 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFleximo: Towards Flexible Text-to-Human Motion Video Generation
Paper and Code
Nov 29, 2024
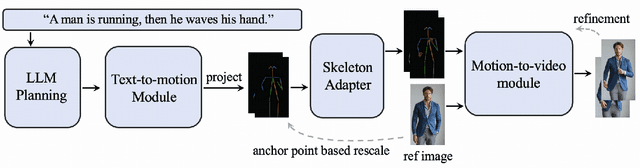


Current methods for generating human motion videos rely on extracting pose sequences from reference videos, which restricts flexibility and control. Additionally, due to the limitations of pose detection techniques, the extracted pose sequences can sometimes be inaccurate, leading to low-quality video outputs. We introduce a novel task aimed at generating human motion videos solely from reference images and natural language. This approach offers greater flexibility and ease of use, as text is more accessible than the desired guidance videos. However, training an end-to-end model for this task requires millions of high-quality text and human motion video pairs, which are challenging to obtain. To address this, we propose a new framework called Fleximo, which leverages large-scale pre-trained text-to-3D motion models. This approach is not straightforward, as the text-generated skeletons may not consistently match the scale of the reference image and may lack detailed information. To overcome these challenges, we introduce an anchor point based rescale method and design a skeleton adapter to fill in missing details and bridge the gap between text-to-motion and motion-to-video generation. We also propose a video refinement process to further enhance video quality. A large language model (LLM) is employed to decompose natural language into discrete motion sequences, enabling the generation of motion videos of any desired length. To assess the performance of Fleximo, we introduce a new benchmark called MotionBench, which includes 400 videos across 20 identities and 20 motions. We also propose a new metric, MotionScore, to evaluate the accuracy of motion following. Both qualitative and quantitative results demonstrate that our method outperforms existing text-conditioned image-to-video generation methods. All code and model weights will be made publicly available.