 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCohortNet: Empowering Cohort Discovery for Interpretable Healthcare Analytics
Jun 20, 2024Cohort studies are of significant importance in the field of healthcare analysis. However, existing methods typically involve manual, labor-intensive, and expert-driven pattern definitions or rely on simplistic clustering techniques that lack medical relevance. Automating cohort studies with interpretable patterns has great potential to facilitate healthcare analysis but remains an unmet need in prior research efforts. In this paper, we propose a cohort auto-discovery model, CohortNet, for interpretable healthcare analysis, focusing on the effective identification, representation, and exploitation of cohorts characterized by medically meaningful patterns. CohortNet initially learns fine-grained patient representations by separately processing each feature, considering both individual feature trends and feature interactions at each time step. Subsequently, it classifies each feature into distinct states and employs a heuristic cohort exploration strategy to effectively discover substantial cohorts with concrete patterns. For each identified cohort, it learns comprehensive cohort representations with credible evidence through associated patient retrieval. Ultimately, given a new patient, CohortNet can leverage relevant cohorts with distinguished importance, which can provide a more holistic understanding of the patient's conditions. Extensive experiments on three real-world datasets demonstrate that it consistently outperforms state-of-the-art approaches and offers interpretable insights from diverse perspectives in a top-down fashion.
Toward Cohort Intelligence: A Universal Cohort Representation Learning Framework for Electronic Health Record Analysis
Apr 12, 2023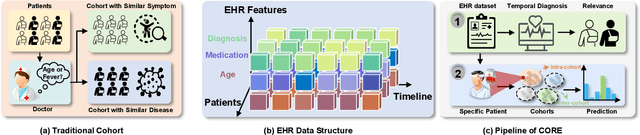
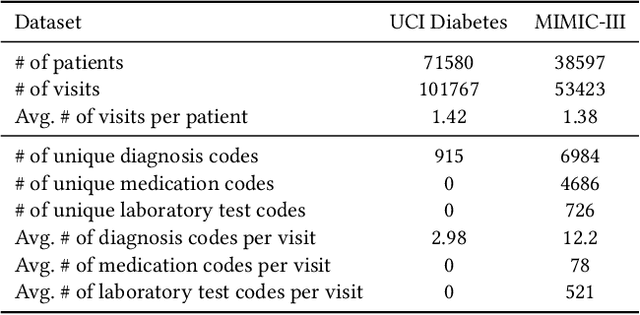
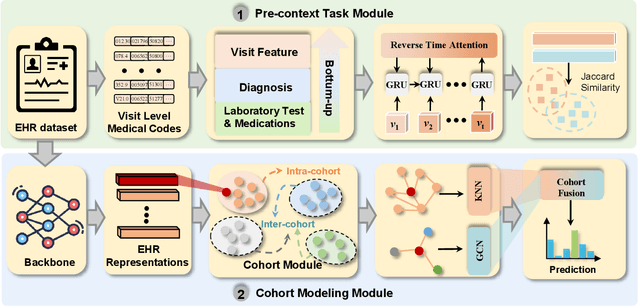
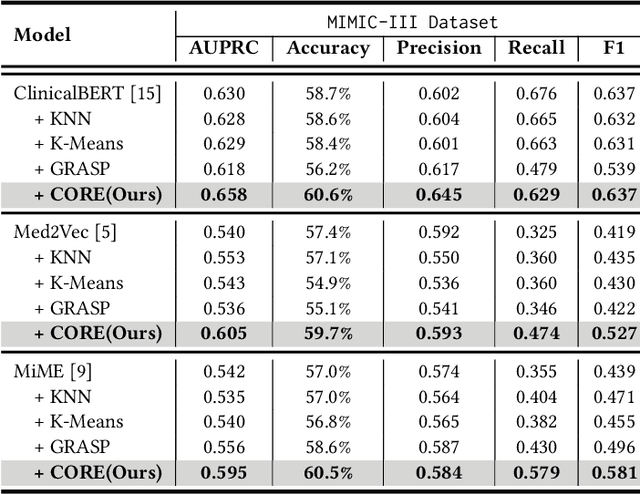
Electronic Health Records (EHR) are generated from clinical routine care recording valuable information of broad patient populations, which provide plentiful opportunities for improving patient management and intervention strategies in clinical practice. To exploit the enormous potential of EHR data, a popular EHR data analysis paradigm in machine learning is EHR representation learning, which first leverages the individual patient's EHR data to learn informative representations by a backbone, and supports diverse health-care downstream tasks grounded on the representations. Unfortunately, such a paradigm fails to access the in-depth analysis of patients' relevance, which is generally known as cohort studies in clinical practice. Specifically, patients in the same cohort tend to share similar characteristics, implying their resemblance in medical conditions such as symptoms or diseases. In this paper, we propose a universal COhort Representation lEarning (CORE) framework to augment EHR utilization by leveraging the fine-grained cohort information among patients. In particular, CORE first develops an explicit patient modeling task based on the prior knowledge of patients' diagnosis codes, which measures the latent relevance among patients to adaptively divide the cohorts for each patient. Based on the constructed cohorts, CORE recodes the pre-extracted EHR data representation from intra- and inter-cohort perspectives, yielding augmented EHR data representation learning. CORE is readily applicable to diverse backbone models, serving as a universal plug-in framework to infuse cohort information into healthcare methods for boosted performance. We conduct an extensive experimental evaluation on two real-world datasets, and the experimental results demonstrate the effectiveness and generalizability of CORE.
A Dietary Nutrition-aided Healthcare Platform via Effective Food Recognition on a Localized Singaporean Food Dataset
Jan 10, 2023



Localized food datasets have profound meaning in revealing a country's special cuisines to explore people's dietary behaviors, which will shed light on their health conditions and disease development. In this paper, revolving around the demand for accurate food recognition in Singapore, we develop the FoodSG platform to incubate diverse healthcare-oriented applications as a service in Singapore, taking into account their shared requirements. We release a localized Singaporean food dataset FoodSG-233 with a systematic cleaning and curation pipeline for promoting future data management research in food computing. To overcome the hurdle in recognition performance brought by Singaporean multifarious food dishes, we propose to integrate supervised contrastive learning into our food recognition model FoodSG-SCL for the intrinsic capability to mine hard positive/negative samples and therefore boost the accuracy. Through a comprehensive evaluation, we share the insightful experience with practitioners in the data management community regarding food-related data-intensive healthcare applications. The FoodSG-233 dataset can be accessed via: https://foodlg.comp.nus.edu.sg/.
Towards Robust Cross-domain Image Understanding with Unsupervised Noise Removal
Sep 09, 2021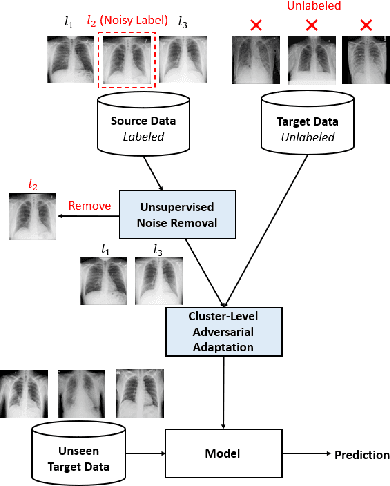
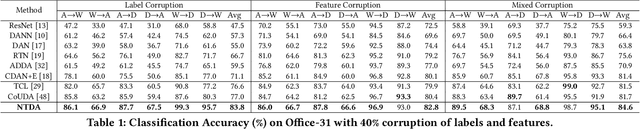
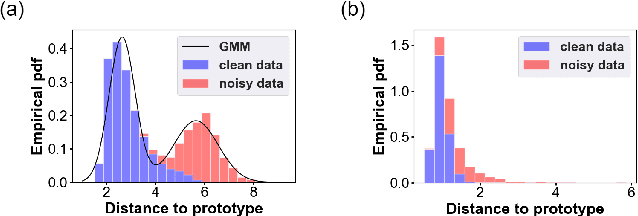
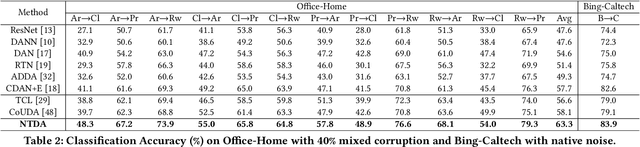
Deep learning models usually require a large amount of labeled data to achieve satisfactory performance. In multimedia analysis, domain adaptation studies the problem of cross-domain knowledge transfer from a label rich source domain to a label scarce target domain, thus potentially alleviates the annotation requirement for deep learning models. However, we find that contemporary domain adaptation methods for cross-domain image understanding perform poorly when source domain is noisy. Weakly Supervised Domain Adaptation (WSDA) studies the domain adaptation problem under the scenario where source data can be noisy. Prior methods on WSDA remove noisy source data and align the marginal distribution across domains without considering the fine-grained semantic structure in the embedding space, which have the problem of class misalignment, e.g., features of cats in the target domain might be mapped near features of dogs in the source domain. In this paper, we propose a novel method, termed Noise Tolerant Domain Adaptation, for WSDA. Specifically, we adopt the cluster assumption and learn cluster discriminatively with class prototypes in the embedding space. We propose to leverage the location information of the data points in the embedding space and model the location information with a Gaussian mixture model to identify noisy source data. We then design a network which incorporates the Gaussian mixture noise model as a sub-module for unsupervised noise removal and propose a novel cluster-level adversarial adaptation method which aligns unlabeled target data with the less noisy class prototypes for mapping the semantic structure across domains. We conduct extensive experiments to evaluate the effectiveness of our method on both general images and medical images from COVID-19 and e-commerce datasets. The results show that our method significantly outperforms state-of-the-art WSDA methods.
ARM-Net: Adaptive Relation Modeling Network for Structured Data
Jul 05, 2021


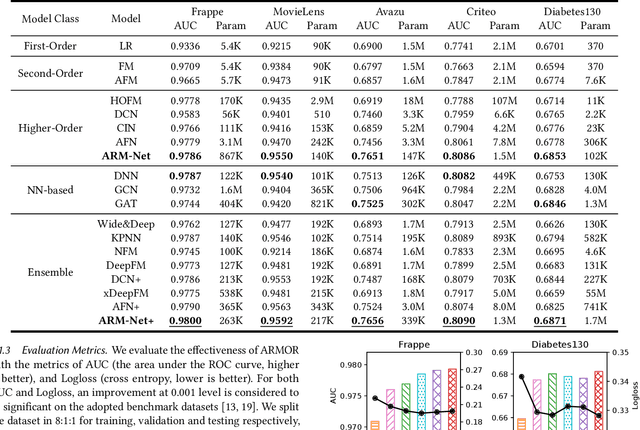
Relational databases are the de facto standard for storing and querying structured data, and extracting insights from structured data requires advanced analytics. Deep neural networks (DNNs) have achieved super-human prediction performance in particular data types, e.g., images. However, existing DNNs may not produce meaningful results when applied to structured data. The reason is that there are correlations and dependencies across combinations of attribute values in a table, and these do not follow simple additive patterns that can be easily mimicked by a DNN. The number of possible such cross features is combinatorial, making them computationally prohibitive to model. Furthermore, the deployment of learning models in real-world applications has also highlighted the need for interpretability, especially for high-stakes applications, which remains another issue of concern to DNNs. In this paper, we present ARM-Net, an adaptive relation modeling network tailored for structured data, and a lightweight framework ARMOR based on ARM-Net for relational data analytics. The key idea is to model feature interactions with cross features selectively and dynamically, by first transforming the input features into exponential space, and then determining the interaction order and interaction weights adaptively for each cross feature. We propose a novel sparse attention mechanism to dynamically generate the interaction weights given the input tuple, so that we can explicitly model cross features of arbitrary orders with noisy features filtered selectively. Then during model inference, ARM-Net can specify the cross features being used for each prediction for higher accuracy and better interpretability. Our extensive experiments on real-world datasets demonstrate that ARM-Net consistently outperforms existing models and provides more interpretable predictions for data-driven decision making.
MLCask: Efficient Management of Component Evolution in Collaborative Data Analytics Pipelines
Oct 17, 2020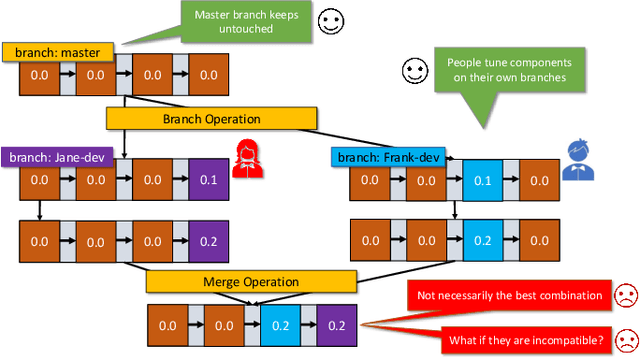
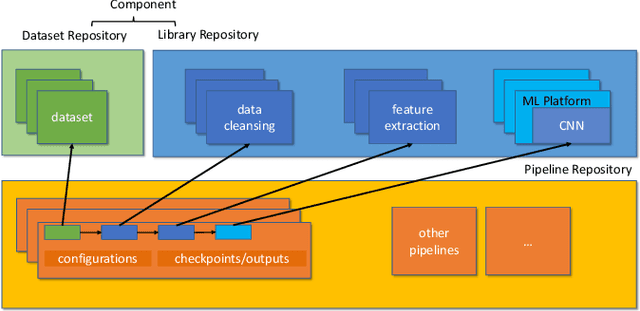
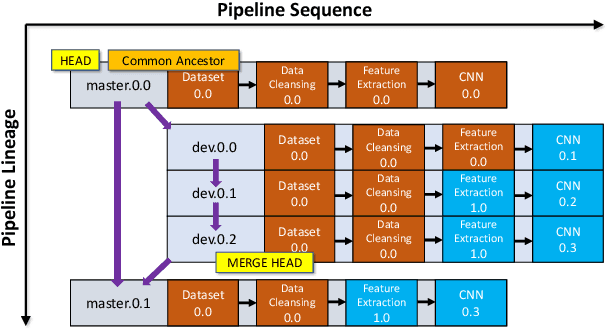
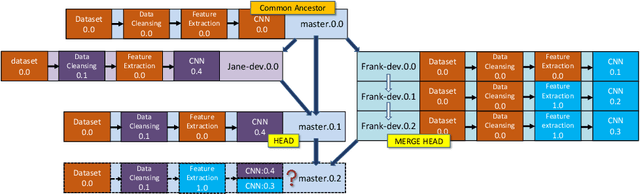
With the ever-increasing adoption of machine learning for data analytics, maintaining a machine learning pipeline is becoming more complex as both the datasets and trained models evolve with time. In a collaborative environment, the changes and updates due to pipeline evolution often cause cumbersome coordination and maintenance work, raising the costs and making it hard to use. Existing solutions, unfortunately, do not address the version evolution problem, especially in a collaborative environment where non-linear version control semantics are necessary to isolate operations made by different user roles. The lack of version control semantics also incurs unnecessary storage consumption and lowers efficiency due to data duplication and repeated data pre-processing, which are avoidable. In this paper, we identify two main challenges that arise during the deployment of machine learning pipelines, and address them with the design of versioning for an end-to-end analytics system MLCask. The system supports multiple user roles with the ability to perform Git-like branching and merging operations in the context of the machine learning pipelines. We define and accelerate the metric-driven merge operation by pruning the pipeline search tree using reusable history records and pipeline compatibility information. Further, we design and implement the prioritized pipeline search, which gives preference to the pipelines that probably yield better performance. The effectiveness of MLCask is evaluated through an extensive study over several real-world deployment cases. The performance evaluation shows that the proposed merge operation is up to 7.8x faster and saves up to 11.9x storage space than the baseline method that does not utilize history records.
TRACER: A Framework for Facilitating Accurate and Interpretable Analytics for High Stakes Applications
Mar 24, 2020
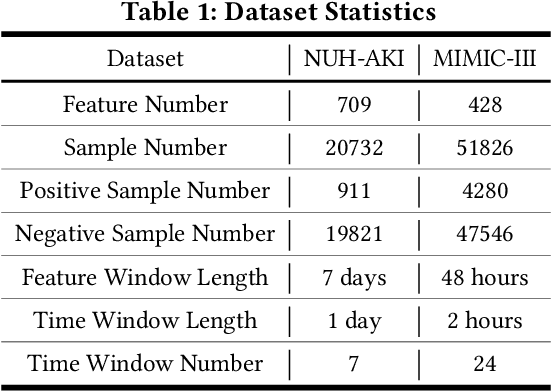
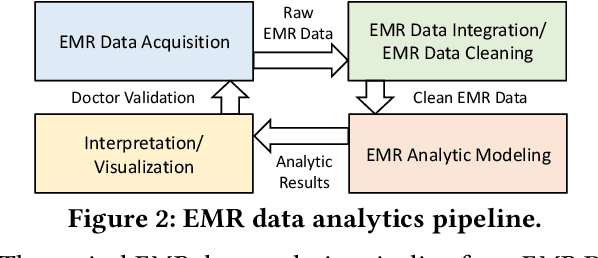
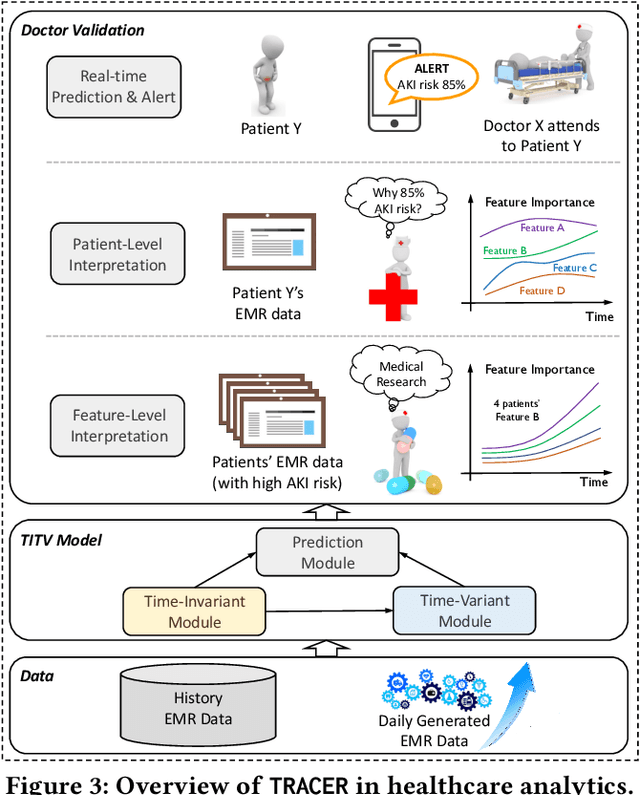
In high stakes applications such as healthcare and finance analytics, the interpretability of predictive models is required and necessary for domain practitioners to trust the predictions. Traditional machine learning models, e.g., logistic regression (LR), are easy to interpret in nature. However, many of these models aggregate time-series data without considering the temporal correlations and variations. Therefore, their performance cannot match up to recurrent neural network (RNN) based models, which are nonetheless difficult to interpret. In this paper, we propose a general framework TRACER to facilitate accurate and interpretable predictions, with a novel model TITV devised for healthcare analytics and other high stakes applications such as financial investment and risk management. Different from LR and other existing RNN-based models, TITV is designed to capture both the time-invariant and the time-variant feature importance using a feature-wise transformation subnetwork and a self-attention subnetwork, for the feature influence shared over the entire time series and the time-related importance respectively. Healthcare analytics is adopted as a driving use case, and we note that the proposed TRACER is also applicable to other domains, e.g., fintech. We evaluate the accuracy of TRACER extensively in two real-world hospital datasets, and our doctors/clinicians further validate the interpretability of TRACER in both the patient level and the feature level. Besides, TRACER is also validated in a high stakes financial application and a critical temperature forecasting application. The experimental results confirm that TRACER facilitates both accurate and interpretable analytics for high stakes applications.
Attentive Geo-Social Group Recommendation
Nov 15, 2019

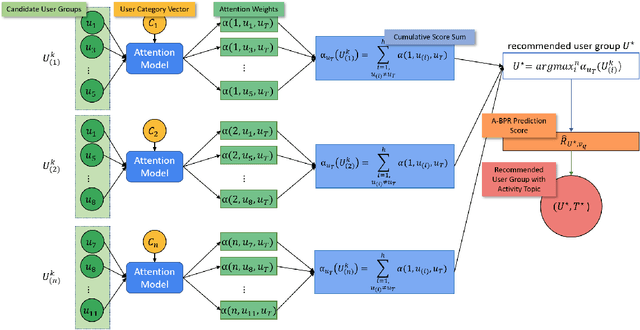

Social activities play an important role in people's daily life since they interact. For recommendations based on social activities, it is vital to have not only the activity information but also individuals' social relations. Thanks to the geo-social networks and widespread use of location-aware mobile devices, massive geo-social data is now readily available for exploitation by the recommendation system. In this paper, a novel group recommendation method, called attentive geo-social group recommendation, is proposed to recommend the target user with both activity locations and a group of users that may join the activities. We present an attention mechanism to model the influence of the target user $u_T$ in candidate user groups that satisfy the social constraints. It helps to retrieve the optimal user group and activity topic candidates, as well as explains the group decision-making process. Once the user group and topics are retrieved, a novel efficient spatial query algorithm SPA-DF is employed to determine the activity location under the constraints of the given user group and activity topic candidates. The proposed method is evaluated in real-world datasets and the experimental results show that the proposed model significantly outperforms baseline methods.