 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Transformation-based Defenses using a Distribution Classifier
Jun 01, 2019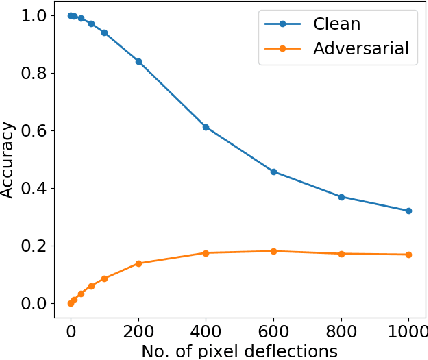
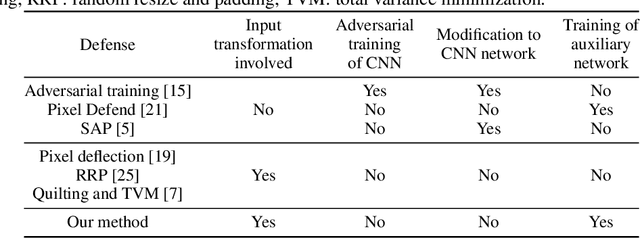
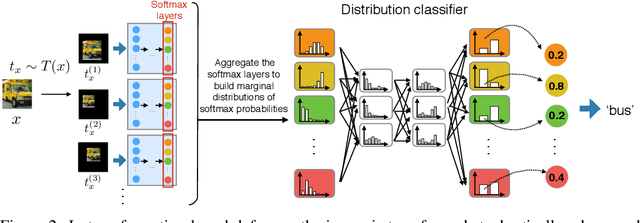
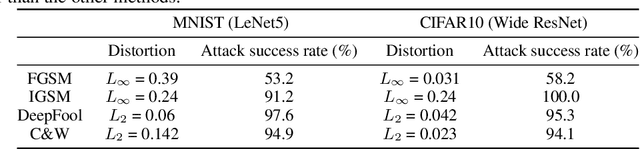
Adversarial attacks on convolutional neural networks (CNN) have gained significant attention and research efforts have focused on defense methods that make the classifiers more robust. Stochastic input transformation methods have been proposed, where the idea is to randomly transform the input images to try to recover from the adversarial attacks. While these transformation-based methods have shown considerable success at recovering from adversarial images, the performance on clean images deteriorates as the magnitude of the transformation increases. In this paper, we propose a defense mechanism that can be integrated with existing transformation-based defenses and reduce the deterioration of performance on clean images. Exploiting the fact that the transformation methods are stochastic, our method samples a population of transformed images and performs the final classification on distributions of softmax probabilities. We train a separate compact distribution classifier to recognize distinctive features in the distributions of softmax probabilities of transformed clean images. Without retraining the original CNN, our distribution classifier improves the performance of transformation-based defenses on both clean and adversarial images, even though the distribution classifier was never trained on distributions obtained from the adversarial images. Our method is generic and can be integrated with existing transformation-based methods.
An Efficient Network for Predicting Time-Varying Distributions
Nov 05, 2018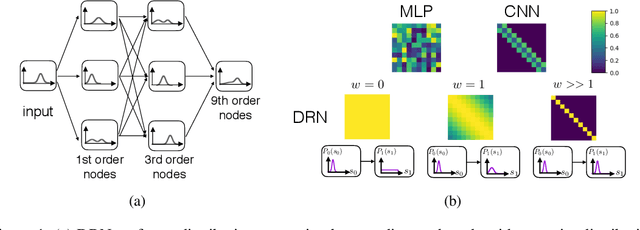
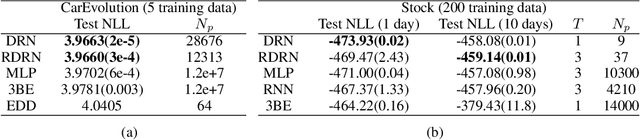
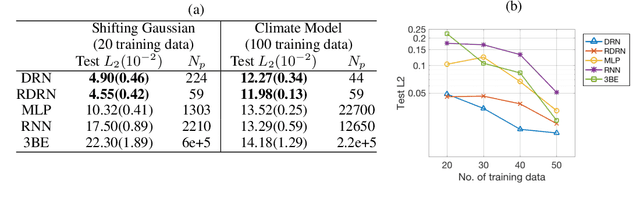

While deep neural networks have achieved groundbreaking prediction results in many tasks, there is a class of data where existing architectures are not optimal -- sequences of probability distributions. Performing forward prediction on sequences of distributions has many important applications. However, there are two main challenges in designing a network model for this task. First, neural networks are unable to encode distributions compactly as each node encodes just a real value. A recent work of Distribution Regression Network (DRN) solved this problem with a novel network that encodes an entire distribution in a single node, resulting in improved accuracies while using much fewer parameters than neural networks. However, despite its compact distribution representation, DRN does not address the second challenge, which is the need to model time dependencies in a sequence of distributions. In this paper, we propose our Recurrent Distribution Regression Network (RDRN) which adopts a recurrent architecture for DRN. The combination of compact distribution representation and shared weights architecture across time steps makes RDRN suitable for modeling the time dependencies in a distribution sequence. Compared to neural networks and DRN, RDRN achieves the best prediction performance while keeping the network compact.
A Compact Network Learning Model for Distribution Regression
Jul 10, 2018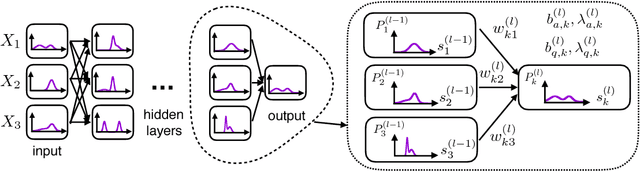
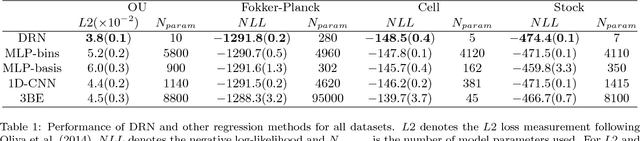
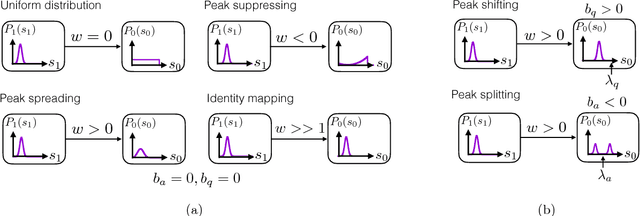
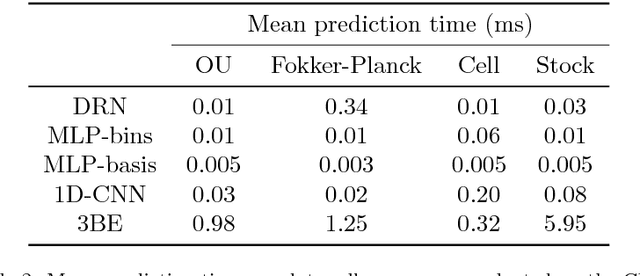
Despite the superior performance of deep learning in many applications, challenges remain in the area of regression on function spaces. In particular, neural networks are unable to encode function inputs compactly as each node encodes just a real value. We propose a novel idea to address this shortcoming: to encode an entire function in a single network node. To that end, we design a compact network representation that encodes and propagates functions in single nodes for the distribution regression task. Our proposed Distribution Regression Network (DRN) achieves higher prediction accuracies while being much more compact and uses fewer parameters than traditional neural networks.