 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniGist: Towards General and Hardware-aligned Sequence-level Long Context Compression
Sep 19, 2025Large language models are increasingly capable of handling long-context inputs, but the memory overhead of key-value (KV) cache remains a major bottleneck for general-purpose deployment. While various compression strategies have been explored, sequence-level compression, which drops the full KV caches for certain tokens, is particularly challenging as it can lead to the loss of important contextual information. To address this, we introduce UniGist, a sequence-level long-context compression framework that efficiently preserves context information by replacing raw tokens with special compression tokens (gists) in a fine-grained manner. We adopt a chunk-free training strategy and design an efficient kernel with a gist shift trick, enabling optimized GPU training. Our scheme also supports flexible inference by allowing the actual removal of compressed tokens, resulting in real-time memory savings. Experiments across multiple long-context tasks demonstrate that UniGist significantly improves compression quality, with especially strong performance in detail-recalling tasks and long-range dependency modeling.
InComeS: Integrating Compression and Selection Mechanisms into LLMs for Efficient Model Editing
May 28, 2025Although existing model editing methods perform well in recalling exact edit facts, they often struggle in complex scenarios that require deeper semantic understanding rather than mere knowledge regurgitation. Leveraging the strong contextual reasoning abilities of large language models (LLMs), in-context learning (ICL) becomes a promising editing method by comprehending edit information through context encoding. However, this method is constrained by the limited context window of LLMs, leading to degraded performance and efficiency as the number of edits increases. To overcome this limitation, we propose InComeS, a flexible framework that enhances LLMs' ability to process editing contexts through explicit compression and selection mechanisms. Specifically, InComeS compresses each editing context into the key-value (KV) cache of a special gist token, enabling efficient handling of multiple edits without being restricted by the model's context window. Furthermore, specialized cross-attention modules are added to dynamically select the most relevant information from the gist pools, enabling adaptive and effective utilization of edit information. We conduct experiments on diverse model editing benchmarks with various editing formats, and the results demonstrate the effectiveness and efficiency of our method.
A Silver Bullet or a Compromise for Full Attention? A Comprehensive Study of Gist Token-based Context Compression
Dec 23, 2024



In this work, we provide a thorough investigation of gist-based context compression methods to improve long-context processing in large language models. We focus on two key questions: (1) How well can these methods replace full attention models? and (2) What potential failure patterns arise due to compression? Through extensive experiments, we show that while gist-based compression can achieve near-lossless performance on tasks like retrieval-augmented generation and long-document QA, it faces challenges in tasks like synthetic recall. Furthermore, we identify three key failure patterns: lost by the boundary, lost if surprise, and lost along the way. To mitigate these issues, we propose two effective strategies: fine-grained autoencoding, which enhances the reconstruction of original token information, and segment-wise token importance estimation, which adjusts optimization based on token dependencies. Our work provides valuable insights into the understanding of gist token-based context compression and offers practical strategies for improving compression capabilities.
Attention Entropy is a Key Factor: An Analysis of Parallel Context Encoding with Full-attention-based Pre-trained Language Models
Dec 21, 2024



Large language models have shown remarkable performance across a wide range of language tasks, owing to their exceptional capabilities in context modeling. The most commonly used method of context modeling is full self-attention, as seen in standard decoder-only Transformers. Although powerful, this method can be inefficient for long sequences and may overlook inherent input structures. To address these problems, an alternative approach is parallel context encoding, which splits the context into sub-pieces and encodes them parallelly. Because parallel patterns are not encountered during training, naively applying parallel encoding leads to performance degradation. However, the underlying reasons and potential mitigations are unclear. In this work, we provide a detailed analysis of this issue and identify that unusually high attention entropy can be a key factor. Furthermore, we adopt two straightforward methods to reduce attention entropy by incorporating attention sinks and selective mechanisms. Experiments on various tasks reveal that these methods effectively lower irregular attention entropy and narrow performance gaps. We hope this study can illuminate ways to enhance context modeling mechanisms.
Enabling Discriminative Reasoning in LLMs for Legal Judgment Prediction
Jul 03, 2024



Legal judgment prediction is essential for enhancing judicial efficiency. In this work, we identify that existing large language models (LLMs) underperform in this domain due to challenges in understanding case complexities and distinguishing between similar charges. To adapt LLMs for effective legal judgment prediction, we introduce the Ask-Discriminate-Predict (ADAPT) reasoning framework inspired by human judicial reasoning. ADAPT involves decomposing case facts, discriminating among potential charges, and predicting the final judgment. We further enhance LLMs through fine-tuning with multi-task synthetic trajectories to improve legal judgment prediction accuracy and efficiency under our ADAPT framework. Extensive experiments conducted on two widely-used datasets demonstrate the superior performance of our framework in legal judgment prediction, particularly when dealing with complex and confusing charges.
Enabling Discriminative Reasoning in Large Language Models for Legal Judgment Prediction
Jul 02, 2024Legal judgment prediction is essential for enhancing judicial efficiency. In this work, we identify that existing large language models (LLMs) underperform in this domain due to challenges in understanding case complexities and distinguishing between similar charges. To adapt LLMs for effective legal judgment prediction, we introduce the Ask-Discriminate-Predict (ADAPT) reasoning framework inspired by human judicial reasoning. ADAPT involves decomposing case facts, discriminating among potential charges, and predicting the final judgment. We further enhance LLMs through fine-tuning with multi-task synthetic trajectories to improve legal judgment prediction accuracy and efficiency under our ADAPT framework. Extensive experiments conducted on two widely-used datasets demonstrate the superior performance of our framework in legal judgment prediction, particularly when dealing with complex and confusing charges.
Learning Interpretable Legal Case Retrieval via Knowledge-Guided Case Reformulation
Jun 28, 2024



Legal case retrieval for sourcing similar cases is critical in upholding judicial fairness. Different from general web search, legal case retrieval involves processing lengthy, complex, and highly specialized legal documents. Existing methods in this domain often overlook the incorporation of legal expert knowledge, which is crucial for accurately understanding and modeling legal cases, leading to unsatisfactory retrieval performance. This paper introduces KELLER, a legal knowledge-guided case reformulation approach based on large language models (LLMs) for effective and interpretable legal case retrieval. By incorporating professional legal knowledge about crimes and law articles, we enable large language models to accurately reformulate the original legal case into concise sub-facts of crimes, which contain the essential information of the case. Extensive experiments on two legal case retrieval benchmarks demonstrate superior retrieval performance and robustness on complex legal case queries of KELLER over existing methods.
ChatRetriever: Adapting Large Language Models for Generalized and Robust Conversational Dense Retrieval
Apr 21, 2024Conversational search requires accurate interpretation of user intent from complex multi-turn contexts. This paper presents ChatRetriever, which inherits the strong generalization capability of large language models to robustly represent complex conversational sessions for dense retrieval. To achieve this, we propose a simple and effective dual-learning approach that adapts LLM for retrieval via contrastive learning while enhancing the complex session understanding through masked instruction tuning on high-quality conversational instruction tuning data. Extensive experiments on five conversational search benchmarks demonstrate that ChatRetriever substantially outperforms existing conversational dense retrievers, achieving state-of-the-art performance on par with LLM-based rewriting approaches. Furthermore, ChatRetriever exhibits superior robustness in handling diverse conversational contexts. Our work highlights the potential of adapting LLMs for retrieval with complex inputs like conversational search sessions and proposes an effective approach to advance this research direction.
Large Language Models for Information Retrieval: A Survey
Aug 15, 2023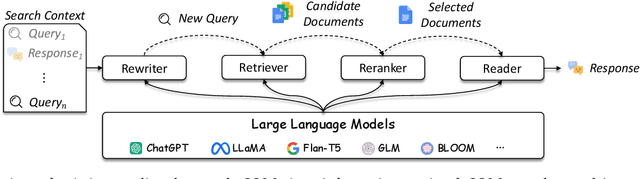
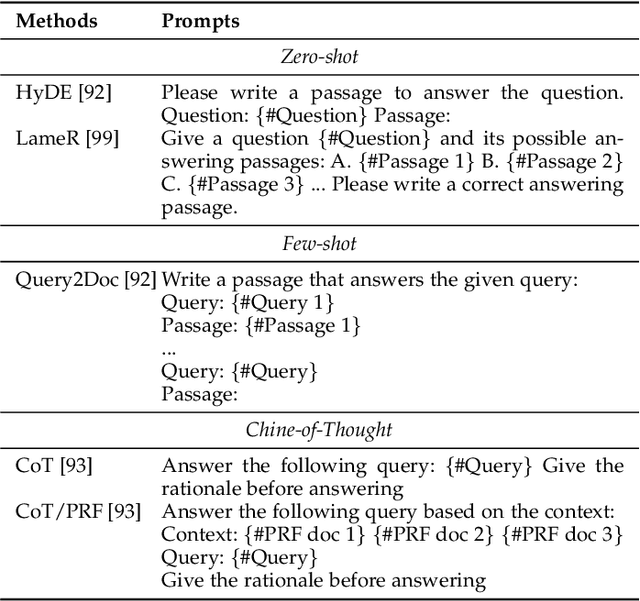
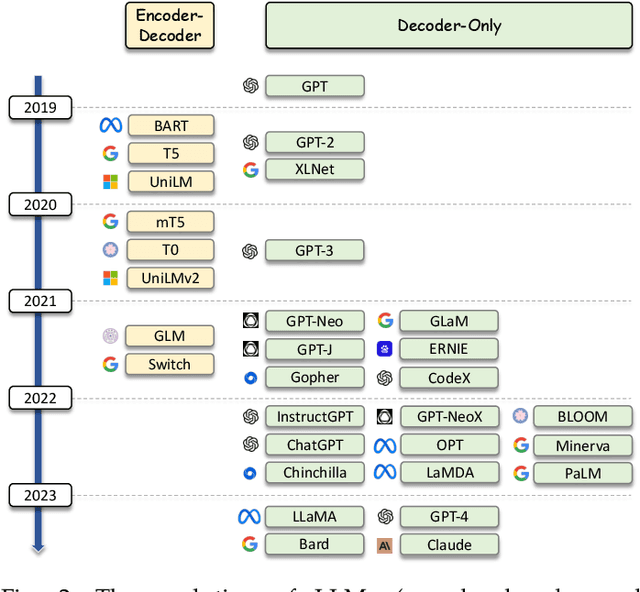
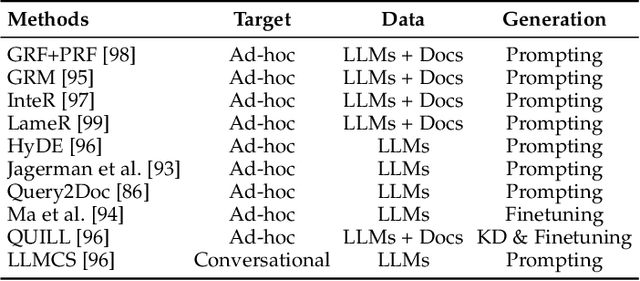
As a primary means of information acquisition, information retrieval (IR) systems, such as search engines, have integrated themselves into our daily lives. These systems also serve as components of dialogue, question-answering, and recommender systems. The trajectory of IR has evolved dynamically from its origins in term-based methods to its integration with advanced neural models. While the neural models excel at capturing complex contextual signals and semantic nuances, thereby reshaping the IR landscape, they still face challenges such as data scarcity, interpretability, and the generation of contextually plausible yet potentially inaccurate responses. This evolution requires a combination of both traditional methods (such as term-based sparse retrieval methods with rapid response) and modern neural architectures (such as language models with powerful language understanding capacity). Meanwhile, the emergence of large language models (LLMs), typified by ChatGPT and GPT-4, has revolutionized natural language processing due to their remarkable language understanding, generation, generalization, and reasoning abilities. Consequently, recent research has sought to leverage LLMs to improve IR systems. Given the rapid evolution of this research trajectory, it is necessary to consolidate existing methodologies and provide nuanced insights through a comprehensive overview. In this survey, we delve into the confluence of LLMs and IR systems, including crucial aspects such as query rewriters, retrievers, rerankers, and readers. Additionally, we explore promising directions within this expanding field.