 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDiQ: Test-Time Scaling for Controllable Difficult Question Generation
Feb 02, 2026Large Reasoning Models (LRMs) benefit substantially from training on challenging competition-level questions. However, existing automated question synthesis methods lack precise difficulty control, incur high computational costs, and struggle to generate competition-level questions at scale. In this paper, we propose CoDiQ (Controllable Difficult Question Generation), a novel framework enabling fine-grained difficulty control via test-time scaling while ensuring question solvability. Specifically, first, we identify a test-time scaling tendency (extended reasoning token budget boosts difficulty but reduces solvability) and the intrinsic properties defining the upper bound of a model's ability to generate valid, high-difficulty questions. Then, we develop CoDiQ-Generator from Qwen3-8B, which improves the upper bound of difficult question generation, making it particularly well-suited for challenging question construction. Building on the CoDiQ framework, we build CoDiQ-Corpus (44K competition-grade question sequences). Human evaluations show these questions are significantly more challenging than LiveCodeBench/AIME with over 82% solvability. Training LRMs on CoDiQ-Corpus substantially improves reasoning performance, verifying that scaling controlled-difficulty training questions enhances reasoning capabilities. We open-source CoDiQ-Corpus, CoDiQ-Generator, and implementations to support related research.
CryptoX : Compositional Reasoning Evaluation of Large Language Models
Feb 08, 2025The compositional reasoning capacity has long been regarded as critical to the generalization and intelligence emergence of large language models LLMs. However, despite numerous reasoning-related benchmarks, the compositional reasoning capacity of LLMs is rarely studied or quantified in the existing benchmarks. In this paper, we introduce CryptoX, an evaluation framework that, for the first time, combines existing benchmarks and cryptographic, to quantify the compositional reasoning capacity of LLMs. Building upon CryptoX, we construct CryptoBench, which integrates these principles into several benchmarks for systematic evaluation. We conduct detailed experiments on widely used open-source and closed-source LLMs using CryptoBench, revealing a huge gap between open-source and closed-source LLMs. We further conduct thorough mechanical interpretability experiments to reveal the inner mechanism of LLMs' compositional reasoning, involving subproblem decomposition, subproblem inference, and summarizing subproblem conclusions. Through analysis based on CryptoBench, we highlight the value of independently studying compositional reasoning and emphasize the need to enhance the compositional reasoning capabilities of LLMs.
ConsistI2V: Enhancing Visual Consistency for Image-to-Video Generation
Feb 06, 2024



Image-to-video (I2V) generation aims to use the initial frame (alongside a text prompt) to create a video sequence. A grand challenge in I2V generation is to maintain visual consistency throughout the video: existing methods often struggle to preserve the integrity of the subject, background, and style from the first frame, as well as ensure a fluid and logical progression within the video narrative. To mitigate these issues, we propose ConsistI2V, a diffusion-based method to enhance visual consistency for I2V generation. Specifically, we introduce (1) spatiotemporal attention over the first frame to maintain spatial and motion consistency, (2) noise initialization from the low-frequency band of the first frame to enhance layout consistency. These two approaches enable ConsistI2V to generate highly consistent videos. We also extend the proposed approaches to show their potential to improve consistency in auto-regressive long video generation and camera motion control. To verify the effectiveness of our method, we propose I2V-Bench, a comprehensive evaluation benchmark for I2V generation. Our automatic and human evaluation results demonstrate the superiority of ConsistI2V over existing methods.
Effective Real Image Editing with Accelerated Iterative Diffusion Inversion
Sep 10, 2023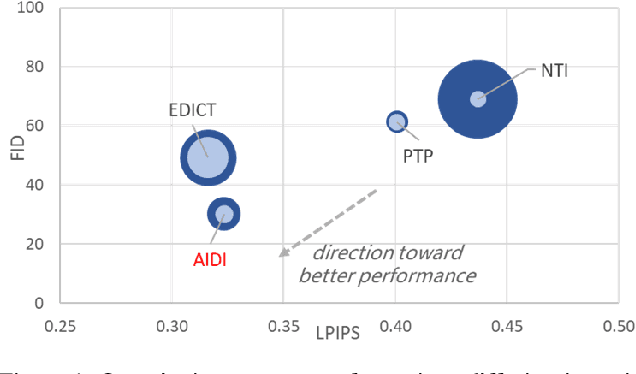
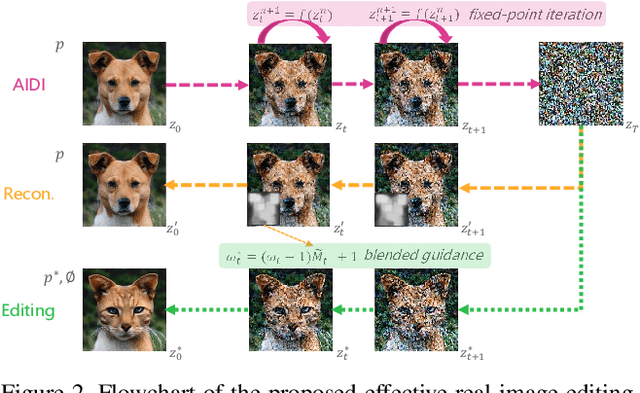


Despite all recent progress, it is still challenging to edit and manipulate natural images with modern generative models. When using Generative Adversarial Network (GAN), one major hurdle is in the inversion process mapping a real image to its corresponding noise vector in the latent space, since its necessary to be able to reconstruct an image to edit its contents. Likewise for Denoising Diffusion Implicit Models (DDIM), the linearization assumption in each inversion step makes the whole deterministic inversion process unreliable. Existing approaches that have tackled the problem of inversion stability often incur in significant trade-offs in computational efficiency. In this work we propose an Accelerated Iterative Diffusion Inversion method, dubbed AIDI, that significantly improves reconstruction accuracy with minimal additional overhead in space and time complexity. By using a novel blended guidance technique, we show that effective results can be obtained on a large range of image editing tasks without large classifier-free guidance in inversion. Furthermore, when compared with other diffusion inversion based works, our proposed process is shown to be more robust for fast image editing in the 10 and 20 diffusion steps' regimes.
HollowNeRF: Pruning Hashgrid-Based NeRFs with Trainable Collision Mitigation
Aug 19, 2023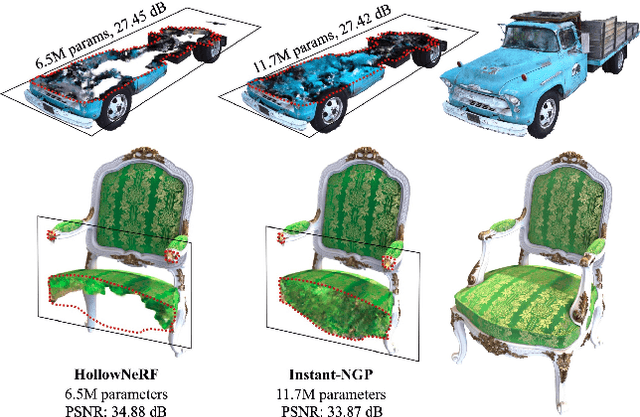
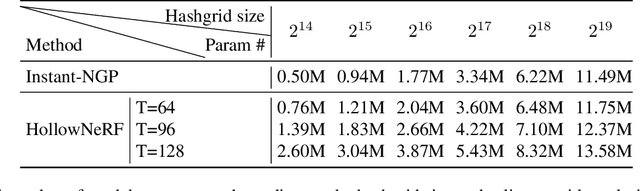
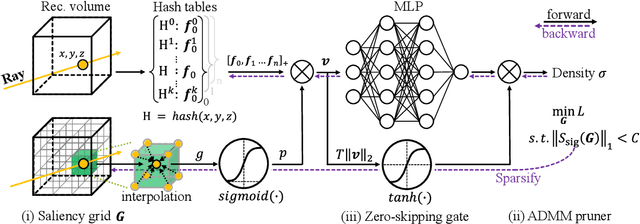
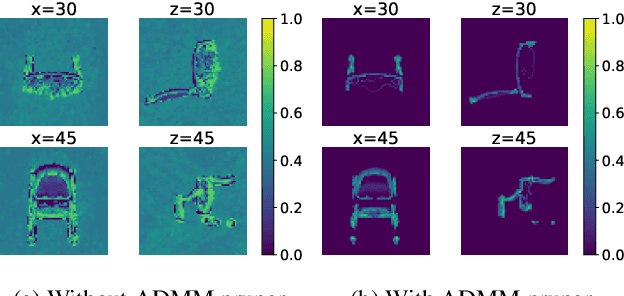
Neural radiance fields (NeRF) have garnered significant attention, with recent works such as Instant-NGP accelerating NeRF training and evaluation through a combination of hashgrid-based positional encoding and neural networks. However, effectively leveraging the spatial sparsity of 3D scenes remains a challenge. To cull away unnecessary regions of the feature grid, existing solutions rely on prior knowledge of object shape or periodically estimate object shape during training by repeated model evaluations, which are costly and wasteful. To address this issue, we propose HollowNeRF, a novel compression solution for hashgrid-based NeRF which automatically sparsifies the feature grid during the training phase. Instead of directly compressing dense features, HollowNeRF trains a coarse 3D saliency mask that guides efficient feature pruning, and employs an alternating direction method of multipliers (ADMM) pruner to sparsify the 3D saliency mask during training. By exploiting the sparsity in the 3D scene to redistribute hash collisions, HollowNeRF improves rendering quality while using a fraction of the parameters of comparable state-of-the-art solutions, leading to a better cost-accuracy trade-off. Our method delivers comparable rendering quality to Instant-NGP, while utilizing just 31% of the parameters. In addition, our solution can achieve a PSNR accuracy gain of up to 1dB using only 56% of the parameters.