 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDEEP-ICL: Definition-Enriched Experts for Language Model In-Context Learning
Mar 07, 2024
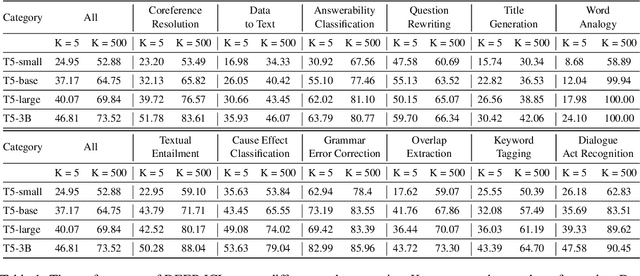
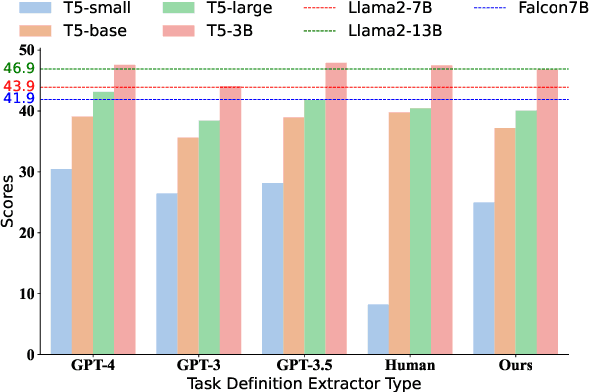
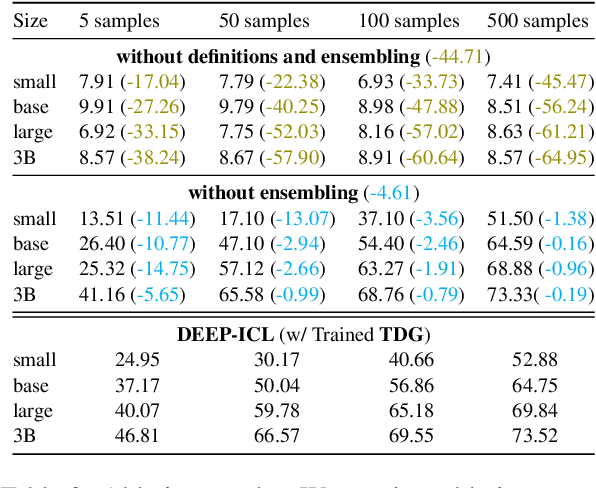
It has long been assumed that the sheer number of parameters in large language models (LLMs) drives in-context learning (ICL) capabilities, enabling remarkable performance improvements by leveraging task-specific demonstrations. Challenging this hypothesis, we introduce DEEP-ICL, a novel task Definition Enriched ExPert Ensembling methodology for ICL. DEEP-ICL explicitly extracts task definitions from given demonstrations and generates responses through learning task-specific examples. We argue that improvement from ICL does not directly rely on model size, but essentially stems from understanding task definitions and task-guided learning. Inspired by this, DEEP-ICL combines two 3B models with distinct roles (one for concluding task definitions and the other for learning task demonstrations) and achieves comparable performance to LLaMA2-13B. Furthermore, our framework outperforms conventional ICL by overcoming pretraining sequence length limitations, by supporting unlimited demonstrations. We contend that DEEP-ICL presents a novel alternative for achieving efficient few-shot learning, extending beyond the conventional ICL.