 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSINGA-Easy: An Easy-to-Use Framework for MultiModal Analysis
Aug 03, 2021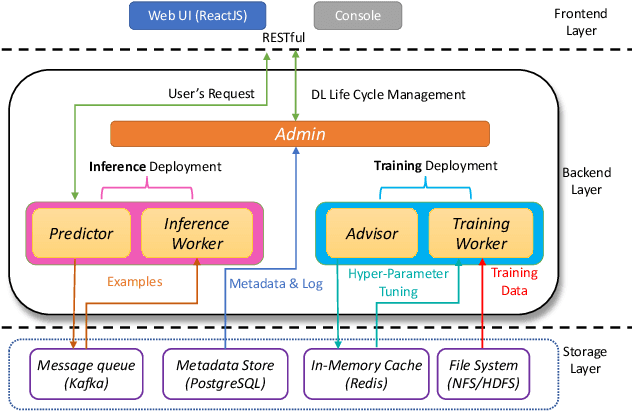

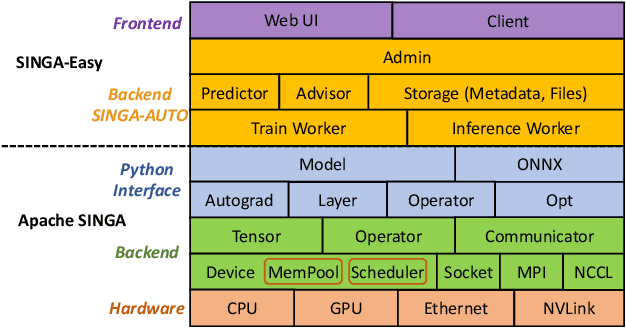

Deep learning has achieved great success in a wide spectrum of multimedia applications such as image classification, natural language processing and multimodal data analysis. Recent years have seen the development of many deep learning frameworks that provide a high-level programming interface for users to design models, conduct training and deploy inference. However, it remains challenging to build an efficient end-to-end multimedia application with most existing frameworks. Specifically, in terms of usability, it is demanding for non-experts to implement deep learning models, obtain the right settings for the entire machine learning pipeline, manage models and datasets, and exploit external data sources all together. Further, in terms of adaptability, elastic computation solutions are much needed as the actual serving workload fluctuates constantly, and scaling the hardware resources to handle the fluctuating workload is typically infeasible. To address these challenges, we introduce SINGA-Easy, a new deep learning framework that provides distributed hyper-parameter tuning at the training stage, dynamic computational cost control at the inference stage, and intuitive user interactions with multimedia contents facilitated by model explanation. Our experiments on the training and deployment of multi-modality data analysis applications show that the framework is both usable and adaptable to dynamic inference loads. We implement SINGA-Easy on top of Apache SINGA and demonstrate our system with the entire machine learning life cycle.
MLCask: Efficient Management of Component Evolution in Collaborative Data Analytics Pipelines
Oct 17, 2020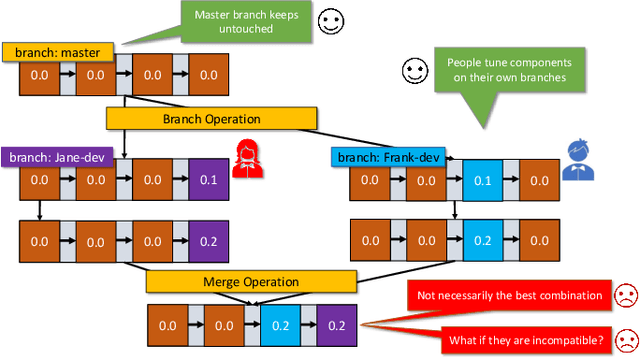
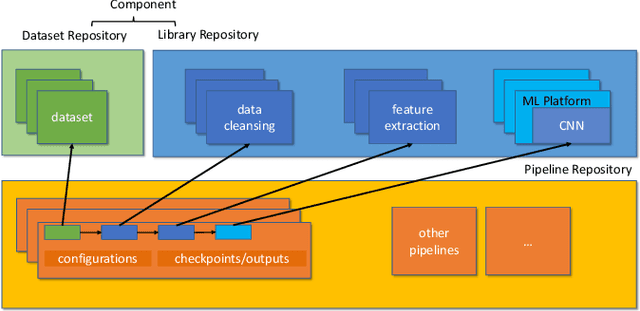
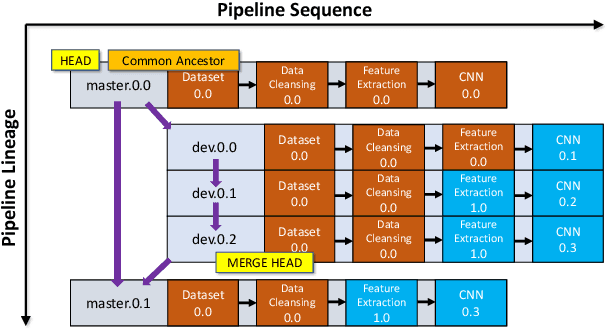
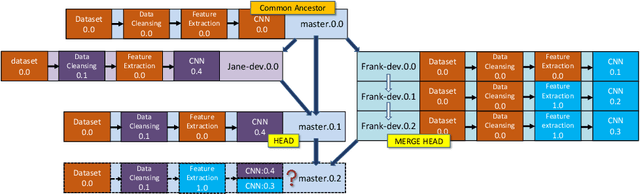
With the ever-increasing adoption of machine learning for data analytics, maintaining a machine learning pipeline is becoming more complex as both the datasets and trained models evolve with time. In a collaborative environment, the changes and updates due to pipeline evolution often cause cumbersome coordination and maintenance work, raising the costs and making it hard to use. Existing solutions, unfortunately, do not address the version evolution problem, especially in a collaborative environment where non-linear version control semantics are necessary to isolate operations made by different user roles. The lack of version control semantics also incurs unnecessary storage consumption and lowers efficiency due to data duplication and repeated data pre-processing, which are avoidable. In this paper, we identify two main challenges that arise during the deployment of machine learning pipelines, and address them with the design of versioning for an end-to-end analytics system MLCask. The system supports multiple user roles with the ability to perform Git-like branching and merging operations in the context of the machine learning pipelines. We define and accelerate the metric-driven merge operation by pruning the pipeline search tree using reusable history records and pipeline compatibility information. Further, we design and implement the prioritized pipeline search, which gives preference to the pipelines that probably yield better performance. The effectiveness of MLCask is evaluated through an extensive study over several real-world deployment cases. The performance evaluation shows that the proposed merge operation is up to 7.8x faster and saves up to 11.9x storage space than the baseline method that does not utilize history records.
Efficient Memory Management for GPU-based Deep Learning Systems
Feb 19, 2019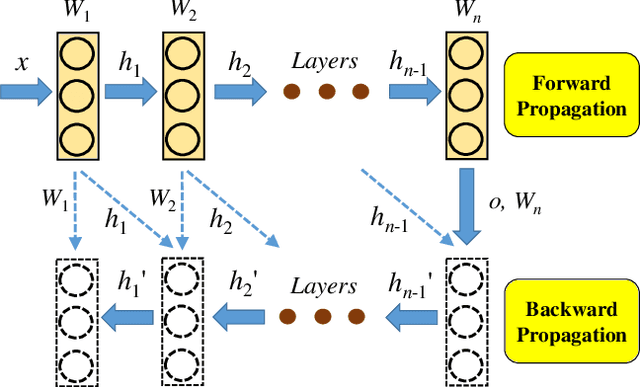
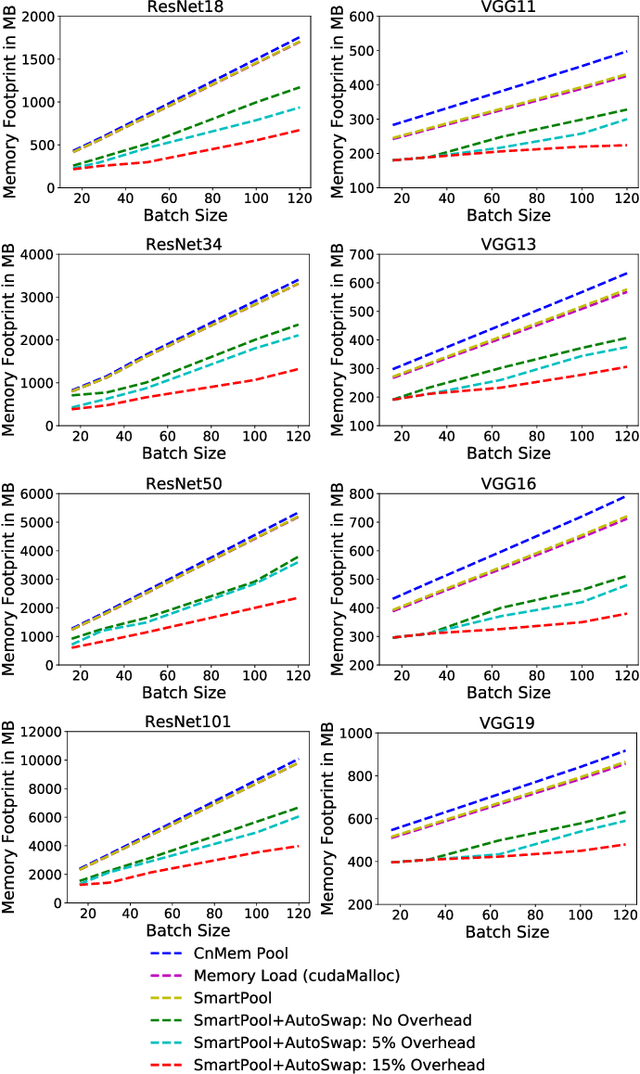
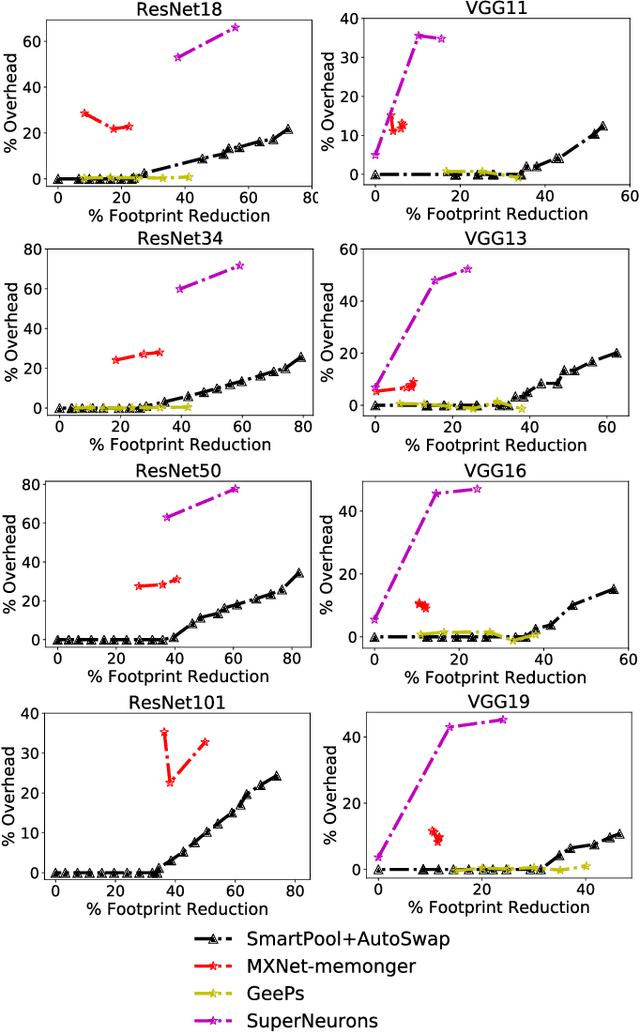
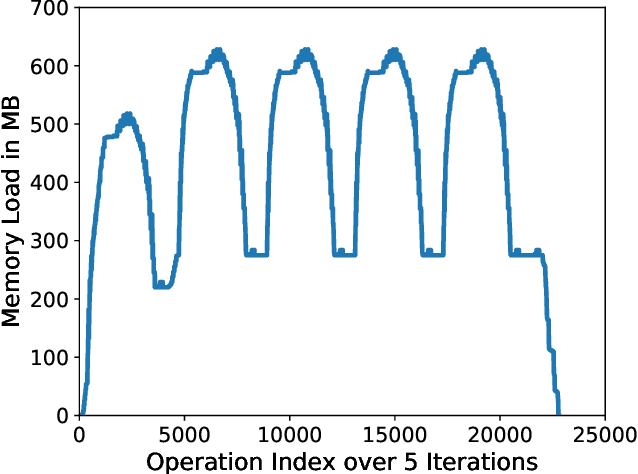
GPU (graphics processing unit) has been used for many data-intensive applications. Among them, deep learning systems are one of the most important consumer systems for GPU nowadays. As deep learning applications impose deeper and larger models in order to achieve higher accuracy, memory management becomes an important research topic for deep learning systems, given that GPU has limited memory size. Many approaches have been proposed towards this issue, e.g., model compression and memory swapping. However, they either degrade the model accuracy or require a lot of manual intervention. In this paper, we propose two orthogonal approaches to reduce the memory cost from the system perspective. Our approaches are transparent to the models, and thus do not affect the model accuracy. They are achieved by exploiting the iterative nature of the training algorithm of deep learning to derive the lifetime and read/write order of all variables. With the lifetime semantics, we are able to implement a memory pool with minimal fragments. However, the optimization problem is NP-complete. We propose a heuristic algorithm that reduces up to 13.3% of memory compared with Nvidia's default memory pool with equal time complexity. With the read/write semantics, the variables that are not in use can be swapped out from GPU to CPU to reduce the memory footprint. We propose multiple swapping strategies to automatically decide which variable to swap and when to swap out (in), which reduces the memory cost by up to 34.2% without communication overhead.