 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProRAG: Process-Supervised Reinforcement Learning for Retrieval-Augmented Generation
Jan 29, 2026Reinforcement learning (RL) has become a promising paradigm for optimizing Retrieval-Augmented Generation (RAG) in complex reasoning tasks. However, traditional outcome-based RL approaches often suffer from reward sparsity and inefficient credit assignment, as coarse-grained scalar rewards fail to identify specific erroneous steps within long-horizon trajectories. This ambiguity frequently leads to "process hallucinations", where models reach correct answers through flawed logic or redundant retrieval steps. Although recent process-aware approaches attempt to mitigate this via static preference learning or heuristic reward shaping, they often lack the on-policy exploration capabilities required to decouple step-level credit from global outcomes. To address these challenges, we propose ProRAG, a process-supervised reinforcement learning framework designed to integrate learned step-level supervision into the online optimization loop. Our framework consists of four stages: (1) Supervised Policy Warmup to initialize the model with a structured reasoning format; (2) construction of an MCTS-based Process Reward Model (PRM) to quantify intermediate reasoning quality; (3) PRM-Guided Reasoning Refinement to align the policy with fine-grained process preferences; and (4) Process-Supervised Reinforcement Learning with a dual-granularity advantage mechanism. By aggregating step-level process rewards with global outcome signals, ProRAG provides precise feedback for every action. Extensive experiments on five multi-hop reasoning benchmarks demonstrate that ProRAG achieves superior overall performance compared to strong outcome-based and process-aware RL baselines, particularly on complex long-horizon tasks, validating the effectiveness of fine-grained process supervision. The code and model are available at https://github.com/lilinwz/ProRAG.
mmE5: Improving Multimodal Multilingual Embeddings via High-quality Synthetic Data
Feb 12, 2025



Multimodal embedding models have gained significant attention for their ability to map data from different modalities, such as text and images, into a unified representation space. However, the limited labeled multimodal data often hinders embedding performance. Recent approaches have leveraged data synthesis to address this problem, yet the quality of synthetic data remains a critical bottleneck. In this work, we identify three criteria for high-quality synthetic multimodal data. First, broad scope ensures that the generated data covers diverse tasks and modalities, making it applicable to various downstream scenarios. Second, robust cross-modal alignment makes different modalities semantically consistent. Third, high fidelity ensures that the synthetic data maintains realistic details to enhance its reliability. Guided by these principles, we synthesize datasets that: (1) cover a wide range of tasks, modality combinations, and languages, (2) are generated via a deep thinking process within a single pass of a multimodal large language model, and (3) incorporate real-world images with accurate and relevant texts, ensuring fidelity through self-evaluation and refinement. Leveraging these high-quality synthetic and labeled datasets, we train a multimodal multilingual E5 model mmE5. Extensive experiments demonstrate that mmE5 achieves state-of-the-art performance on the MMEB Benchmark and superior multilingual performance on the XTD benchmark. Our codes, datasets and models are released in https://github.com/haon-chen/mmE5.
Sliding Windows Are Not the End: Exploring Full Ranking with Long-Context Large Language Models
Dec 19, 2024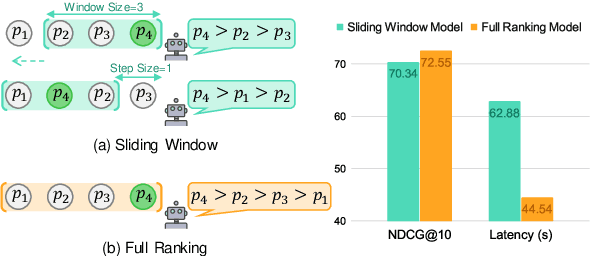
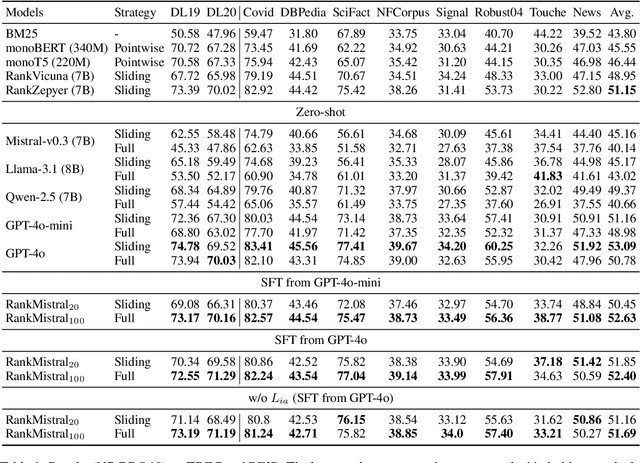
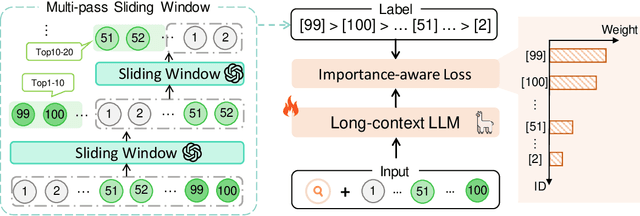
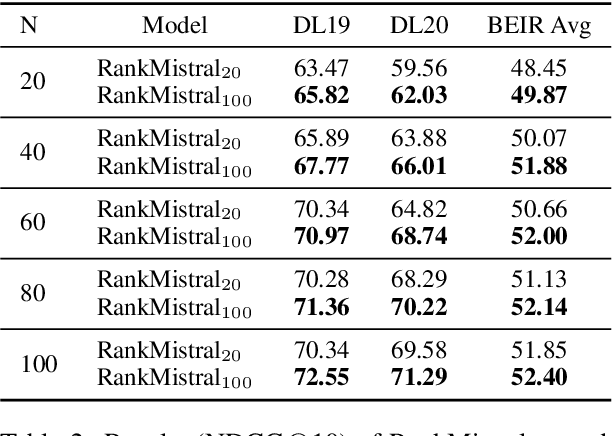
Large Language Models (LLMs) have shown exciting performance in listwise passage ranking. Due to the limited input length, existing methods often adopt the sliding window strategy. Such a strategy, though effective, is inefficient as it involves repetitive and serialized processing, which usually re-evaluates relevant passages multiple times. As a result, it incurs redundant API costs, which are proportional to the number of inference tokens. The development of long-context LLMs enables the full ranking of all passages within a single inference, avoiding redundant API costs. In this paper, we conduct a comprehensive study of long-context LLMs for ranking tasks in terms of efficiency and effectiveness. Surprisingly, our experiments reveal that full ranking with long-context LLMs can deliver superior performance in the supervised fine-tuning setting with a huge efficiency improvement. Furthermore, we identify two limitations of fine-tuning the full ranking model based on existing methods: (1) sliding window strategy fails to produce a full ranking list as a training label, and (2) the language modeling loss cannot emphasize top-ranked passage IDs in the label. To alleviate these issues, we propose a new complete listwise label construction approach and a novel importance-aware learning objective for full ranking. Experiments show the superior performance of our method over baselines. Our codes are available at \url{https://github.com/8421BCD/fullrank}.
CORAL: Benchmarking Multi-turn Conversational Retrieval-Augmentation Generation
Oct 30, 2024



Retrieval-Augmented Generation (RAG) has become a powerful paradigm for enhancing large language models (LLMs) through external knowledge retrieval. Despite its widespread attention, existing academic research predominantly focuses on single-turn RAG, leaving a significant gap in addressing the complexities of multi-turn conversations found in real-world applications. To bridge this gap, we introduce CORAL, a large-scale benchmark designed to assess RAG systems in realistic multi-turn conversational settings. CORAL includes diverse information-seeking conversations automatically derived from Wikipedia and tackles key challenges such as open-domain coverage, knowledge intensity, free-form responses, and topic shifts. It supports three core tasks of conversational RAG: passage retrieval, response generation, and citation labeling. We propose a unified framework to standardize various conversational RAG methods and conduct a comprehensive evaluation of these methods on CORAL, demonstrating substantial opportunities for improving existing approaches.
Little Giants: Synthesizing High-Quality Embedding Data at Scale
Oct 24, 2024Synthetic data generation has become an increasingly popular way of training models without the need for large, manually labeled datasets. For tasks like text embedding, synthetic data offers diverse and scalable training examples, significantly reducing the cost of human annotation. However, most current approaches rely heavily on proprietary models like GPT-4, which are expensive and inefficient for generating large-scale embedding data. In this paper, we introduce SPEED, a framework that aligns open-source small models (8B) to efficiently generate large-scale synthetic embedding data. Through supervised fine-tuning, preference optimization, and self-improvement, SPEED enables small open-source models to produce high-quality data. Remarkably, SPEED uses only less than 1/10 of the GPT API calls, outperforming the state-of-the-art embedding model E5_mistral when both are trained solely on their synthetic data. Using this efficient generator, we conduct a comprehensive study on how various factors within the alignment pipeline impact data quality and reveal the scaling law for synthetic embedding data.
A Survey of Conversational Search
Oct 21, 2024



As a cornerstone of modern information access, search engines have become indispensable in everyday life. With the rapid advancements in AI and natural language processing (NLP) technologies, particularly large language models (LLMs), search engines have evolved to support more intuitive and intelligent interactions between users and systems. Conversational search, an emerging paradigm for next-generation search engines, leverages natural language dialogue to facilitate complex and precise information retrieval, thus attracting significant attention. Unlike traditional keyword-based search engines, conversational search systems enhance user experience by supporting intricate queries, maintaining context over multi-turn interactions, and providing robust information integration and processing capabilities. Key components such as query reformulation, search clarification, conversational retrieval, and response generation work in unison to enable these sophisticated interactions. In this survey, we explore the recent advancements and potential future directions in conversational search, examining the critical modules that constitute a conversational search system. We highlight the integration of LLMs in enhancing these systems and discuss the challenges and opportunities that lie ahead in this dynamic field. Additionally, we provide insights into real-world applications and robust evaluations of current conversational search systems, aiming to guide future research and development in conversational search.
Generalizing Conversational Dense Retrieval via LLM-Cognition Data Augmentation
Feb 19, 2024



Conversational search utilizes muli-turn natural language contexts to retrieve relevant passages. Existing conversational dense retrieval models mostly view a conversation as a fixed sequence of questions and responses, overlooking the severe data sparsity problem -- that is, users can perform a conversation in various ways, and these alternate conversations are unrecorded. Consequently, they often struggle to generalize to diverse conversations in real-world scenarios. In this work, we propose a framework for generalizing Conversational dense retrieval via LLM-cognition data Augmentation (ConvAug). ConvAug first generates multi-level augmented conversations to capture the diverse nature of conversational contexts. Inspired by human cognition, we devise a cognition-aware process to mitigate the generation of false positives, false negatives, and hallucinations. Moreover, we develop a difficulty-adaptive sample filter that selects challenging samples for complex conversations, thereby giving the model a larger learning space. A contrastive learning objective is then employed to train a better conversational context encoder. Extensive experiments conducted on four public datasets, under both normal and zero-shot settings, demonstrate the effectiveness, generalizability, and applicability of ConvAug.
GReS: Graphical Cross-domain Recommendation for Supply Chain Platform
Sep 02, 2022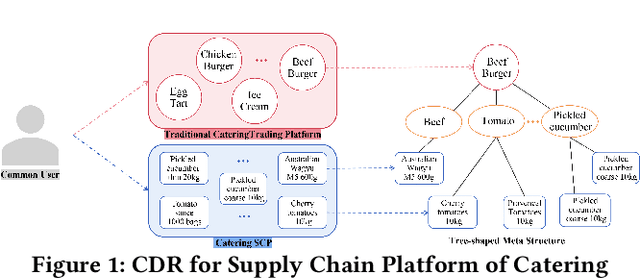
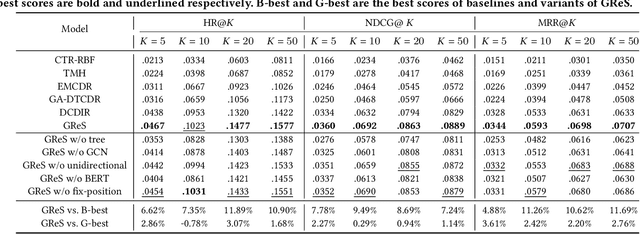
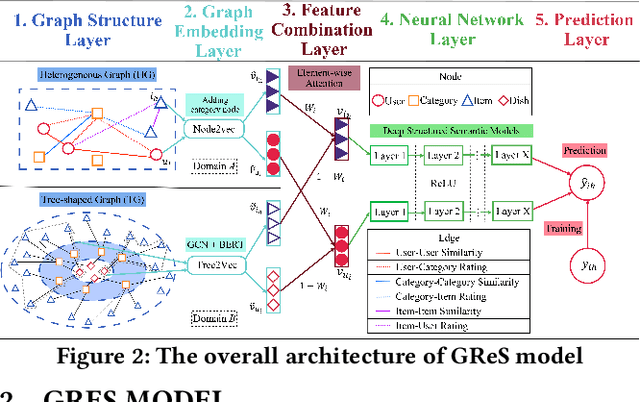
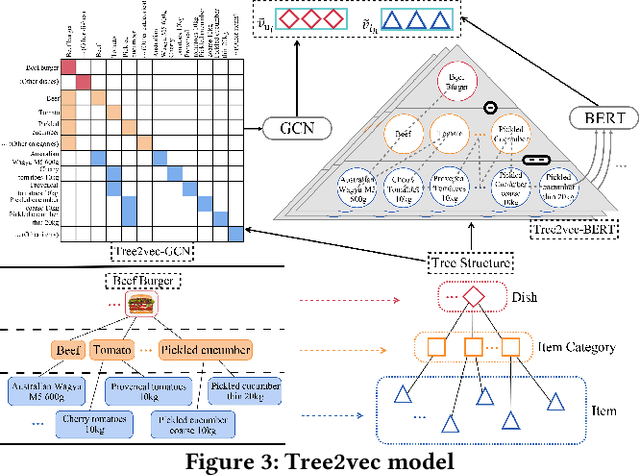
Supply Chain Platforms (SCPs) provide downstream industries with numerous raw materials. Compared with traditional e-commerce platforms, data in SCPs is more sparse due to limited user interests. To tackle the data sparsity problem, one can apply Cross-Domain Recommendation (CDR) which improves the recommendation performance of the target domain with the source domain information. However, applying CDR to SCPs directly ignores the hierarchical structure of commodities in SCPs, which reduce the recommendation performance. To leverage this feature, in this paper, we take the catering platform as an example and propose GReS, a graphical cross-domain recommendation model. The model first constructs a tree-shaped graph to represent the hierarchy of different nodes of dishes and ingredients, and then applies our proposed Tree2vec method combining GCN and BERT models to embed the graph for recommendations. Experimental results on a commercial dataset show that GReS significantly outperforms state-of-the-art methods in Cross-Domain Recommendation for Supply Chain Platforms.