 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATCHA: Can Multi-Agent Collaboration Build a Trustworthy Conversational Recommender?
Apr 26, 2025



In this paper, we propose a multi-agent collaboration framework called MATCHA for conversational recommendation system, leveraging large language models (LLMs) to enhance personalization and user engagement. Users can request recommendations via free-form text and receive curated lists aligned with their interests, preferences, and constraints. Our system introduces specialized agents for intent analysis, candidate generation, ranking, re-ranking, explainability, and safeguards. These agents collaboratively improve recommendations accuracy, diversity, and safety. On eight metrics, our model achieves superior or comparable performance to the current state-of-the-art. Through comparisons with six baseline models, our approach addresses key challenges in conversational recommendation systems for game recommendations, including: (1) handling complex, user-specific requests, (2) enhancing personalization through multi-agent collaboration, (3) empirical evaluation and deployment, and (4) ensuring safe and trustworthy interactions.
OMuleT: Orchestrating Multiple Tools for Practicable Conversational Recommendation
Nov 28, 2024



In this paper, we present a systematic effort to design, evaluate, and implement a realistic conversational recommender system (CRS). The objective of our system is to allow users to input free-form text to request recommendations, and then receive a list of relevant and diverse items. While previous work on synthetic queries augments large language models (LLMs) with 1-3 tools, we argue that a more extensive toolbox is necessary to effectively handle real user requests. As such, we propose a novel approach that equips LLMs with over 10 tools, providing them access to the internal knowledge base and API calls used in production. We evaluate our model on a dataset of real users and show that it generates relevant, novel, and diverse recommendations compared to vanilla LLMs. Furthermore, we conduct ablation studies to demonstrate the effectiveness of using the full range of tools in our toolbox. We share our designs and lessons learned from deploying the system for internal alpha release. Our contribution is the addressing of all four key aspects of a practicable CRS: (1) real user requests, (2) augmenting LLMs with a wide variety of tools, (3) extensive evaluation, and (4) deployment insights.
Causal Feature Selection Method for Contextual Multi-Armed Bandits in Recommender System
Sep 20, 2024


Features (a.k.a. context) are critical for contextual multi-armed bandits (MAB) performance. In practice of large scale online system, it is important to select and implement important features for the model: missing important features can led to sub-optimal reward outcome, and including irrelevant features can cause overfitting, poor model interpretability, and implementation cost. However, feature selection methods for conventional machine learning models fail short for contextual MAB use cases, as conventional methods select features correlated with the outcome variable, but not necessarily causing heterogeneuous treatment effect among arms which are truely important for contextual MAB. In this paper, we introduce model-free feature selection methods designed for contexutal MAB problem, based on heterogeneous causal effect contributed by the feature to the reward distribution. Empirical evaluation is conducted based on synthetic data as well as real data from an online experiment for optimizing content cover image in a recommender system. The results show this feature selection method effectively selects the important features that lead to higher contextual MAB reward than unimportant features. Compared with model embedded method, this model-free method has advantage of fast computation speed, ease of implementation, and prune of model mis-specification issues.
ASPEN: High-Throughput LoRA Fine-Tuning of Large Language Models with a Single GPU
Dec 05, 2023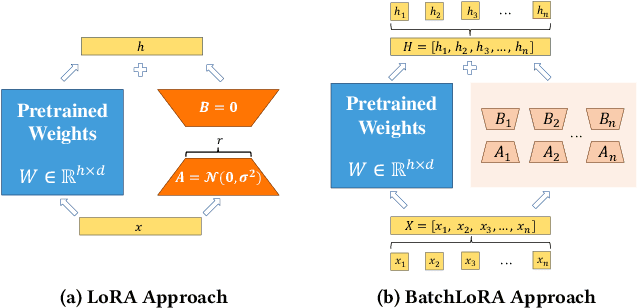
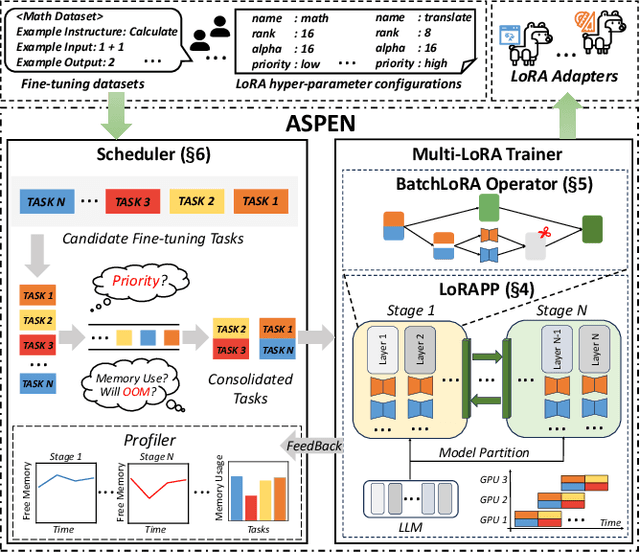
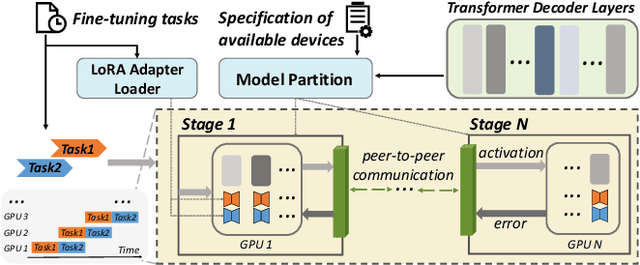
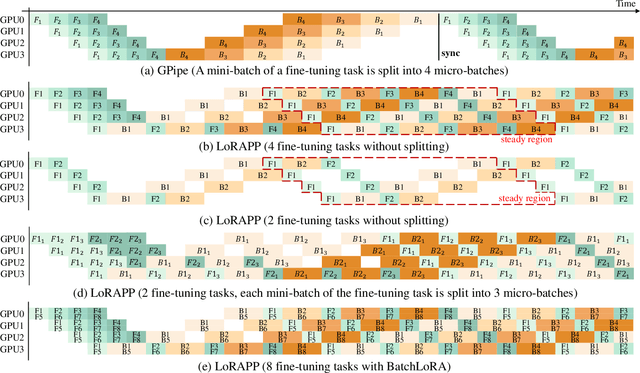
Transformer-based large language models (LLMs) have demonstrated outstanding performance across diverse domains, particularly when fine-turned for specific domains. Recent studies suggest that the resources required for fine-tuning LLMs can be economized through parameter-efficient methods such as Low-Rank Adaptation (LoRA). While LoRA effectively reduces computational burdens and resource demands, it currently supports only a single-job fine-tuning setup. In this paper, we present ASPEN, a high-throughput framework for fine-tuning LLMs. ASPEN efficiently trains multiple jobs on a single GPU using the LoRA method, leveraging shared pre-trained model and adaptive scheduling. ASPEN is compatible with transformer-based language models like LLaMA and ChatGLM, etc. Experiments show that ASPEN saves 53% of GPU memory when training multiple LLaMA-7B models on NVIDIA A100 80GB GPU and boosts training throughput by about 17% compared to existing methods when training with various pre-trained models on different GPUs. The adaptive scheduling algorithm reduces turnaround time by 24%, end-to-end training latency by 12%, prioritizing jobs and preventing out-of-memory issues.