 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCultureScope: A Dimensional Lens for Probing Cultural Understanding in LLMs
Sep 19, 2025As large language models (LLMs) are increasingly deployed in diverse cultural environments, evaluating their cultural understanding capability has become essential for ensuring trustworthy and culturally aligned applications. However, most existing benchmarks lack comprehensiveness and are challenging to scale and adapt across different cultural contexts, because their frameworks often lack guidance from well-established cultural theories and tend to rely on expert-driven manual annotations. To address these issues, we propose CultureScope, the most comprehensive evaluation framework to date for assessing cultural understanding in LLMs. Inspired by the cultural iceberg theory, we design a novel dimensional schema for cultural knowledge classification, comprising 3 layers and 140 dimensions, which guides the automated construction of culture-specific knowledge bases and corresponding evaluation datasets for any given languages and cultures. Experimental results demonstrate that our method can effectively evaluate cultural understanding. They also reveal that existing large language models lack comprehensive cultural competence, and merely incorporating multilingual data does not necessarily enhance cultural understanding. All code and data files are available at https://github.com/HoganZinger/Culture
ESC-Eval: Evaluating Emotion Support Conversations in Large Language Models
Jun 24, 2024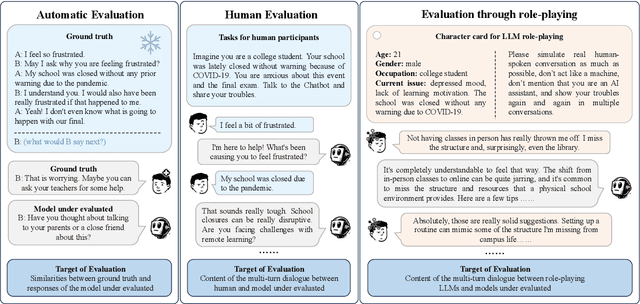
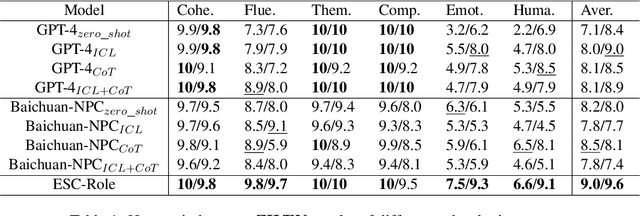
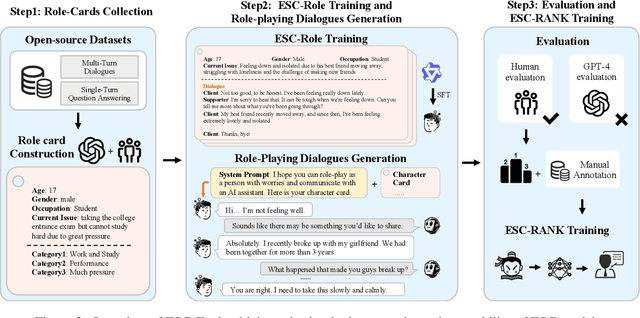
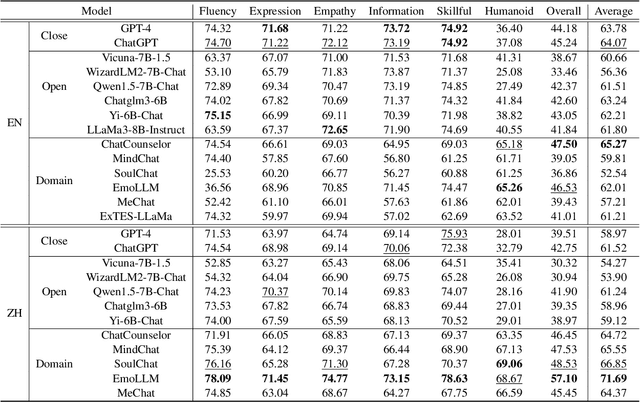
Emotion Support Conversation (ESC) is a crucial application, which aims to reduce human stress, offer emotional guidance, and ultimately enhance human mental and physical well-being. With the advancement of Large Language Models (LLMs), many researchers have employed LLMs as the ESC models. However, the evaluation of these LLM-based ESCs remains uncertain. Inspired by the awesome development of role-playing agents, we propose an ESC Evaluation framework (ESC-Eval), which uses a role-playing agent to interact with ESC models, followed by a manual evaluation of the interactive dialogues. In detail, we first re-organize 2,801 role-playing cards from seven existing datasets to define the roles of the role-playing agent. Second, we train a specific role-playing model called ESC-Role which behaves more like a confused person than GPT-4. Third, through ESC-Role and organized role cards, we systematically conduct experiments using 14 LLMs as the ESC models, including general AI-assistant LLMs (ChatGPT) and ESC-oriented LLMs (ExTES-Llama). We conduct comprehensive human annotations on interactive multi-turn dialogues of different ESC models. The results show that ESC-oriented LLMs exhibit superior ESC abilities compared to general AI-assistant LLMs, but there is still a gap behind human performance. Moreover, to automate the scoring process for future ESC models, we developed ESC-RANK, which trained on the annotated data, achieving a scoring performance surpassing 35 points of GPT-4. Our data and code are available at https://github.com/haidequanbu/ESC-Eval.
Enhancing Confidence Expression in Large Language Models Through Learning from Past Experience
Apr 16, 2024



Large Language Models (LLMs) have exhibited remarkable performance across various downstream tasks, but they may generate inaccurate or false information with a confident tone. One of the possible solutions is to empower the LLM confidence expression capability, in which the confidence expressed can be well-aligned with the true probability of the generated answer being correct. However, leveraging the intrinsic ability of LLMs or the signals from the output logits of answers proves challenging in accurately capturing the response uncertainty in LLMs. Therefore, drawing inspiration from cognitive diagnostics, we propose a method of Learning from Past experience (LePe) to enhance the capability for confidence expression. Specifically, we first identify three key problems: (1) How to capture the inherent confidence of the LLM? (2) How to teach the LLM to express confidence? (3) How to evaluate the confidence expression of the LLM? Then we devise three stages in LePe to deal with these problems. Besides, to accurately capture the confidence of an LLM when constructing the training data, we design a complete pipeline including question preparation and answer sampling. We also conduct experiments using the Llama family of LLMs to verify the effectiveness of our proposed method on four datasets.
OVEL: Large Language Model as Memory Manager for Online Video Entity Linking
Mar 03, 2024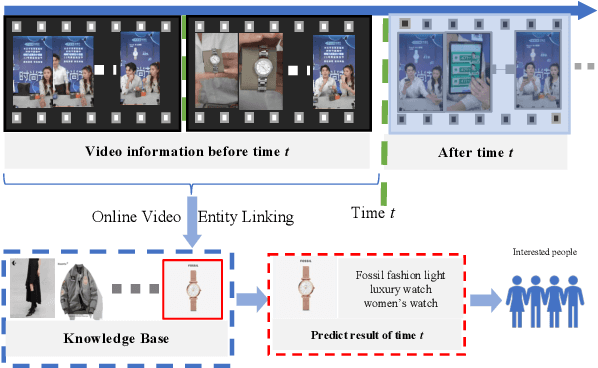
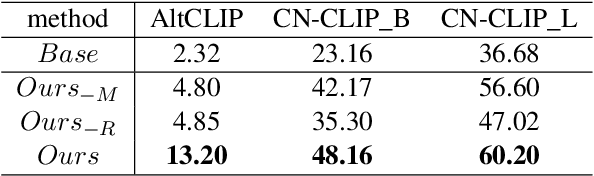
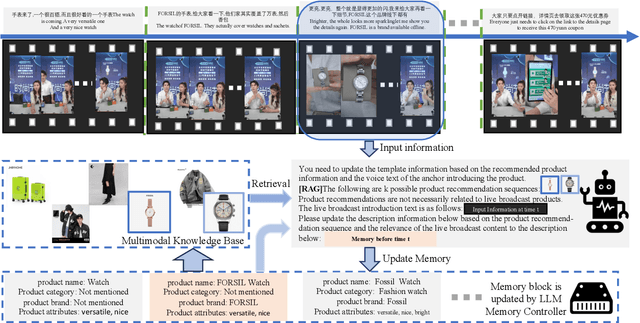
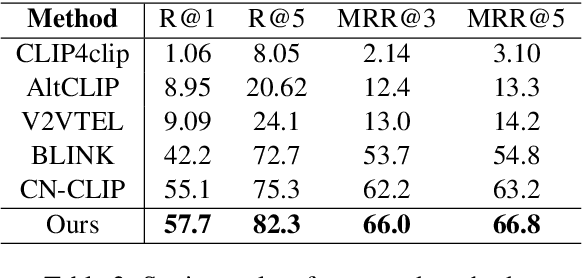
In recent years, multi-modal entity linking (MEL) has garnered increasing attention in the research community due to its significance in numerous multi-modal applications. Video, as a popular means of information transmission, has become prevalent in people's daily lives. However, most existing MEL methods primarily focus on linking textual and visual mentions or offline videos's mentions to entities in multi-modal knowledge bases, with limited efforts devoted to linking mentions within online video content. In this paper, we propose a task called Online Video Entity Linking OVEL, aiming to establish connections between mentions in online videos and a knowledge base with high accuracy and timeliness. To facilitate the research works of OVEL, we specifically concentrate on live delivery scenarios and construct a live delivery entity linking dataset called LIVE. Besides, we propose an evaluation metric that considers timelessness, robustness, and accuracy. Furthermore, to effectively handle OVEL task, we leverage a memory block managed by a Large Language Model and retrieve entity candidates from the knowledge base to augment LLM performance on memory management. The experimental results prove the effectiveness and efficiency of our method.
Can Large Language Models Understand Real-World Complex Instructions?
Sep 17, 2023


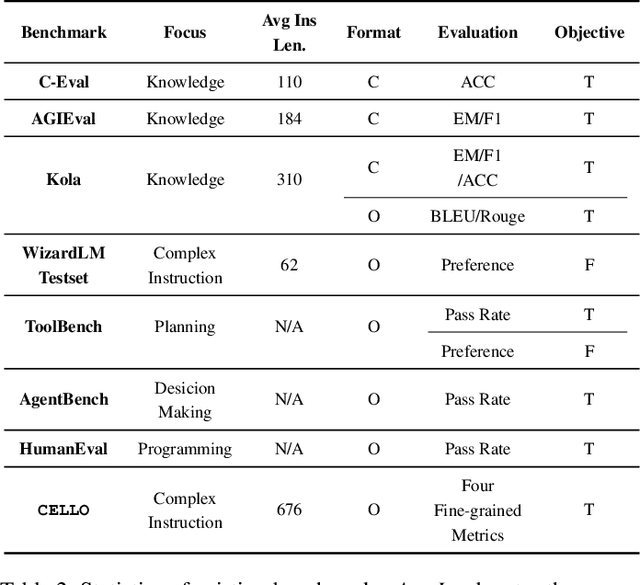
Large language models (LLMs) can understand human instructions, showing their potential for pragmatic applications beyond traditional NLP tasks. However, they still struggle with complex instructions, which can be either complex task descriptions that require multiple tasks and constraints, or complex input that contains long context, noise, heterogeneous information and multi-turn format. Due to these features, LLMs often ignore semantic constraints from task descriptions, generate incorrect formats, violate length or sample count constraints, and be unfaithful to the input text. Existing benchmarks are insufficient to assess LLMs' ability to understand complex instructions, as they are close-ended and simple. To bridge this gap, we propose CELLO, a benchmark for evaluating LLMs' ability to follow complex instructions systematically. We design eight features for complex instructions and construct a comprehensive evaluation dataset from real-world scenarios. We also establish four criteria and develop corresponding metrics, as current ones are inadequate, biased or too strict and coarse-grained. We compare the performance of representative Chinese-oriented and English-oriented models in following complex instructions through extensive experiments. Resources of CELLO are publicly available at https://github.com/Abbey4799/CELLO.