 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Angular Received-Power Characterization of Embedded mmWave Transmitters Using Geometry-Calibrated Spatial Sampling
Jan 18, 2026This paper presents an automated measurement methodology for angular received-power characterization of embedded millimeter-wave transmitters using geometry-calibrated spatial sampling. Characterization of integrated mmWave transmitters remains challenging due to limited angular coverage and alignment variability in conventional probe-station techniques, as well as the impracticality of anechoic-chamber testing for platform-mounted active modules. To address these challenges, we introduce RAPTAR, an autonomous measurement system for angular received-power acquisition under realistic installation constraints. A collaborative robot executes geometry-calibrated, collision-aware hemispherical trajectories while carrying a calibrated receive probe, enabling controlled and repeatable spatial positioning around a fixed device under test. A spectrum-analyzer-based receiver chain acquires amplitude-only received power as a function of angle and distance following quasi-static pose stabilization. The proposed framework enables repeatable angular received-power mapping and power-domain comparison against idealized free-space references derived from full-wave simulation. Experimental results for a 60-GHz radar module demonstrate a mean absolute received-power error below 2 dB relative to simulation-derived references and a 36.5 % reduction in error compared to manual probe-station measurements, attributed primarily to reduced alignment variability and consistent spatial sampling. The proposed method eliminates the need for coherent field measurements and near-field transformations, enabling practical power-domain characterization of embedded mmWave modules. It is well suited for angular validation in real-world platforms where conventional anechoic measurements are impractical.
RAPTAR: Radar Radiation Pattern Acquisition through Automated Collaborative Robotics
Jul 22, 2025Accurate characterization of modern on-chip antennas remains challenging, as current probe-station techniques offer limited angular coverage, rely on bespoke hardware, and require frequent manual alignment. This research introduces RAPTAR (Radiation Pattern Acquisition through Robotic Automation), a portable, state-of-the-art, and autonomous system based on collaborative robotics. RAPTAR enables 3D radiation-pattern measurement of integrated radar modules without dedicated anechoic facilities. The system is designed to address the challenges of testing radar modules mounted in diverse real-world configurations, including vehicles, UAVs, AR/VR headsets, and biomedical devices, where traditional measurement setups are impractical. A 7-degree-of-freedom Franka cobot holds the receiver probe and performs collision-free manipulation across a hemispherical spatial domain, guided by real-time motion planning and calibration accuracy with RMS error below 0.9 mm. The system achieves an angular resolution upto 2.5 degree and integrates seamlessly with RF instrumentation for near- and far-field power measurements. Experimental scans of a 60 GHz radar module show a mean absolute error of less than 2 dB compared to full-wave electromagnetic simulations ground truth. Benchmarking against baseline method demonstrates 36.5% lower mean absolute error, highlighting RAPTAR accuracy and repeatability.
* 8 Pages, IEEE Journal
Learning Skateboarding for Humanoid Robots through Massively Parallel Reinforcement Learning
Sep 12, 2024

Learning-based methods have proven useful at generating complex motions for robots, including humanoids. Reinforcement learning (RL) has been used to learn locomotion policies, some of which leverage a periodic reward formulation. This work extends the periodic reward formulation of locomotion to skateboarding for the REEM-C robot. Brax/MJX is used to implement the RL problem to achieve fast training. Initial results in simulation are presented with hardware experiments in progress.
Learning Velocity-based Humanoid Locomotion: Massively Parallel Learning with Brax and MJX
Jul 06, 2024


Humanoid locomotion is a key skill to bring humanoids out of the lab and into the real-world. Many motion generation methods for locomotion have been proposed including reinforcement learning (RL). RL locomotion policies offer great versatility and generalizability along with the ability to experience new knowledge to improve over time. This work presents a velocity-based RL locomotion policy for the REEM-C robot. The policy uses a periodic reward formulation and is implemented in Brax/MJX for fast training. Simulation results for the policy are demonstrated with future experimental results in progress.
5G Virtual Reality Manipulator Teleoperation using a Mobile Phone
May 12, 2024This paper presents an approach to teleoperate a manipulator using a mobile phone as a leader device. Using its IMU and camera, the phone estimates its Cartesian pose which is then used to to control the Cartesian pose of the robot's tool. The user receives visual feedback in the form of multi-view video - a point cloud rendered in a virtual reality environment. This enables the user to observe the scene from any position. To increase immersion, the robot's estimate of external forces is relayed using the phone's haptic actuator. Leader and follower are connected through wireless networks such as 5G or Wi-Fi. The paper describes the setup and analyzes its performance.
RADACS: Towards Higher-Order Reasoning using Action Recognition in Autonomous Vehicles
Sep 28, 2022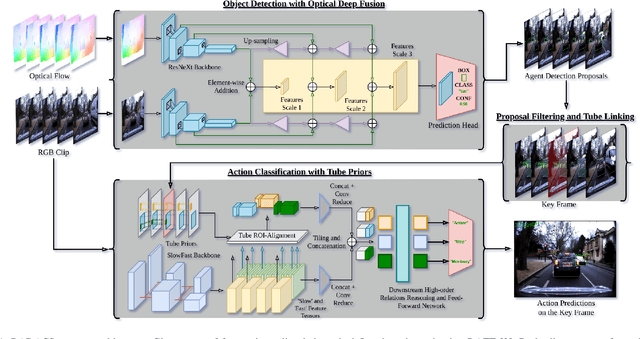
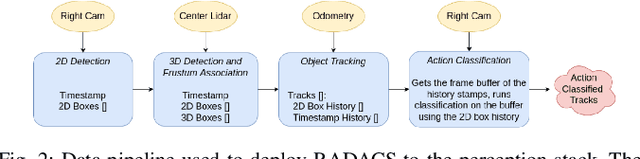


When applied to autonomous vehicle settings, action recognition can help enrich an environment model's understanding of the world and improve plans for future action. Towards these improvements in autonomous vehicle decision-making, we propose in this work a novel two-stage online action recognition system, termed RADACS. RADACS formulates the problem of active agent detection and adapts ideas about actor-context relations from human activity recognition in a straightforward two-stage pipeline for action detection and classification. We show that our proposed scheme can outperform the baseline on the ICCV2021 Road Challenge dataset and by deploying it on a real vehicle platform, we demonstrate how a higher-order understanding of agent actions in an environment can improve decisions on a real autonomous vehicle.
Real-Time Unified Trajectory Planning and Optimal Control for Urban Autonomous Driving Under Static and Dynamic Obstacle Constraints
Sep 19, 2022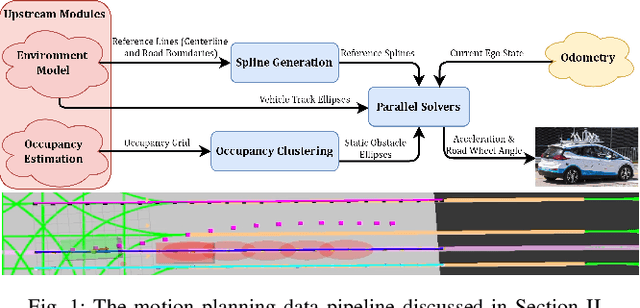
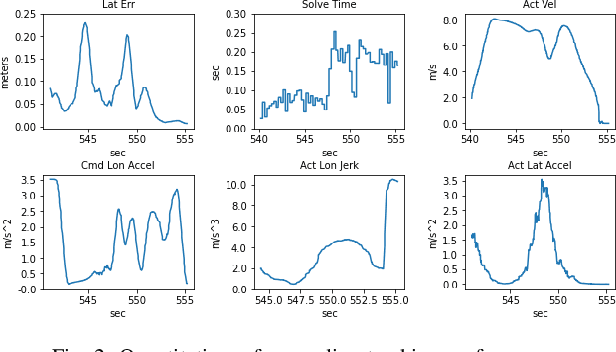
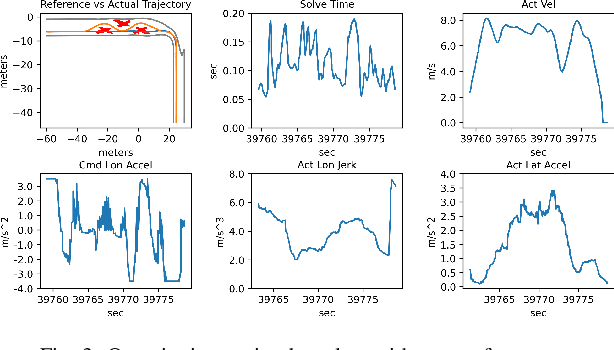
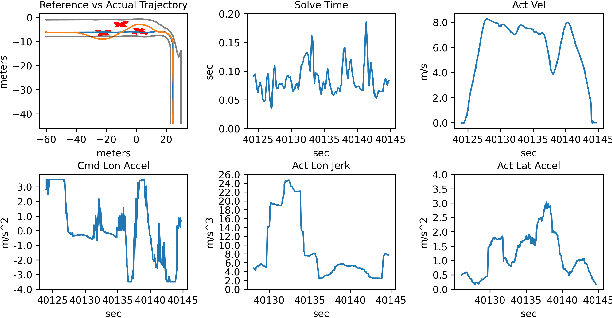
Trajectory planning and control have historically been separated into two modules in automated driving stacks. Trajectory planning focuses on higher-level tasks like avoiding obstacles and staying on the road surface, whereas the controller tries its best to follow an ever changing reference trajectory. We argue that this separation is (1) flawed due to the mismatch between planned trajectories and what the controller can feasibly execute, and (2) unnecessary due to the flexibility of the model predictive control (MPC) paradigm. Instead, in this paper, we present a unified MPC-based trajectory planning and control scheme that guarantees feasibility with respect to road boundaries, the static and dynamic environment, and enforces passenger comfort constraints. The scheme is evaluated rigorously in a variety of scenarios focused on proving the effectiveness of the optimal control problem (OCP) design and real-time solution methods. The prototype code will be released at https://github.com/WATonomous/control.
Sim-to-Real Domain Adaptation for Lane Detection and Classification in Autonomous Driving
Feb 15, 2022


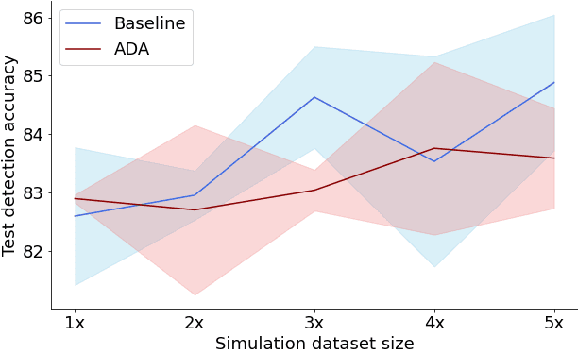
While supervised detection and classification frameworks in autonomous driving require large labelled datasets to converge, Unsupervised Domain Adaptation (UDA) approaches, facilitated by synthetic data generated from photo-real simulated environments, are considered low-cost and less time-consuming solutions. In this paper, we propose UDA schemes using adversarial discriminative and generative methods for lane detection and classification applications in autonomous driving. We also present Simulanes dataset generator to create a synthetic dataset that is naturalistic utilizing CARLA's vast traffic scenarios and weather conditions. The proposed UDA frameworks take the synthesized dataset with labels as the source domain, whereas the target domain is the unlabelled real-world data. Using adversarial generative and feature discriminators, the learnt models are tuned to predict the lane location and class in the target domain. The proposed techniques are evaluated using both real-world and our synthetic datasets. The results manifest that the proposed methods have shown superiority over other baseline schemes in terms of detection and classification accuracy and consistency. The ablation study reveals that the size of the simulation dataset plays important roles in the classification performance of the proposed methods. Our UDA frameworks are available at https://github.com/anita-hu/sim2real-lane-detection and our dataset generator is released at https://github.com/anita-hu/simulanes
End-Effector Stabilization of a 10-DOF Mobile Manipulator using Nonlinear Model Predictive Control
Mar 24, 2021
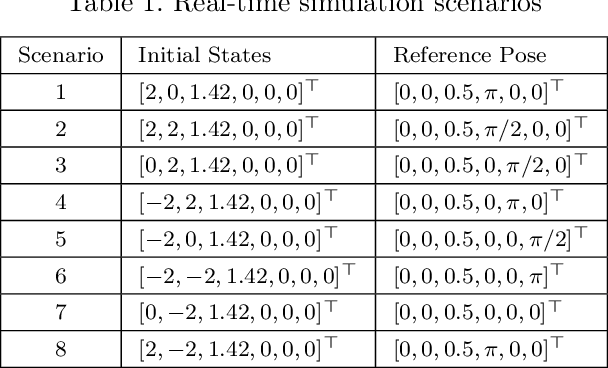
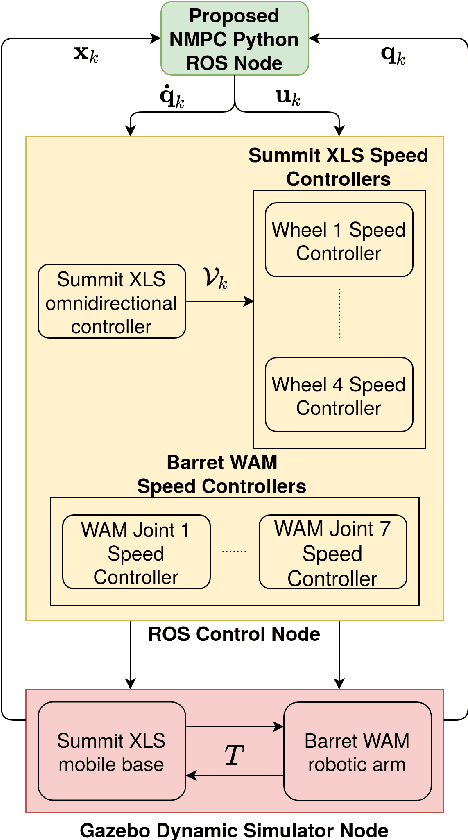
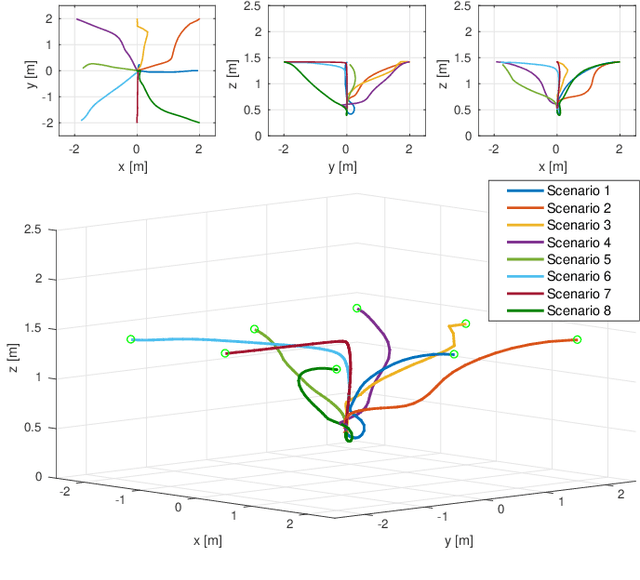
Motion control of mobile manipulators (a robotic arm mounted on a mobile base) can be challenging for complex tasks such as material and package handling. In this paper, a task-space stabilization controller based on Nonlinear Model Predictive Control (NMPC) is designed and implemented to a 10 Degrees of Freedom (DOF) mobile manipulator which consists of a 7-DOF robotic arm and a 3-DOF mobile base. The system model is based on kinematic models where the end-effector orientation is parameterized directly by a rotation matrix. The state and control constraints as well as singularity constraints are explicitly included in the NMPC formulation. The controller is tested using real-time simulations, which demonstrate high positioning accuracy with tractable computational cost.
Learning in the Sky: An Efficient 3D Placement of UAVs
Mar 02, 2020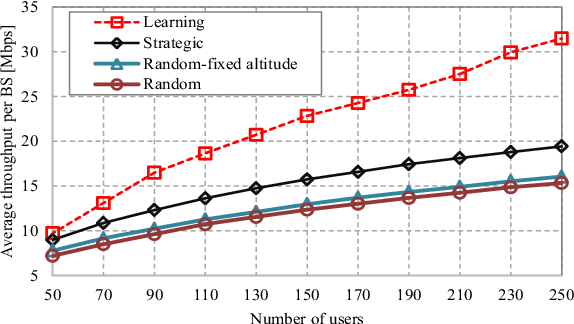
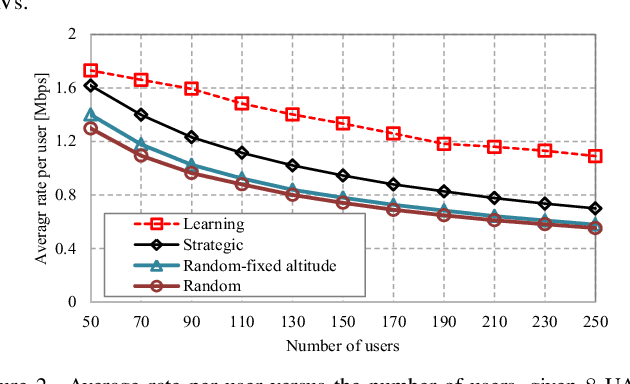
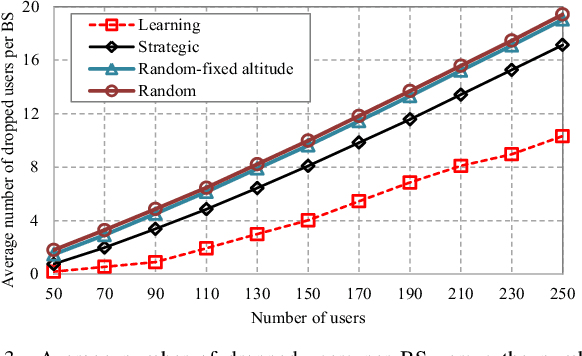
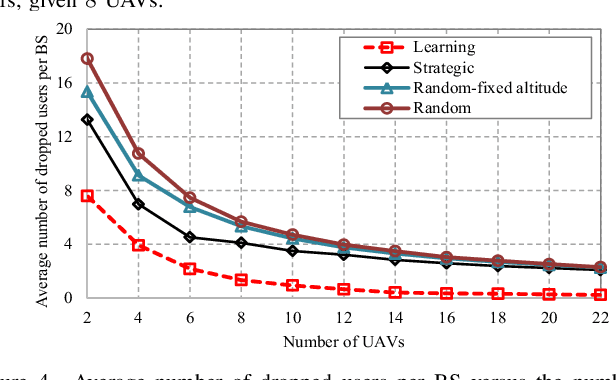
Deployment of unmanned aerial vehicles (UAVs) as aerial base stations can deliver a fast and flexible solution for serving varying traffic demand. In order to adequately benefit of UAVs deployment, their efficient placement is of utmost importance, and requires to intelligently adapt to the environment changes. In this paper, we propose a learning-based mechanism for the three-dimensional deployment of UAVs assisting terrestrial cellular networks in the downlink. The problem is modeled as a non-cooperative game among UAVs in satisfaction form. To solve the game, we utilize a low complexity algorithm, in which unsatisfied UAVs update their locations based on a learning algorithm. Simulation results reveal that the proposed UAV placement algorithm yields significant performance gains up to about 52% and 74% in terms of throughput and the number of dropped users, respectively, compared to an optimized baseline algorithm.