 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective Orchestration of AI x DB Workloads
Mar 04, 2026AI-driven analytics are increasingly crucial to data-centric decision-making. The practice of exporting data to machine learning runtimes incurs high overhead, limits robustness to data drift, and expands the attack surface, especially in multi-tenant, heterogeneous data systems. Integrating AI directly into database engines, while offering clear benefits, introduces challenges in managing joint query processing and model execution, optimizing end-to-end performance, coordinating execution under resource contention, and enforcing strong security and access-control guarantees. This paper discusses the challenges of joint DB-AI, or AIxDB, data management and query processing within AI-powered data systems. It presents various challenges that need to be addressed carefully, such as query optimization, execution scheduling, and distributed execution over heterogeneous hardware. Database components such as transaction management and access control need to be re-examined to support AI lifecycle management, mitigate data drift, and protect sensitive data from unauthorized AI operations. We present a design and preliminary results to demonstrate what may be key to the performance for serving AIxDB queries.
TabTracer: Monte Carlo Tree Search for Complex Table Reasoning with Large Language Models
Feb 15, 2026Large language models (LLMs) have emerged as powerful tools for natural language table reasoning, where there are two main categories of methods. Prompt-based approaches rely on language-only inference or one-pass program generation without step-level verification. Agent-based approaches use tools in a closed loop, but verification is often local and backtracking is limited, allowing errors to propagate and increasing cost. Moreover, they rely on chain- or beam-style trajectories that are typically combinatorially redundant, leading to high token costs. In this paper, we propose TabTracer, an agentic framework that coordinates multi-step tool calls over intermediate table states, with explicit state tracking for verification and rollback. First, it enforces step-level verification with typed operations and lightweight numeric and format checks to provide reliable rewards and suppress hallucinations. Second, execution-feedback Monte Carlo Tree Search maintains a search tree of candidate table states and uses backpropagated reflection scores to guide UCB1 selection and rollback via versioned snapshots. Third, it reduces redundancy with budget-aware pruning, deduplication, and state hashing with a monotonicity gate to cut token cost. Comprehensive evaluation on TabFact, WikiTQ, and CRT datasets shows that TabTracer outperforms state-of-the-art baselines by up to 6.7% in accuracy while reducing token consumption by 59--84%.
Aixel: A Unified, Adaptive and Extensible System for AI-powered Data Analysis
Oct 14, 2025A growing trend in modern data analysis is the integration of data management with learning, guided by accuracy, latency, and cost requirements. In practice, applications draw data of different formats from many sources. In the meanwhile, the objectives and budgets change over time. Existing systems handle these applications across databases, analysis libraries, and tuning services. Such fragmentation leads to complex user interaction, limited adaptability, suboptimal performance, and poor extensibility across components. To address these challenges, we present Aixel, a unified, adaptive, and extensible system for AI-powered data analysis. The system organizes work across four layers: application, task, model, and data. The task layer provides a declarative interface to capture user intent, which is parsed into an executable operator plan. An optimizer compiles and schedules this plan to meet specified goals in accuracy, latency, and cost. The task layer coordinates the execution of data and model operators, with built-in support for reuse and caching to improve efficiency. The model layer offers versioned storage for index, metadata, tensors, and model artifacts. It supports adaptive construction, task-aligned drift detection, and safe updates that reuse shared components. The data layer provides unified data management capabilities, including indexing, constraint-aware discovery, task-aligned selection, and comprehensive feature management. With the above designed layers, Aixel delivers a user friendly, adaptive, efficient, and extensible system.
Anytime Neural Architecture Search on Tabular Data
Mar 15, 2024



The increasing demand for tabular data analysis calls for transitioning from manual architecture design to Neural Architecture Search (NAS). This transition demands an efficient and responsive anytime NAS approach that is capable of returning current optimal architectures within any given time budget while progressively enhancing architecture quality with increased budget allocation. However, the area of research on Anytime NAS for tabular data remains unexplored. To this end, we introduce ATLAS, the first anytime NAS approach tailored for tabular data. ATLAS introduces a novel two-phase filtering-and-refinement optimization scheme with joint optimization, combining the strengths of both paradigms of training-free and training-based architecture evaluation. Specifically, in the filtering phase, ATLAS employs a new zero-cost proxy specifically designed for tabular data to efficiently estimate the performance of candidate architectures, thereby obtaining a set of promising architectures. Subsequently, in the refinement phase, ATLAS leverages a fixed-budget search algorithm to schedule the training of the promising candidates, so as to accurately identify the optimal architecture. To jointly optimize the two phases for anytime NAS, we also devise a budget-aware coordinator that delivers high NAS performance within constraints. Experimental evaluations demonstrate that our ATLAS can obtain a good-performing architecture within any predefined time budget and return better architectures as and when a new time budget is made available. Overall, it reduces the search time on tabular data by up to 82.75x compared to existing NAS approaches.
Secure and Verifiable Data Collaboration with Low-Cost Zero-Knowledge Proofs
Nov 26, 2023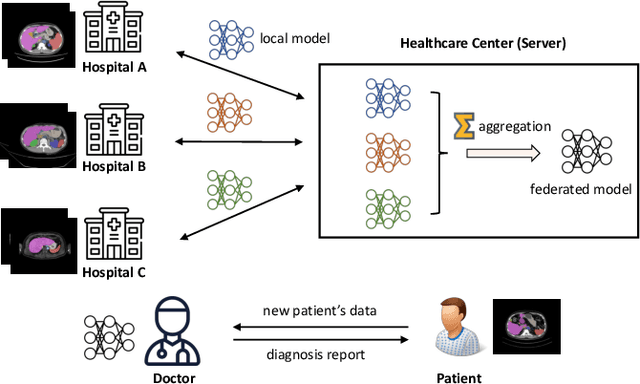
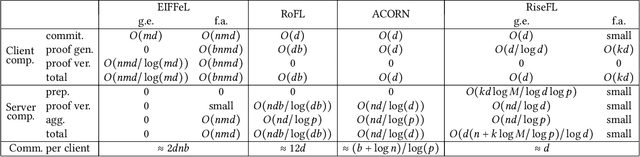
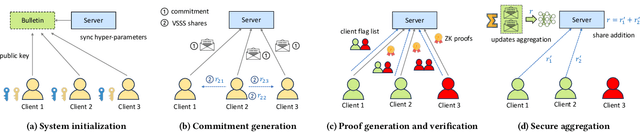
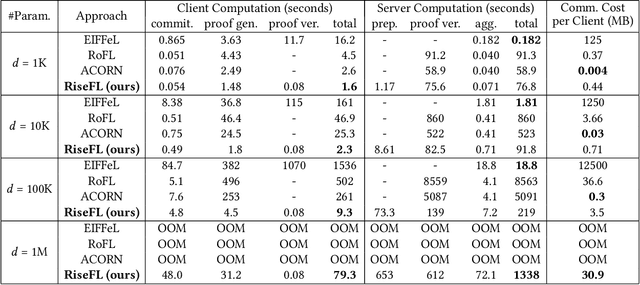
Organizations are increasingly recognizing the value of data collaboration for data analytics purposes. Yet, stringent data protection laws prohibit the direct exchange of raw data. To facilitate data collaboration, federated Learning (FL) emerges as a viable solution, which enables multiple clients to collaboratively train a machine learning (ML) model under the supervision of a central server while ensuring the confidentiality of their raw data. However, existing studies have unveiled two main risks: (i) the potential for the server to infer sensitive information from the client's uploaded updates (i.e., model gradients), compromising client input privacy, and (ii) the risk of malicious clients uploading malformed updates to poison the FL model, compromising input integrity. Recent works utilize secure aggregation with zero-knowledge proofs (ZKP) to guarantee input privacy and integrity in FL. Nevertheless, they suffer from extremely low efficiency and, thus, are impractical for real deployment. In this paper, we propose a novel and highly efficient solution RiseFL for secure and verifiable data collaboration, ensuring input privacy and integrity simultaneously.Firstly, we devise a probabilistic integrity check method that significantly reduces the cost of ZKP generation and verification. Secondly, we design a hybrid commitment scheme to satisfy Byzantine robustness with improved performance. Thirdly, we theoretically prove the security guarantee of the proposed solution. Extensive experiments on synthetic and real-world datasets suggest that our solution is effective and is highly efficient in both client computation and communication. For instance, RiseFL is up to 28x, 53x and 164x faster than three state-of-the-art baselines ACORN, RoFL and EIFFeL for the client computation.
Towards Robust Cross-domain Image Understanding with Unsupervised Noise Removal
Sep 09, 2021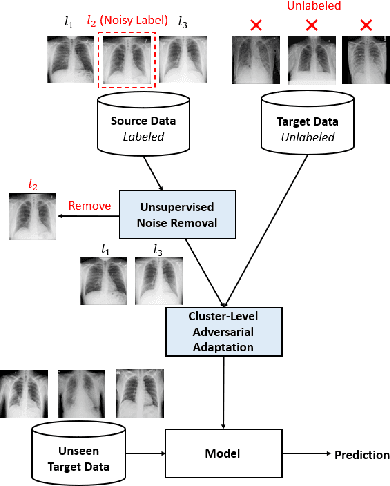
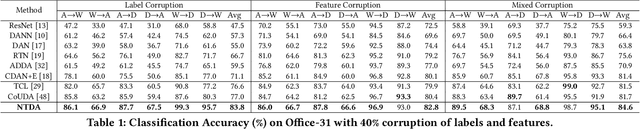
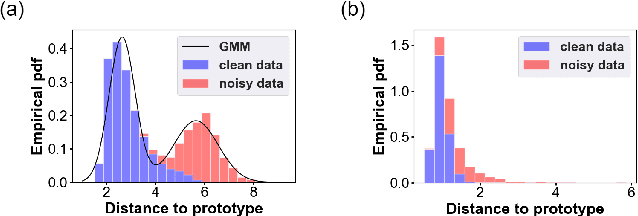
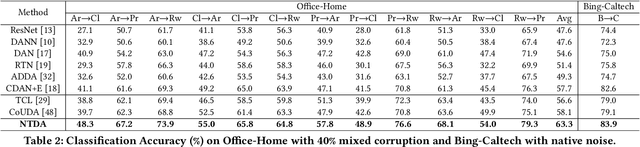
Deep learning models usually require a large amount of labeled data to achieve satisfactory performance. In multimedia analysis, domain adaptation studies the problem of cross-domain knowledge transfer from a label rich source domain to a label scarce target domain, thus potentially alleviates the annotation requirement for deep learning models. However, we find that contemporary domain adaptation methods for cross-domain image understanding perform poorly when source domain is noisy. Weakly Supervised Domain Adaptation (WSDA) studies the domain adaptation problem under the scenario where source data can be noisy. Prior methods on WSDA remove noisy source data and align the marginal distribution across domains without considering the fine-grained semantic structure in the embedding space, which have the problem of class misalignment, e.g., features of cats in the target domain might be mapped near features of dogs in the source domain. In this paper, we propose a novel method, termed Noise Tolerant Domain Adaptation, for WSDA. Specifically, we adopt the cluster assumption and learn cluster discriminatively with class prototypes in the embedding space. We propose to leverage the location information of the data points in the embedding space and model the location information with a Gaussian mixture model to identify noisy source data. We then design a network which incorporates the Gaussian mixture noise model as a sub-module for unsupervised noise removal and propose a novel cluster-level adversarial adaptation method which aligns unlabeled target data with the less noisy class prototypes for mapping the semantic structure across domains. We conduct extensive experiments to evaluate the effectiveness of our method on both general images and medical images from COVID-19 and e-commerce datasets. The results show that our method significantly outperforms state-of-the-art WSDA methods.
AlphaEvolve: A Learning Framework to Discover Novel Alphas in Quantitative Investment
Apr 01, 2021

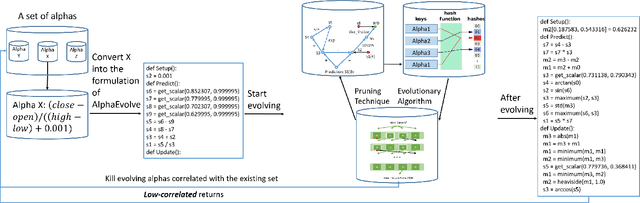
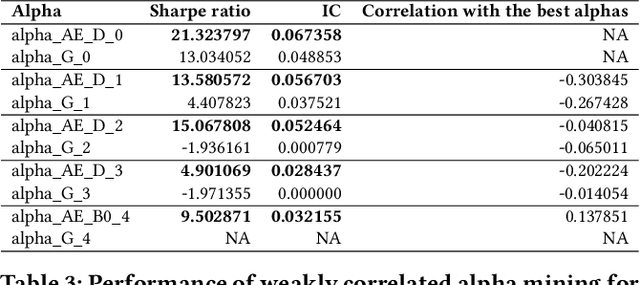
Alphas are stock prediction models capturing trading signals in a stock market. A set of effective alphas can generate weakly correlated high returns to diversify the risk. Existing alphas can be categorized into two classes: Formulaic alphas are simple algebraic expressions of scalar features, and thus can generalize well and be mined into a weakly correlated set. Machine learning alphas are data-driven models over vector and matrix features. They are more predictive than formulaic alphas, but are too complex to mine into a weakly correlated set. In this paper, we introduce a new class of alphas to model scalar, vector, and matrix features which possess the strengths of these two existing classes. The new alphas predict returns with high accuracy and can be mined into a weakly correlated set. In addition, we propose a novel alpha mining framework based on AutoML, called AlphaEvolve, to generate the new alphas. To this end, we first propose operators for generating the new alphas and selectively injecting relational domain knowledge to model the relations between stocks. We then accelerate the alpha mining by proposing a pruning technique for redundant alphas. Experiments show that AlphaEvolve can evolve initial alphas into the new alphas with high returns and weak correlations.
MLCask: Efficient Management of Component Evolution in Collaborative Data Analytics Pipelines
Oct 17, 2020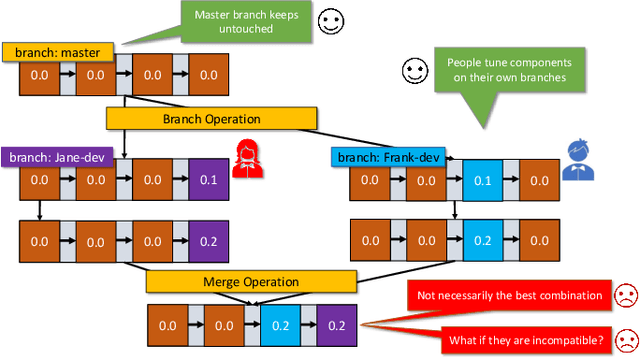
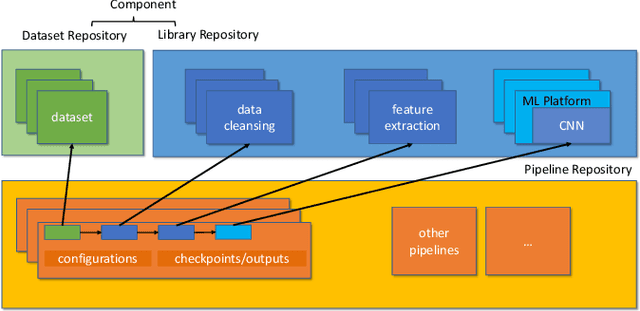
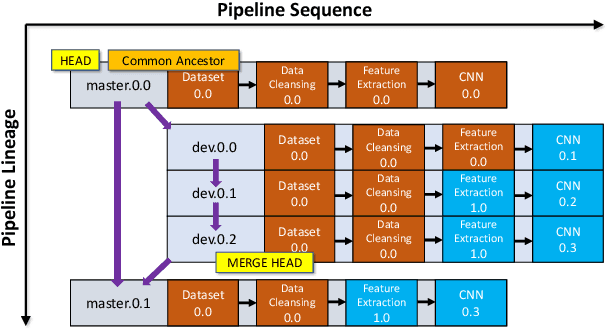
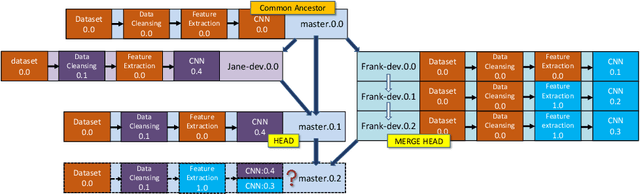
With the ever-increasing adoption of machine learning for data analytics, maintaining a machine learning pipeline is becoming more complex as both the datasets and trained models evolve with time. In a collaborative environment, the changes and updates due to pipeline evolution often cause cumbersome coordination and maintenance work, raising the costs and making it hard to use. Existing solutions, unfortunately, do not address the version evolution problem, especially in a collaborative environment where non-linear version control semantics are necessary to isolate operations made by different user roles. The lack of version control semantics also incurs unnecessary storage consumption and lowers efficiency due to data duplication and repeated data pre-processing, which are avoidable. In this paper, we identify two main challenges that arise during the deployment of machine learning pipelines, and address them with the design of versioning for an end-to-end analytics system MLCask. The system supports multiple user roles with the ability to perform Git-like branching and merging operations in the context of the machine learning pipelines. We define and accelerate the metric-driven merge operation by pruning the pipeline search tree using reusable history records and pipeline compatibility information. Further, we design and implement the prioritized pipeline search, which gives preference to the pipelines that probably yield better performance. The effectiveness of MLCask is evaluated through an extensive study over several real-world deployment cases. The performance evaluation shows that the proposed merge operation is up to 7.8x faster and saves up to 11.9x storage space than the baseline method that does not utilize history records.