 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Investigation on Deep Learning-Based Omnidirectional Image and Video Super-Resolution
Jun 07, 2025Omnidirectional image and video super-resolution is a crucial research topic in low-level vision, playing an essential role in virtual reality and augmented reality applications. Its goal is to reconstruct high-resolution images or video frames from low-resolution inputs, thereby enhancing detail preservation and enabling more accurate scene analysis and interpretation. In recent years, numerous innovative and effective approaches have been proposed, predominantly based on deep learning techniques, involving diverse network architectures, loss functions, projection strategies, and training datasets. This paper presents a systematic review of recent progress in omnidirectional image and video super-resolution, focusing on deep learning-based methods. Given that existing datasets predominantly rely on synthetic degradation and fall short in capturing real-world distortions, we introduce a new dataset, 360Insta, that comprises authentically degraded omnidirectional images and videos collected under diverse conditions, including varying lighting, motion, and exposure settings. This dataset addresses a critical gap in current omnidirectional benchmarks and enables more robust evaluation of the generalization capabilities of omnidirectional super-resolution methods. We conduct comprehensive qualitative and quantitative evaluations of existing methods on both public datasets and our proposed dataset. Furthermore, we provide a systematic overview of the current status of research and discuss promising directions for future exploration. All datasets, methods, and evaluation metrics introduced in this work are publicly available and will be regularly updated. Project page: https://github.com/nqian1/Survey-on-ODISR-and-ODVSR.
Agent-based Video Trimming
Dec 12, 2024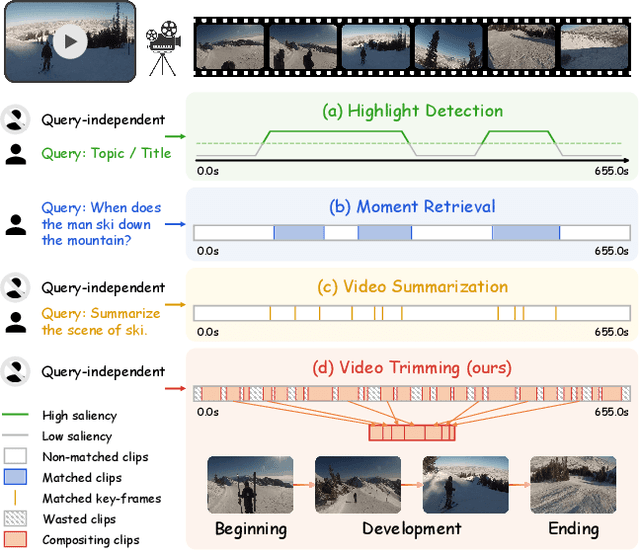
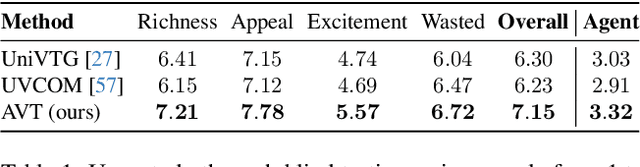
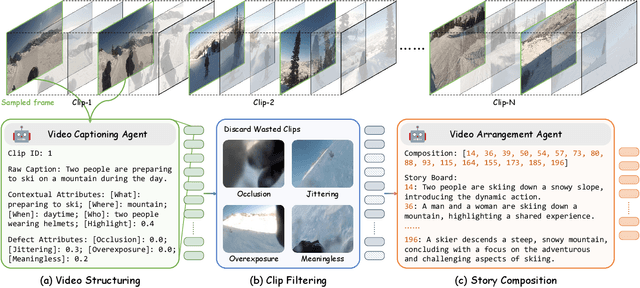
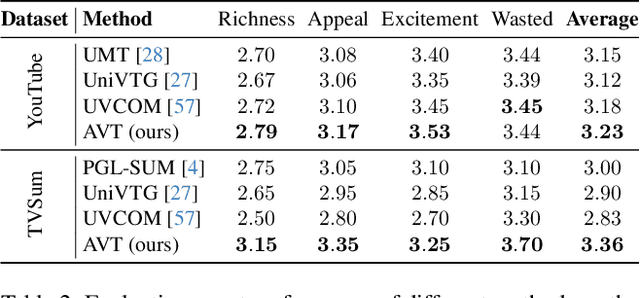
As information becomes more accessible, user-generated videos are increasing in length, placing a burden on viewers to sift through vast content for valuable insights. This trend underscores the need for an algorithm to extract key video information efficiently. Despite significant advancements in highlight detection, moment retrieval, and video summarization, current approaches primarily focus on selecting specific time intervals, often overlooking the relevance between segments and the potential for segment arranging. In this paper, we introduce a novel task called Video Trimming (VT), which focuses on detecting wasted footage, selecting valuable segments, and composing them into a final video with a coherent story. To address this task, we propose Agent-based Video Trimming (AVT), structured into three phases: Video Structuring, Clip Filtering, and Story Composition. Specifically, we employ a Video Captioning Agent to convert video slices into structured textual descriptions, a Filtering Module to dynamically discard low-quality footage based on the structured information of each clip, and a Video Arrangement Agent to select and compile valid clips into a coherent final narrative. For evaluation, we develop a Video Evaluation Agent to assess trimmed videos, conducting assessments in parallel with human evaluations. Additionally, we curate a new benchmark dataset for video trimming using raw user videos from the internet. As a result, AVT received more favorable evaluations in user studies and demonstrated superior mAP and precision on the YouTube Highlights, TVSum, and our own dataset for the highlight detection task. The code and models are available at https://ylingfeng.github.io/AVT.