 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Memory Management for GPU-based Deep Learning Systems
Paper and Code
Feb 19, 2019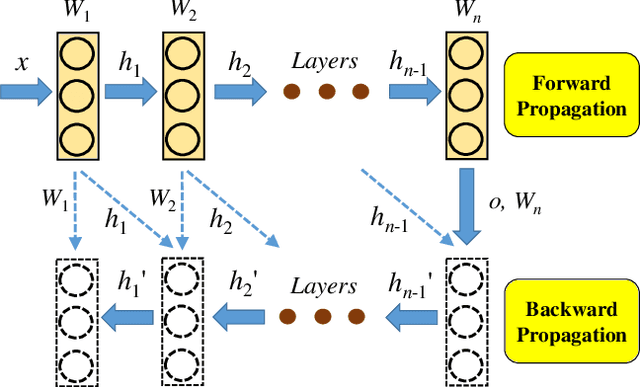
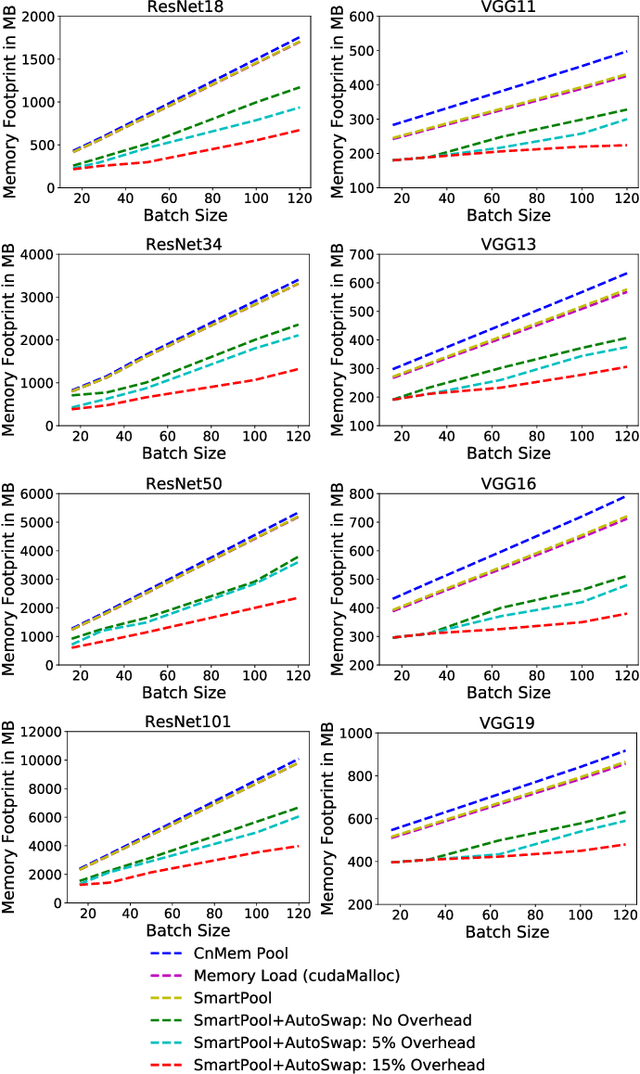
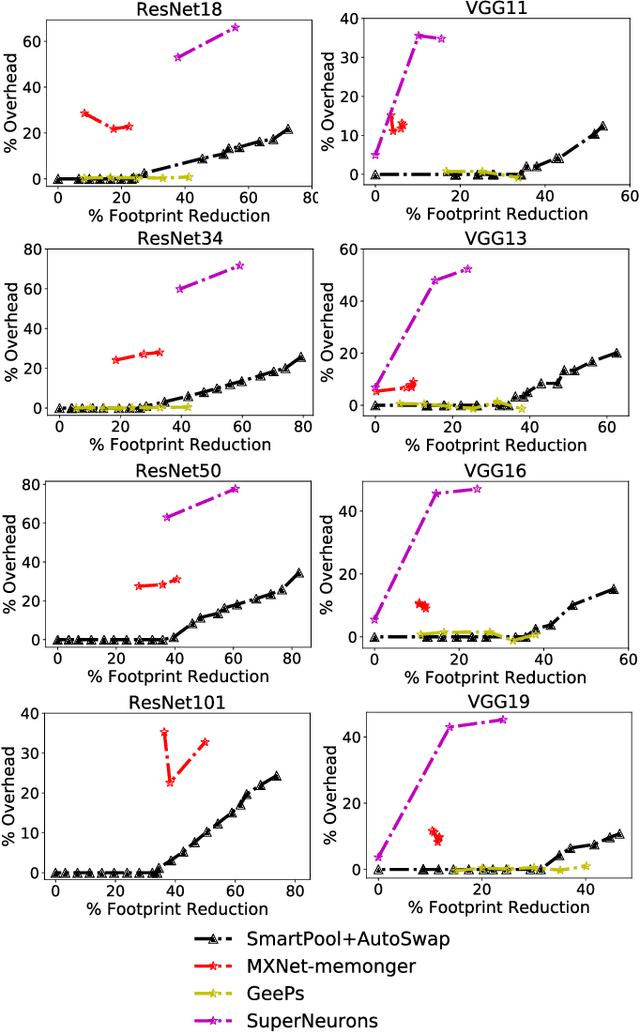
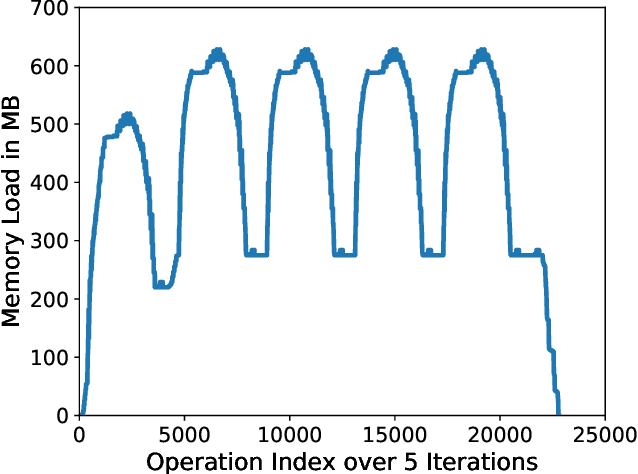
GPU (graphics processing unit) has been used for many data-intensive applications. Among them, deep learning systems are one of the most important consumer systems for GPU nowadays. As deep learning applications impose deeper and larger models in order to achieve higher accuracy, memory management becomes an important research topic for deep learning systems, given that GPU has limited memory size. Many approaches have been proposed towards this issue, e.g., model compression and memory swapping. However, they either degrade the model accuracy or require a lot of manual intervention. In this paper, we propose two orthogonal approaches to reduce the memory cost from the system perspective. Our approaches are transparent to the models, and thus do not affect the model accuracy. They are achieved by exploiting the iterative nature of the training algorithm of deep learning to derive the lifetime and read/write order of all variables. With the lifetime semantics, we are able to implement a memory pool with minimal fragments. However, the optimization problem is NP-complete. We propose a heuristic algorithm that reduces up to 13.3% of memory compared with Nvidia's default memory pool with equal time complexity. With the read/write semantics, the variables that are not in use can be swapped out from GPU to CPU to reduce the memory footprint. We propose multiple swapping strategies to automatically decide which variable to swap and when to swap out (in), which reduces the memory cost by up to 34.2% without communication overhead.