 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFE-Pruner: Semantic Attention-Guided Future-Aware Token Pruning for Efficient Vision-Language-Action Manipulation
May 28, 2026Real-time inference of vision-language-action (VLA) models is essential for robotic control. While visual token pruning has shown strong potential for accelerating inference, most existing methods mainly base pruning decisions on shallow-layer cues and risk discarding visual information required by deep layers. To address this issue, we propose SAFE-Pruner, a plug-and-play pruning framework that incorporates attention cues of future layers into pruning decisions. Specifically, we identify semantic attention consistency, the tendency that VLA models concentrate their attention probability mass on the same semantic entity across execution steps. Based on this observation, we design a forward-looking strategy to forecast the token saliency in deep layers, which prevents the premature removal of critical tokens and leads to more stable acceleration. We further introduce an adaptive subtask division strategy to detect abrupt attention shifts, thereby improving forecasting accuracy and pruning reliability. Extensive experiments in simulation and real-world settings demonstrate that our method achieves up to 1.89x speedup with a minimal degradation in success rate of less than 1.7%, while outperforming state-of-the-art methods by up to 1.9%.
ContextGuard: Structured Self-Auditing for Context Learning in Language Models
May 26, 2026Recent benchmarks reveal that despite strong reasoning capabilities, large language models (LLMs) still struggle to faithfully apply complex contextual knowledge. These failures are often not wholesale reasoning collapses: in context-rich tasks, models may follow the central reasoning path while missing peripheral, persistent, or format-sensitive requirements.
Context-CoT: Enhancing Context Learning via High-Quality Reasoning Synthesis
May 25, 2026While LLMs excel at reasoning over prompts using static pretrained knowledge, they struggle significantly with context learning-the ability to dynamically extract, internalize, and apply new knowledge from complex, task-specific contexts. Recent evaluations on the CL-Bench reveal a critical capability gap: frontier models solve only 17.2% of context-dependent tasks on average.
VISD: Enhancing Video Reasoning via Structured Self-Distillation
May 07, 2026Training VideoLLMs for complex reasoning remains challenging due to sparse sequence level rewards and the lack of fine grained credit assignment over long, temporally grounded reasoning trajectories. While reinforcement learning with verifiable rewards (RLVR) provides reliable supervision, it fails to capture token level contributions, leading to inefficient learning. Conversely, existing self distillation methods offer dense supervision but lack structure and diagnostic specificity, and often interact unstably with reinforcement learning. In this work, we propose VISD, a structured self distillation framework that introduces diagnostically meaningful privileged information for video reasoning. VISD employs a video aware judge model to decompose reasoning quality into multiple dimensions, including answer correctness, logical consistency, and spatio-temporal grounding, and uses this structured feedback to guide a teacher policy for token level supervision. To stably integrate dense supervision with RL, we introduce a direction magnitude decoupling mechanism, where rollout level advantages computed from rewards determine update direction, while structured privileged signals modulate token level update magnitudes. This design enables semantically aligned and fine grained credit assignment, improving both reasoning faithfulness and training efficiency. Additionally, VISD incorporates curriculum scheduling and EMA based teacher stabilization to support robust optimization over long video sequences. Experiments on diverse benchmarks show that VISD consistently outperforms strong baselines, improving answer accuracy and spatio temporal grounding quality. Notably, VISD reaches these gains with nearly 2x faster convergence in optimization steps, highlighting the effectiveness of structured self supervision in improving both performance and sample efficiency for VideoLLMs.
DGPO: Distribution Guided Policy Optimization for Fine Grained Credit Assignment
May 05, 2026Reinforcement learning is crucial for aligning large language models to perform complex reasoning tasks. However, current algorithms such as Group Relative Policy Optimization suffer from coarse grained, sequence level credit assignment, which severely struggles to isolate pivotal reasoning steps within long Chain of Thought generations. Furthermore, the standard unbounded Kullback Leibler divergence penalty induces severe gradient instability and mode seeking conservatism, ultimately stifling the discovery of novel reasoning trajectories. To overcome these limitations, we introduce Distribution Guided Policy Optimization, a novel critic free reinforcement learning framework that reinterprets distribution deviation as a guiding signal rather than a rigid penalty.
DDAVS: Disentangled Audio Semantics and Delayed Bidirectional Alignment for Audio-Visual Segmentation
Dec 23, 2025Audio-Visual Segmentation (AVS) aims to localize sound-producing objects at the pixel level by jointly leveraging auditory and visual information. However, existing methods often suffer from multi-source entanglement and audio-visual misalignment, which lead to biases toward louder or larger objects while overlooking weaker, smaller, or co-occurring sources. To address these challenges, we propose DDAVS, a Disentangled Audio Semantics and Delayed Bidirectional Alignment framework. To mitigate multi-source entanglement, DDAVS employs learnable queries to extract audio semantics and anchor them within a structured semantic space derived from an audio prototype memory bank. This is further optimized through contrastive learning to enhance discriminability and robustness. To alleviate audio-visual misalignment, DDAVS introduces dual cross-attention with delayed modality interaction, improving the robustness of multimodal alignment. Extensive experiments on the AVS-Objects and VPO benchmarks demonstrate that DDAVS consistently outperforms existing approaches, exhibiting strong performance across single-source, multi-source, and multi-instance scenarios. These results validate the effectiveness and generalization ability of our framework under challenging real-world audio-visual segmentation conditions. Project page: https://trilarflagz.github.io/DDAVS-page/
Memorize-and-Generate: Towards Long-Term Consistency in Real-Time Video Generation
Dec 23, 2025Frame-level autoregressive (frame-AR) models have achieved significant progress, enabling real-time video generation comparable to bidirectional diffusion models and serving as a foundation for interactive world models and game engines. However, current approaches in long video generation typically rely on window attention, which naively discards historical context outside the window, leading to catastrophic forgetting and scene inconsistency; conversely, retaining full history incurs prohibitive memory costs. To address this trade-off, we propose Memorize-and-Generate (MAG), a framework that decouples memory compression and frame generation into distinct tasks. Specifically, we train a memory model to compress historical information into a compact KV cache, and a separate generator model to synthesize subsequent frames utilizing this compressed representation. Furthermore, we introduce MAG-Bench to strictly evaluate historical memory retention. Extensive experiments demonstrate that MAG achieves superior historical scene consistency while maintaining competitive performance on standard video generation benchmarks.
Ponder & Press: Advancing Visual GUI Agent towards General Computer Control
Dec 02, 2024Most existing GUI agents typically depend on non-vision inputs like HTML source code or accessibility trees, limiting their flexibility across diverse software environments and platforms. Current multimodal large language models (MLLMs), which excel at using vision to ground real-world objects, offer a potential alternative. However, they often struggle with accurately localizing GUI elements -- a critical requirement for effective GUI automation -- due to the semantic gap between real-world objects and GUI elements. In this work, we introduce Ponder & Press, a divide-and-conquer framework for general computer control using only visual input. Our approach combines an general-purpose MLLM as an 'interpreter', responsible for translating high-level user instructions into detailed action descriptions, with a GUI-specific MLLM as a 'locator' that precisely locates GUI elements for action placement. By leveraging a purely visual input, our agent offers a versatile, human-like interaction paradigm applicable to a wide range of applications. Ponder & Press locator outperforms existing models by +22.5% on the ScreenSpot GUI grounding benchmark. Both offline and interactive agent benchmarks across various GUI environments -- including web pages, desktop software, and mobile UIs -- demonstrate that Ponder & Press framework achieves state-of-the-art performance, highlighting the potential of visual GUI agents. Refer to the project homepage https://invinciblewyq.github.io/ponder-press-page/
ASPEN: High-Throughput LoRA Fine-Tuning of Large Language Models with a Single GPU
Dec 05, 2023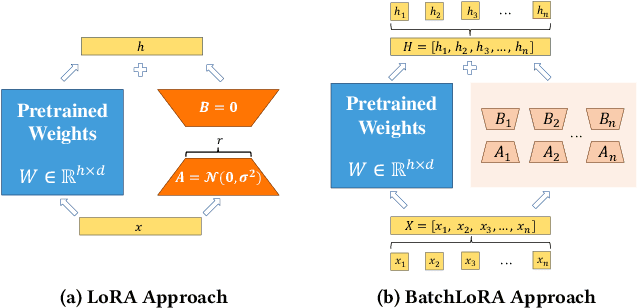
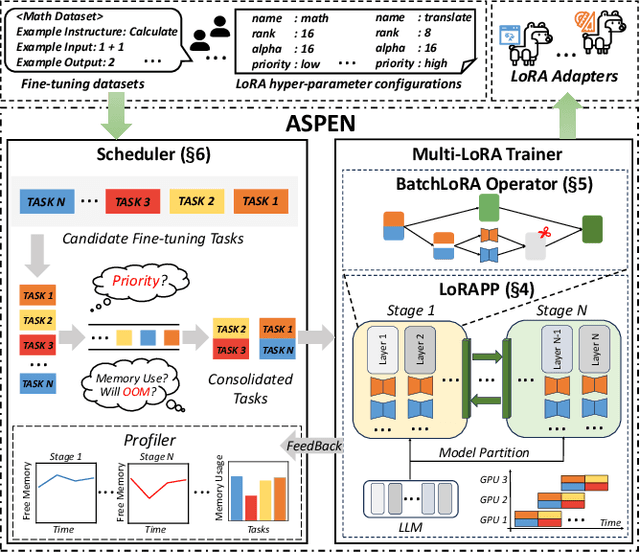
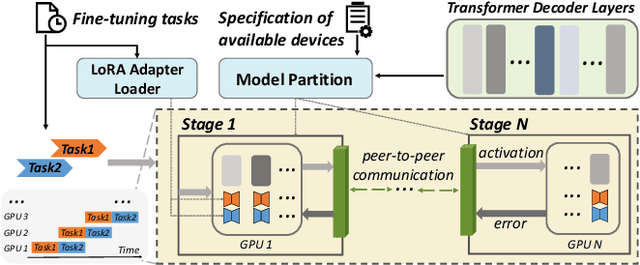
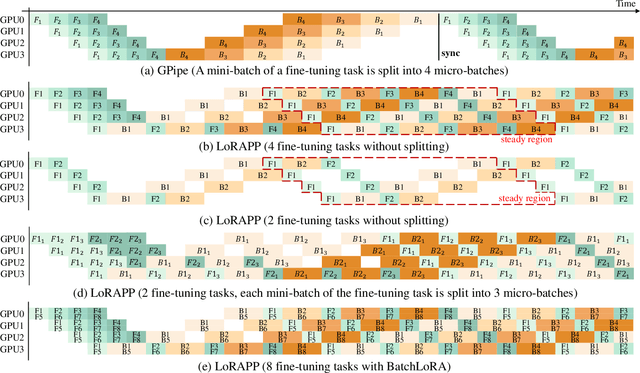
Transformer-based large language models (LLMs) have demonstrated outstanding performance across diverse domains, particularly when fine-turned for specific domains. Recent studies suggest that the resources required for fine-tuning LLMs can be economized through parameter-efficient methods such as Low-Rank Adaptation (LoRA). While LoRA effectively reduces computational burdens and resource demands, it currently supports only a single-job fine-tuning setup. In this paper, we present ASPEN, a high-throughput framework for fine-tuning LLMs. ASPEN efficiently trains multiple jobs on a single GPU using the LoRA method, leveraging shared pre-trained model and adaptive scheduling. ASPEN is compatible with transformer-based language models like LLaMA and ChatGLM, etc. Experiments show that ASPEN saves 53% of GPU memory when training multiple LLaMA-7B models on NVIDIA A100 80GB GPU and boosts training throughput by about 17% compared to existing methods when training with various pre-trained models on different GPUs. The adaptive scheduling algorithm reduces turnaround time by 24%, end-to-end training latency by 12%, prioritizing jobs and preventing out-of-memory issues.