 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning in Imperfect Environment: Multi-Label Classification with Long-Tailed Distribution and Partial Labels
Apr 20, 2023Conventional multi-label classification (MLC) methods assume that all samples are fully labeled and identically distributed. Unfortunately, this assumption is unrealistic in large-scale MLC data that has long-tailed (LT) distribution and partial labels (PL). To address the problem, we introduce a novel task, Partial labeling and Long-Tailed Multi-Label Classification (PLT-MLC), to jointly consider the above two imperfect learning environments. Not surprisingly, we find that most LT-MLC and PL-MLC approaches fail to solve the PLT-MLC, resulting in significant performance degradation on the two proposed PLT-MLC benchmarks. Therefore, we propose an end-to-end learning framework: \textbf{CO}rrection $\rightarrow$ \textbf{M}odificat\textbf{I}on $\rightarrow$ balan\textbf{C}e, abbreviated as \textbf{\method{}}. Our bootstrapping philosophy is to simultaneously correct the missing labels (Correction) with convinced prediction confidence over a class-aware threshold and to learn from these recall labels during training. We next propose a novel multi-focal modifier loss that simultaneously addresses head-tail imbalance and positive-negative imbalance to adaptively modify the attention to different samples (Modification) under the LT class distribution. In addition, we develop a balanced training strategy by distilling the model's learning effect from head and tail samples, and thus design a balanced classifier (Balance) conditioned on the head and tail learning effect to maintain stable performance for all samples. Our experimental study shows that the proposed \method{} significantly outperforms general MLC, LT-MLC and PL-MLC methods in terms of effectiveness and robustness on our newly created PLT-MLC datasets.
Toward Cohort Intelligence: A Universal Cohort Representation Learning Framework for Electronic Health Record Analysis
Apr 12, 2023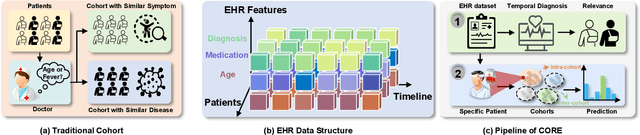
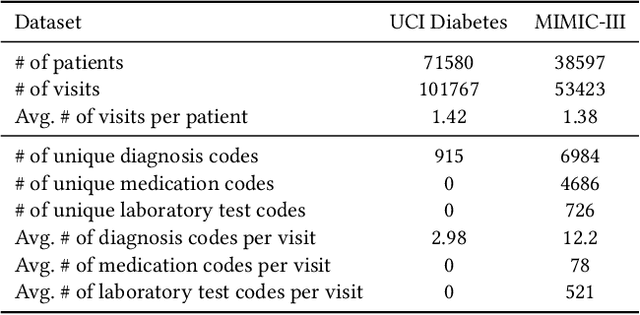
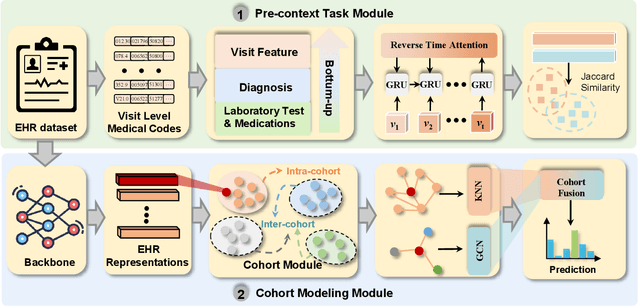
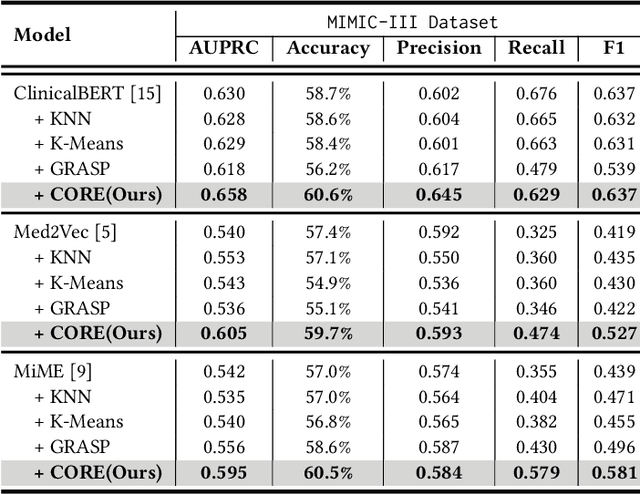
Electronic Health Records (EHR) are generated from clinical routine care recording valuable information of broad patient populations, which provide plentiful opportunities for improving patient management and intervention strategies in clinical practice. To exploit the enormous potential of EHR data, a popular EHR data analysis paradigm in machine learning is EHR representation learning, which first leverages the individual patient's EHR data to learn informative representations by a backbone, and supports diverse health-care downstream tasks grounded on the representations. Unfortunately, such a paradigm fails to access the in-depth analysis of patients' relevance, which is generally known as cohort studies in clinical practice. Specifically, patients in the same cohort tend to share similar characteristics, implying their resemblance in medical conditions such as symptoms or diseases. In this paper, we propose a universal COhort Representation lEarning (CORE) framework to augment EHR utilization by leveraging the fine-grained cohort information among patients. In particular, CORE first develops an explicit patient modeling task based on the prior knowledge of patients' diagnosis codes, which measures the latent relevance among patients to adaptively divide the cohorts for each patient. Based on the constructed cohorts, CORE recodes the pre-extracted EHR data representation from intra- and inter-cohort perspectives, yielding augmented EHR data representation learning. CORE is readily applicable to diverse backbone models, serving as a universal plug-in framework to infuse cohort information into healthcare methods for boosted performance. We conduct an extensive experimental evaluation on two real-world datasets, and the experimental results demonstrate the effectiveness and generalizability of CORE.
CAusal and collaborative proxy-tasKs lEarning for Semi-Supervised Domain Adaptation
Mar 30, 2023Semi-supervised domain adaptation (SSDA) adapts a learner to a new domain by effectively utilizing source domain data and a few labeled target samples. It is a practical yet under-investigated research topic. In this paper, we analyze the SSDA problem from two perspectives that have previously been overlooked, and correspondingly decompose it into two \emph{key subproblems}: \emph{robust domain adaptation (DA) learning} and \emph{maximal cross-domain data utilization}. \textbf{(i)} From a causal theoretical view, a robust DA model should distinguish the invariant ``concept'' (key clue to image label) from the nuisance of confounding factors across domains. To achieve this goal, we propose to generate \emph{concept-invariant samples} to enable the model to classify the samples through causal intervention, yielding improved generalization guarantees; \textbf{(ii)} Based on the robust DA theory, we aim to exploit the maximal utilization of rich source domain data and a few labeled target samples to boost SSDA further. Consequently, we propose a collaboratively debiasing learning framework that utilizes two complementary semi-supervised learning (SSL) classifiers to mutually exchange their unbiased knowledge, which helps unleash the potential of source and target domain training data, thereby producing more convincing pseudo-labels. Such obtained labels facilitate cross-domain feature alignment and duly improve the invariant concept learning. In our experimental study, we show that the proposed model significantly outperforms SOTA methods in terms of effectiveness and generalisability on SSDA datasets.