 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuPT: A Generative Symbolic Music Pretrained Transformer
Apr 10, 2024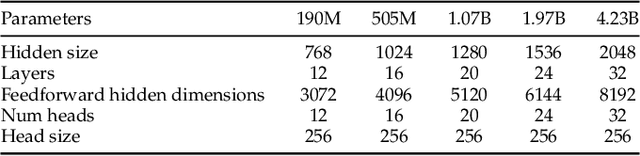

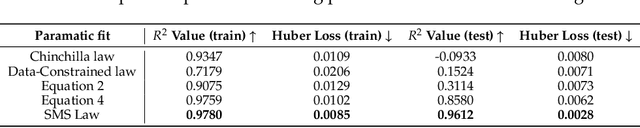
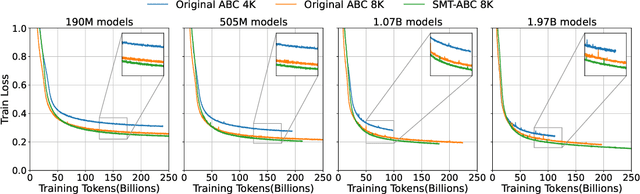
In this paper, we explore the application of Large Language Models (LLMs) to the pre-training of music. While the prevalent use of MIDI in music modeling is well-established, our findings suggest that LLMs are inherently more compatible with ABC Notation, which aligns more closely with their design and strengths, thereby enhancing the model's performance in musical composition. To address the challenges associated with misaligned measures from different tracks during generation, we propose the development of a Synchronized Multi-Track ABC Notation (SMT-ABC Notation), which aims to preserve coherence across multiple musical tracks. Our contributions include a series of models capable of handling up to 8192 tokens, covering 90% of the symbolic music data in our training set. Furthermore, we explore the implications of the Symbolic Music Scaling Law (SMS Law) on model performance. The results indicate a promising direction for future research in music generation, offering extensive resources for community-led research through our open-source contributions.
The Fine Line: Navigating Large Language Model Pretraining with Down-streaming Capability Analysis
Apr 01, 2024



Uncovering early-stage metrics that reflect final model performance is one core principle for large-scale pretraining. The existing scaling law demonstrates the power-law correlation between pretraining loss and training flops, which serves as an important indicator of the current training state for large language models. However, this principle only focuses on the model's compression properties on the training data, resulting in an inconsistency with the ability improvements on the downstream tasks. Some follow-up works attempted to extend the scaling-law to more complex metrics (such as hyperparameters), but still lacked a comprehensive analysis of the dynamic differences among various capabilities during pretraining. To address the aforementioned limitations, this paper undertakes a comprehensive comparison of model capabilities at various pretraining intermediate checkpoints. Through this analysis, we confirm that specific downstream metrics exhibit similar training dynamics across models of different sizes, up to 67 billion parameters. In addition to our core findings, we've reproduced Amber and OpenLLaMA, releasing their intermediate checkpoints. This initiative offers valuable resources to the research community and facilitates the verification and exploration of LLM pretraining by open-source researchers. Besides, we provide empirical summaries, including performance comparisons of different models and capabilities, and tuition of key metrics for different training phases. Based on these findings, we provide a more user-friendly strategy for evaluating the optimization state, offering guidance for establishing a stable pretraining process.
DEEP-ICL: Definition-Enriched Experts for Language Model In-Context Learning
Mar 07, 2024
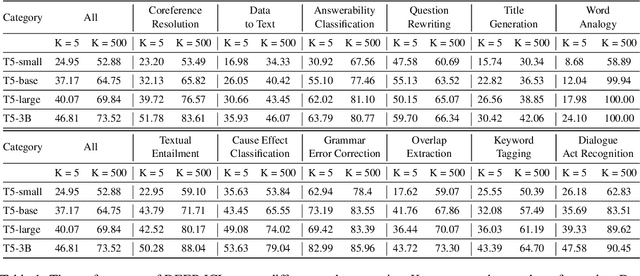
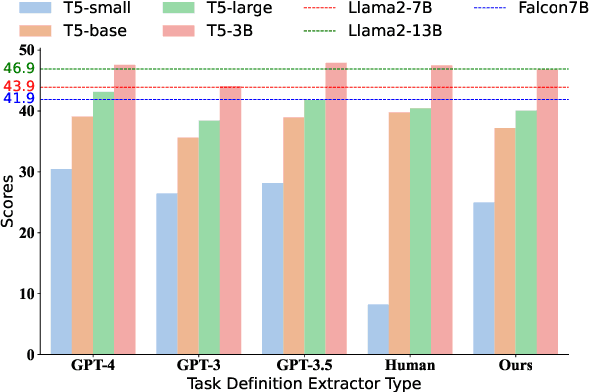
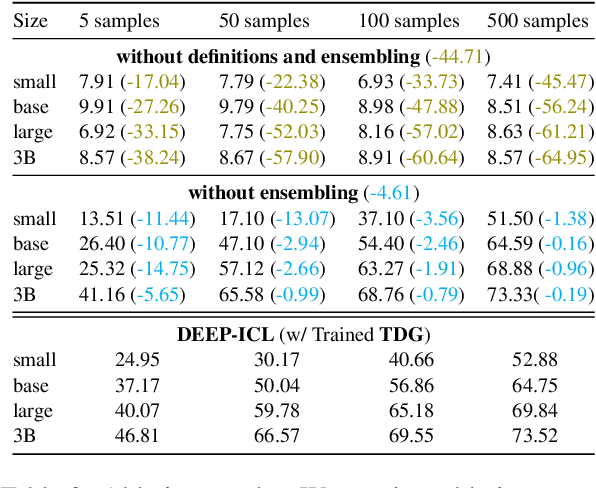
It has long been assumed that the sheer number of parameters in large language models (LLMs) drives in-context learning (ICL) capabilities, enabling remarkable performance improvements by leveraging task-specific demonstrations. Challenging this hypothesis, we introduce DEEP-ICL, a novel task Definition Enriched ExPert Ensembling methodology for ICL. DEEP-ICL explicitly extracts task definitions from given demonstrations and generates responses through learning task-specific examples. We argue that improvement from ICL does not directly rely on model size, but essentially stems from understanding task definitions and task-guided learning. Inspired by this, DEEP-ICL combines two 3B models with distinct roles (one for concluding task definitions and the other for learning task demonstrations) and achieves comparable performance to LLaMA2-13B. Furthermore, our framework outperforms conventional ICL by overcoming pretraining sequence length limitations, by supporting unlimited demonstrations. We contend that DEEP-ICL presents a novel alternative for achieving efficient few-shot learning, extending beyond the conventional ICL.
StructLM: Towards Building Generalist Models for Structured Knowledge Grounding
Feb 28, 2024Structured data sources, such as tables, graphs, and databases, are ubiquitous knowledge sources. Despite the demonstrated capabilities of large language models (LLMs) on plain text, their proficiency in interpreting and utilizing structured data remains limited. Our investigation reveals a notable deficiency in LLMs' ability to process structured data, e.g., ChatGPT lags behind state-of-the-art (SoTA) model by an average of 35%. To augment the Structured Knowledge Grounding (SKG) capabilities in LLMs, we have developed a comprehensive instruction tuning dataset comprising 1.1 million examples. Utilizing this dataset, we train a series of models, referred to as StructLM, based on the Code-LLaMA architecture, ranging from 7B to 34B parameters. Our StructLM series surpasses task-specific models on 14 out of 18 evaluated datasets and establishes new SoTA achievements on 7 SKG tasks. Furthermore, StructLM demonstrates exceptional generalization across 6 novel SKG tasks. Contrary to expectations, we observe that scaling model size offers marginal benefits, with StructLM-34B showing only slight improvements over StructLM-7B. This suggests that structured knowledge grounding is still a challenging task and requires more innovative design to push to a new level.
CMDAG: A Chinese Metaphor Dataset with Annotated Grounds as CoT for Boosting Metaphor Generation
Feb 21, 2024
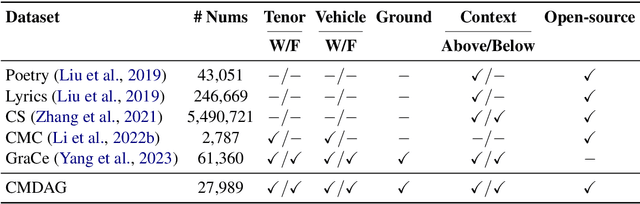


Metaphor is a prominent linguistic device in human language and literature, as they add color, imagery, and emphasis to enhance effective communication. This paper introduces a large-scale high quality annotated Chinese Metaphor Corpus, which comprises around 28K sentences drawn from a diverse range of Chinese literary sources, such as poems, prose, song lyrics, etc. To ensure the accuracy and consistency of our annotations, we introduce a comprehensive set of guidelines. These guidelines address the facets of metaphor annotation, including identifying tenors, vehicles, and grounds to handling the complexities of similes, personifications, juxtapositions, and hyperboles. Breaking tradition, our approach to metaphor generation emphasizes grounds and their distinct features rather than the conventional combination of tenors and vehicles. By integrating "ground" as a CoT (Chain of Thoughts) input, we are able to generate metaphors that resonate more with real-world intuition. We test generative models such as Belle, Baichuan, and Chinese-alpaca-33B using our annotated corpus. These models are able to generate creative and fluent metaphor sentences more frequently induced by selected samples from our dataset, demonstrating the value of our corpus for Chinese metaphor research. The code is available in https://github.com/JasonShao55/Chinese_Metaphor_Explanation.
CIF-Bench: A Chinese Instruction-Following Benchmark for Evaluating the Generalizability of Large Language Models
Feb 20, 2024The advancement of large language models (LLMs) has enhanced the ability to generalize across a wide range of unseen natural language processing (NLP) tasks through instruction-following. Yet, their effectiveness often diminishes in low-resource languages like Chinese, exacerbated by biased evaluations from data leakage, casting doubt on their true generalizability to new linguistic territories. In response, we introduce the Chinese Instruction-Following Benchmark (CIF-Bench), designed to evaluate the zero-shot generalizability of LLMs to the Chinese language. CIF-Bench comprises 150 tasks and 15,000 input-output pairs, developed by native speakers to test complex reasoning and Chinese cultural nuances across 20 categories. To mitigate evaluation bias, we release only half of the dataset publicly, with the remainder kept private, and introduce diversified instructions to minimize score variance, totaling 45,000 data instances. Our evaluation of 28 selected LLMs reveals a noticeable performance gap, with the best model scoring only 52.9%, highlighting the limitations of LLMs in less familiar language and task contexts. This work aims to uncover the current limitations of LLMs in handling Chinese tasks, pushing towards the development of more culturally informed and linguistically diverse models with the released data and benchmark (https://yizhilll.github.io/CIF-Bench/).
MORE-3S:Multimodal-based Offline Reinforcement Learning with Shared Semantic Spaces
Feb 20, 2024



Drawing upon the intuition that aligning different modalities to the same semantic embedding space would allow models to understand states and actions more easily, we propose a new perspective to the offline reinforcement learning (RL) challenge. More concretely, we transform it into a supervised learning task by integrating multimodal and pre-trained language models. Our approach incorporates state information derived from images and action-related data obtained from text, thereby bolstering RL training performance and promoting long-term strategic thinking. We emphasize the contextual understanding of language and demonstrate how decision-making in RL can benefit from aligning states' and actions' representation with languages' representation. Our method significantly outperforms current baselines as evidenced by evaluations conducted on Atari and OpenAI Gym environments. This contributes to advancing offline RL performance and efficiency while providing a novel perspective on offline RL.Our code and data are available at https://github.com/Zheng0428/MORE_.
Read to Play (R2-Play): Decision Transformer with Multimodal Game Instruction
Feb 08, 2024Developing a generalist agent is a longstanding objective in artificial intelligence. Previous efforts utilizing extensive offline datasets from various tasks demonstrate remarkable performance in multitasking scenarios within Reinforcement Learning. However, these works encounter challenges in extending their capabilities to new tasks. Recent approaches integrate textual guidance or visual trajectory into decision networks to provide task-specific contextual cues, representing a promising direction. However, it is observed that relying solely on textual guidance or visual trajectory is insufficient for accurately conveying the contextual information of tasks. This paper explores enhanced forms of task guidance for agents, enabling them to comprehend gameplay instructions, thereby facilitating a "read-to-play" capability. Drawing inspiration from the success of multimodal instruction tuning in visual tasks, we treat the visual-based RL task as a long-horizon vision task and construct a set of multimodal game instructions to incorporate instruction tuning into a decision transformer. Experimental results demonstrate that incorporating multimodal game instructions significantly enhances the decision transformer's multitasking and generalization capabilities.