sets new SoTA linear probing accuracy 82.1$\%$ on ImageNet-1K and improves previous SoTA by $1.1\%$. It also surpasses SoTAs on other tasks, e.g. transfer learning, detection and segmentation.
Adaptive Modeling Against Adversarial Attacks
Dec 23, 2021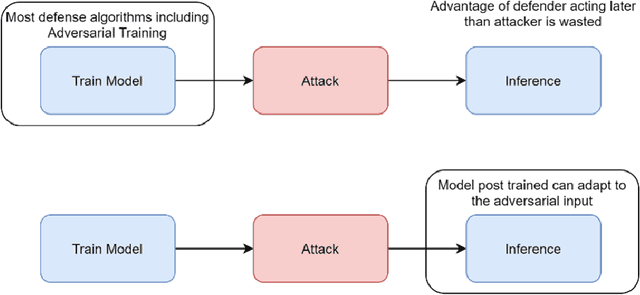

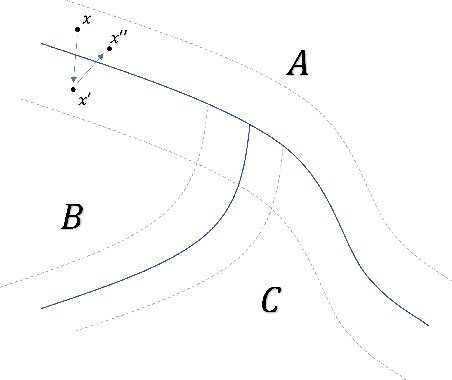
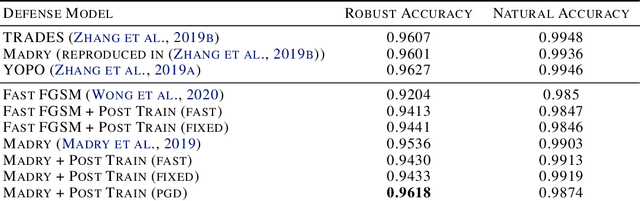
Adversarial training, the process of training a deep learning model with adversarial data, is one of the most successful adversarial defense methods for deep learning models. We have found that the robustness to white-box attack of an adversarially trained model can be further improved if we fine tune this model in inference stage to adapt to the adversarial input, with the extra information in it. We introduce an algorithm that "post trains" the model at inference stage between the original output class and a "neighbor" class, with existing training data. The accuracy of pre-trained Fast-FGSM CIFAR10 classifier base model against white-box projected gradient attack (PGD) can be significantly improved from 46.8% to 64.5% with our algorithm.
SINGA-Easy: An Easy-to-Use Framework for MultiModal Analysis
Aug 03, 2021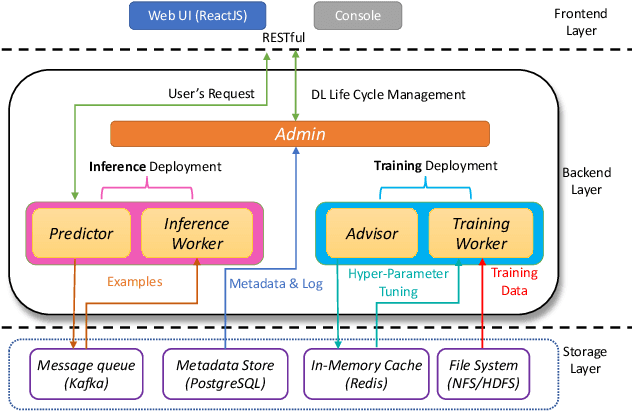

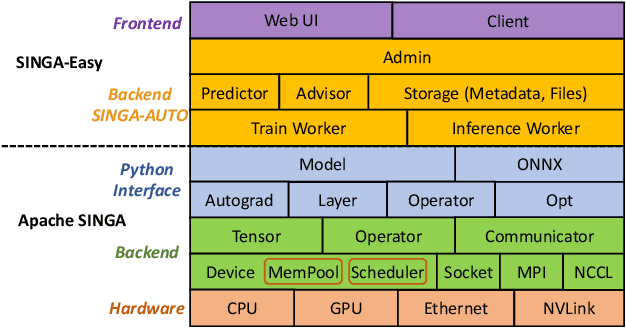

Deep learning has achieved great success in a wide spectrum of multimedia applications such as image classification, natural language processing and multimodal data analysis. Recent years have seen the development of many deep learning frameworks that provide a high-level programming interface for users to design models, conduct training and deploy inference. However, it remains challenging to build an efficient end-to-end multimedia application with most existing frameworks. Specifically, in terms of usability, it is demanding for non-experts to implement deep learning models, obtain the right settings for the entire machine learning pipeline, manage models and datasets, and exploit external data sources all together. Further, in terms of adaptability, elastic computation solutions are much needed as the actual serving workload fluctuates constantly, and scaling the hardware resources to handle the fluctuating workload is typically infeasible. To address these challenges, we introduce SINGA-Easy, a new deep learning framework that provides distributed hyper-parameter tuning at the training stage, dynamic computational cost control at the inference stage, and intuitive user interactions with multimedia contents facilitated by model explanation. Our experiments on the training and deployment of multi-modality data analysis applications show that the framework is both usable and adaptable to dynamic inference loads. We implement SINGA-Easy on top of Apache SINGA and demonstrate our system with the entire machine learning life cycle.
Enhancing Transformation-based Defenses using a Distribution Classifier
Jun 01, 2019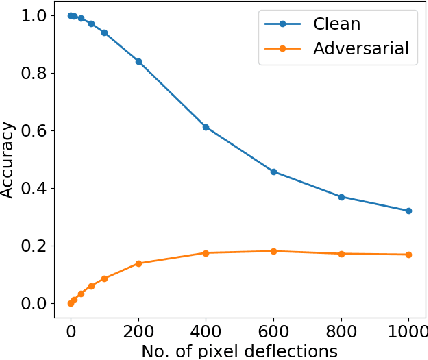
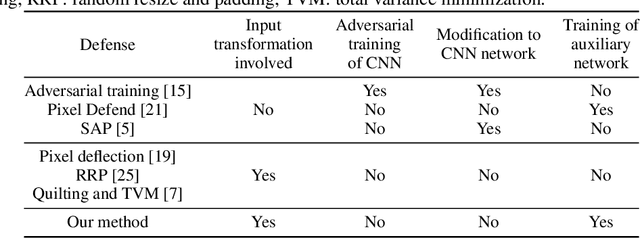
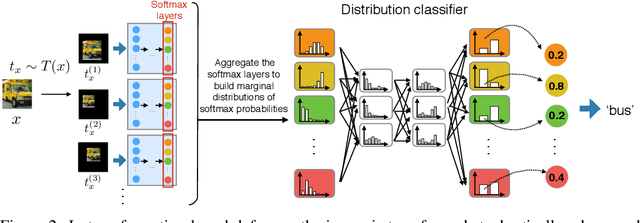
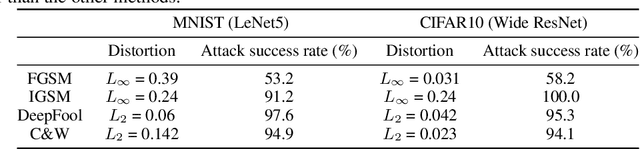
Adversarial attacks on convolutional neural networks (CNN) have gained significant attention and research efforts have focused on defense methods that make the classifiers more robust. Stochastic input transformation methods have been proposed, where the idea is to randomly transform the input images to try to recover from the adversarial attacks. While these transformation-based methods have shown considerable success at recovering from adversarial images, the performance on clean images deteriorates as the magnitude of the transformation increases. In this paper, we propose a defense mechanism that can be integrated with existing transformation-based defenses and reduce the deterioration of performance on clean images. Exploiting the fact that the transformation methods are stochastic, our method samples a population of transformed images and performs the final classification on distributions of softmax probabilities. We train a separate compact distribution classifier to recognize distinctive features in the distributions of softmax probabilities of transformed clean images. Without retraining the original CNN, our distribution classifier improves the performance of transformation-based defenses on both clean and adversarial images, even though the distribution classifier was never trained on distributions obtained from the adversarial images. Our method is generic and can be integrated with existing transformation-based methods.
An Efficient Network for Predicting Time-Varying Distributions
Nov 05, 2018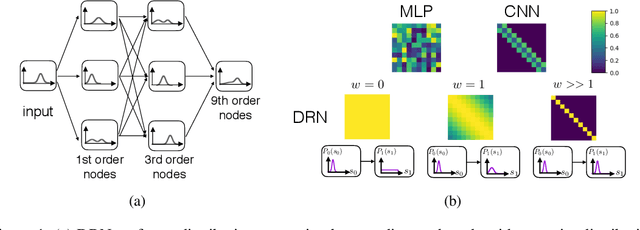
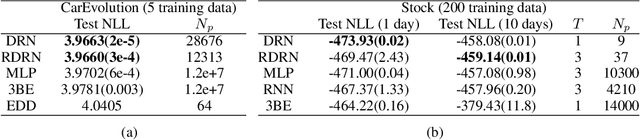
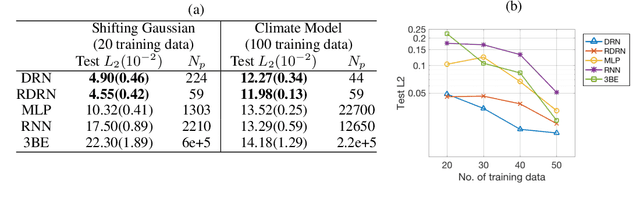

While deep neural networks have achieved groundbreaking prediction results in many tasks, there is a class of data where existing architectures are not optimal -- sequences of probability distributions. Performing forward prediction on sequences of distributions has many important applications. However, there are two main challenges in designing a network model for this task. First, neural networks are unable to encode distributions compactly as each node encodes just a real value. A recent work of Distribution Regression Network (DRN) solved this problem with a novel network that encodes an entire distribution in a single node, resulting in improved accuracies while using much fewer parameters than neural networks. However, despite its compact distribution representation, DRN does not address the second challenge, which is the need to model time dependencies in a sequence of distributions. In this paper, we propose our Recurrent Distribution Regression Network (RDRN) which adopts a recurrent architecture for DRN. The combination of compact distribution representation and shared weights architecture across time steps makes RDRN suitable for modeling the time dependencies in a distribution sequence. Compared to neural networks and DRN, RDRN achieves the best prediction performance while keeping the network compact.
A Compact Network Learning Model for Distribution Regression
Jul 10, 2018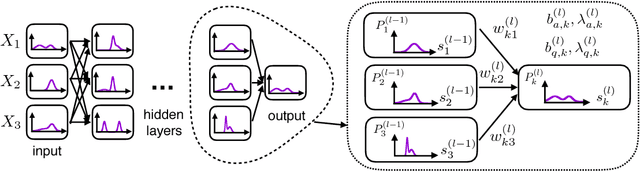
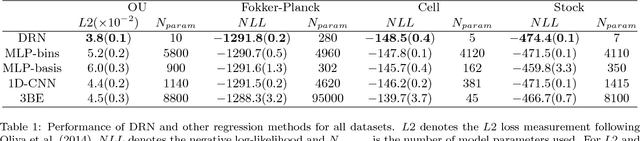
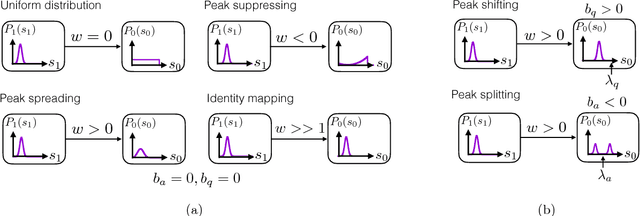
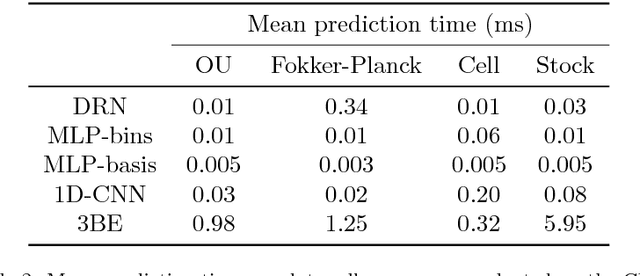
Despite the superior performance of deep learning in many applications, challenges remain in the area of regression on function spaces. In particular, neural networks are unable to encode function inputs compactly as each node encodes just a real value. We propose a novel idea to address this shortcoming: to encode an entire function in a single network node. To that end, we design a compact network representation that encodes and propagates functions in single nodes for the distribution regression task. Our proposed Distribution Regression Network (DRN) achieves higher prediction accuracies while being much more compact and uses fewer parameters than traditional neural networks.
PANDA: Facilitating Usable AI Development
Apr 26, 2018
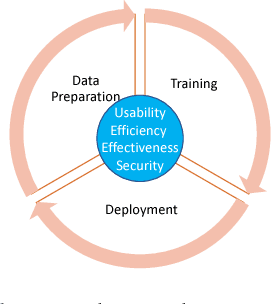
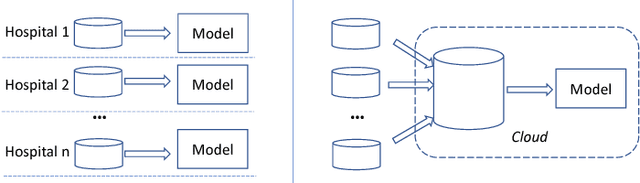
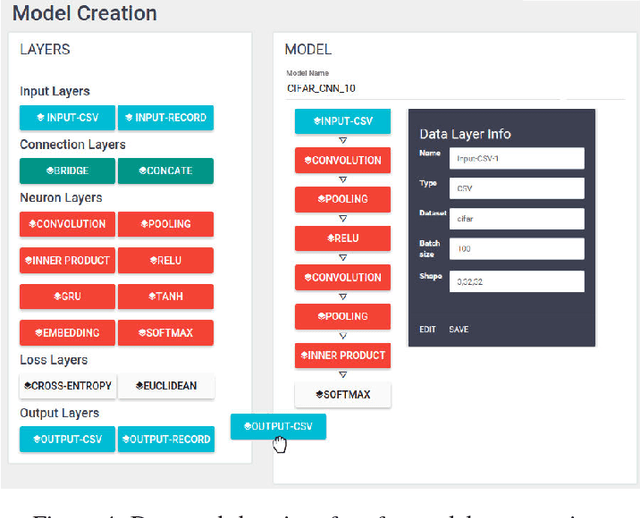
Recent advances in artificial intelligence (AI) and machine learning have created a general perception that AI could be used to solve complex problems, and in some situations over-hyped as a tool that can be so easily used. Unfortunately, the barrier to realization of mass adoption of AI on various business domains is too high because most domain experts have no background in AI. Developing AI applications involves multiple phases, namely data preparation, application modeling, and product deployment. The effort of AI research has been spent mostly on new AI models (in the model training stage) to improve the performance of benchmark tasks such as image recognition. Many other factors such as usability, efficiency and security of AI have not been well addressed, and therefore form a barrier to democratizing AI. Further, for many real world applications such as healthcare and autonomous driving, learning via huge amounts of possibility exploration is not feasible since humans are involved. In many complex applications such as healthcare, subject matter experts (e.g. Clinicians) are the ones who appreciate the importance of features that affect health, and their knowledge together with existing knowledge bases are critical to the end results. In this paper, we take a new perspective on developing AI solutions, and present a solution for making AI usable. We hope that this resolution will enable all subject matter experts (eg. Clinicians) to exploit AI like data scientists.
Rafiki: Machine Learning as an Analytics Service System
Apr 17, 2018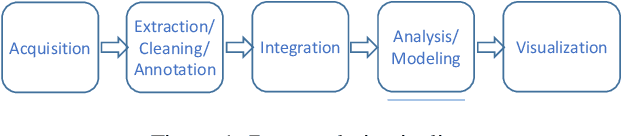
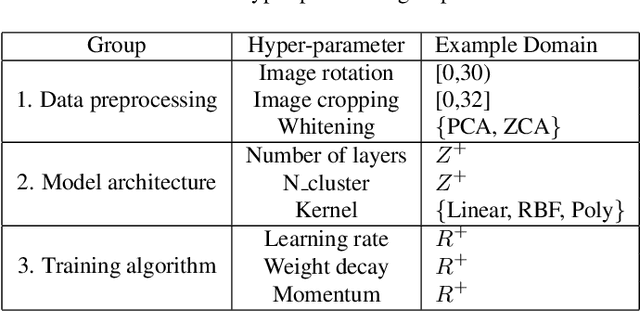
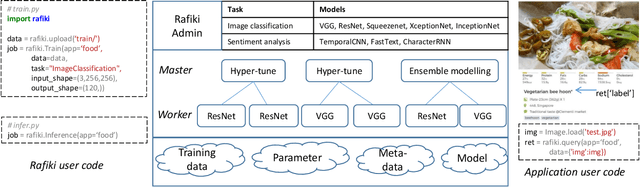

Big data analytics is gaining massive momentum in the last few years. Applying machine learning models to big data has become an implicit requirement or an expectation for most analysis tasks, especially on high-stakes applications.Typical applications include sentiment analysis against reviews for analyzing on-line products, image classification in food logging applications for monitoring user's daily intake and stock movement prediction. Extending traditional database systems to support the above analysis is intriguing but challenging. First, it is almost impossible to implement all machine learning models in the database engines. Second, expertise knowledge is required to optimize the training and inference procedures in terms of efficiency and effectiveness, which imposes heavy burden on the system users. In this paper, we develop and present a system, called Rafiki, to provide the training and inference service of machine learning models, and facilitate complex analytics on top of cloud platforms. Rafiki provides distributed hyper-parameter tuning for the training service, and online ensemble modeling for the inference service which trades off between latency and accuracy. Experimental results confirm the efficiency, effectiveness, scalability and usability of Rafiki.