 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Jun 04, 2024



In the age of large-scale language models, benchmarks like the Massive Multitask Language Understanding (MMLU) have been pivotal in pushing the boundaries of what AI can achieve in language comprehension and reasoning across diverse domains. However, as models continue to improve, their performance on these benchmarks has begun to plateau, making it increasingly difficult to discern differences in model capabilities. This paper introduces MMLU-Pro, an enhanced dataset designed to extend the mostly knowledge-driven MMLU benchmark by integrating more challenging, reasoning-focused questions and expanding the choice set from four to ten options. Additionally, MMLU-Pro eliminates the trivial and noisy questions in MMLU. Our experimental results show that MMLU-Pro not only raises the challenge, causing a significant drop in accuracy by 16% to 33% compared to MMLU but also demonstrates greater stability under varying prompts. With 24 different prompt styles tested, the sensitivity of model scores to prompt variations decreased from 4-5% in MMLU to just 2% in MMLU-Pro. Additionally, we found that models utilizing Chain of Thought (CoT) reasoning achieved better performance on MMLU-Pro compared to direct answering, which is in stark contrast to the findings on the original MMLU, indicating that MMLU-Pro includes more complex reasoning questions. Our assessments confirm that MMLU-Pro is a more discriminative benchmark to better track progress in the field.
StructLM: Towards Building Generalist Models for Structured Knowledge Grounding
Feb 28, 2024Structured data sources, such as tables, graphs, and databases, are ubiquitous knowledge sources. Despite the demonstrated capabilities of large language models (LLMs) on plain text, their proficiency in interpreting and utilizing structured data remains limited. Our investigation reveals a notable deficiency in LLMs' ability to process structured data, e.g., ChatGPT lags behind state-of-the-art (SoTA) model by an average of 35%. To augment the Structured Knowledge Grounding (SKG) capabilities in LLMs, we have developed a comprehensive instruction tuning dataset comprising 1.1 million examples. Utilizing this dataset, we train a series of models, referred to as StructLM, based on the Code-LLaMA architecture, ranging from 7B to 34B parameters. Our StructLM series surpasses task-specific models on 14 out of 18 evaluated datasets and establishes new SoTA achievements on 7 SKG tasks. Furthermore, StructLM demonstrates exceptional generalization across 6 novel SKG tasks. Contrary to expectations, we observe that scaling model size offers marginal benefits, with StructLM-34B showing only slight improvements over StructLM-7B. This suggests that structured knowledge grounding is still a challenging task and requires more innovative design to push to a new level.
Few-shot In-context Learning for Knowledge Base Question Answering
May 04, 2023



Question answering over knowledge bases is considered a difficult problem due to the challenge of generalizing to a wide variety of possible natural language questions. Additionally, the heterogeneity of knowledge base schema items between different knowledge bases often necessitates specialized training for different knowledge base question-answering (KBQA) datasets. To handle questions over diverse KBQA datasets with a unified training-free framework, we propose KB-BINDER, which for the first time enables few-shot in-context learning over KBQA tasks. Firstly, KB-BINDER leverages large language models like Codex to generate logical forms as the draft for a specific question by imitating a few demonstrations. Secondly, KB-BINDER grounds on the knowledge base to bind the generated draft to an executable one with BM25 score matching. The experimental results on four public heterogeneous KBQA datasets show that KB-BINDER can achieve a strong performance with only a few in-context demonstrations. Especially on GraphQA and 3-hop MetaQA, KB-BINDER can even outperform the state-of-the-art trained models. On GrailQA and WebQSP, our model is also on par with other fully-trained models. We believe KB-BINDER can serve as an important baseline for future research. Our code is available at https://github.com/ltl3A87/KB-BINDER.
RADACS: Towards Higher-Order Reasoning using Action Recognition in Autonomous Vehicles
Sep 28, 2022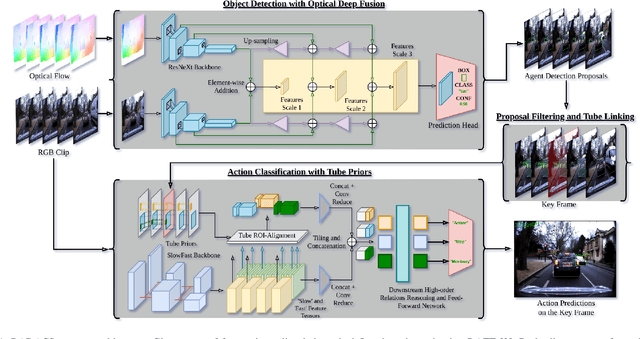
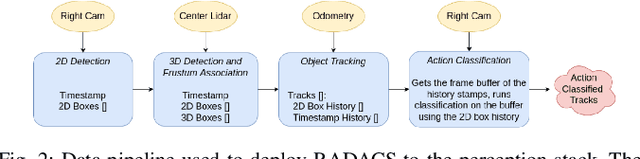


When applied to autonomous vehicle settings, action recognition can help enrich an environment model's understanding of the world and improve plans for future action. Towards these improvements in autonomous vehicle decision-making, we propose in this work a novel two-stage online action recognition system, termed RADACS. RADACS formulates the problem of active agent detection and adapts ideas about actor-context relations from human activity recognition in a straightforward two-stage pipeline for action detection and classification. We show that our proposed scheme can outperform the baseline on the ICCV2021 Road Challenge dataset and by deploying it on a real vehicle platform, we demonstrate how a higher-order understanding of agent actions in an environment can improve decisions on a real autonomous vehicle.
Counting Fish and Dolphins in Sonar Images Using Deep Learning
Jul 24, 2020
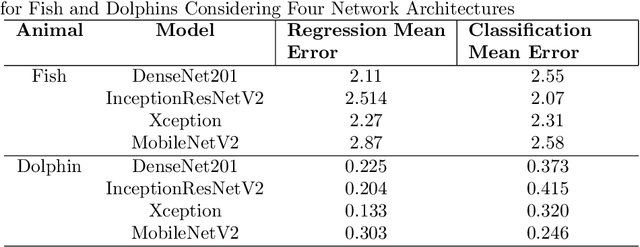


Deep learning provides the opportunity to improve upon conflicting reports considering the relationship between the Amazon river's fish and dolphin abundance and reduced canopy cover as a result of deforestation. Current methods of fish and dolphin abundance estimates are performed by on-site sampling using visual and capture/release strategies. We propose a novel approach to calculating fish abundance using deep learning for fish and dolphin estimates from sonar images taken from the back of a trolling boat. We consider a data set of 143 images ranging from 0-34 fish, and 0-3 dolphins provided by the Fund Amazonia research group. To overcome the data limitation, we test the capabilities of data augmentation on an unconventional 15/85 training/testing split. Using 20 training images, we simulate a gradient of data up to 25,000 images using augmented backgrounds and randomly placed/rotation cropped fish and dolphin taken from the training set. We then train four multitask network architectures: DenseNet201, InceptionNetV2, Xception, and MobileNetV2 to predict fish and dolphin numbers using two function approximation methods: regression and classification. For regression, Densenet201 performed best for fish and Xception best for dolphin with mean squared errors of 2.11 and 0.133 respectively. For classification, InceptionResNetV2 performed best for fish and MobileNetV2 best for dolphins with a mean error of 2.07 and 0.245 respectively. Considering the 123 testing images, our results show the success of data simulation for limited sonar data sets. We find DenseNet201 is able to identify dolphins after approximately 5000 training images, while fish required the full 25,000. Our method can be used to lower costs and expedite the data analysis of fish and dolphin abundance to real-time along the Amazon river and river systems worldwide.