 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Real Image Editing with Accelerated Iterative Diffusion Inversion
Sep 10, 2023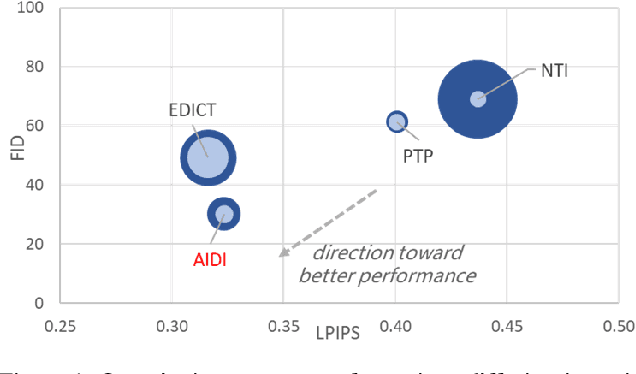
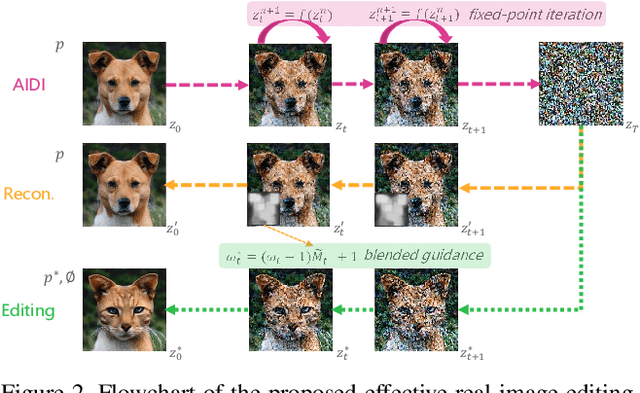


Despite all recent progress, it is still challenging to edit and manipulate natural images with modern generative models. When using Generative Adversarial Network (GAN), one major hurdle is in the inversion process mapping a real image to its corresponding noise vector in the latent space, since its necessary to be able to reconstruct an image to edit its contents. Likewise for Denoising Diffusion Implicit Models (DDIM), the linearization assumption in each inversion step makes the whole deterministic inversion process unreliable. Existing approaches that have tackled the problem of inversion stability often incur in significant trade-offs in computational efficiency. In this work we propose an Accelerated Iterative Diffusion Inversion method, dubbed AIDI, that significantly improves reconstruction accuracy with minimal additional overhead in space and time complexity. By using a novel blended guidance technique, we show that effective results can be obtained on a large range of image editing tasks without large classifier-free guidance in inversion. Furthermore, when compared with other diffusion inversion based works, our proposed process is shown to be more robust for fast image editing in the 10 and 20 diffusion steps' regimes.
HollowNeRF: Pruning Hashgrid-Based NeRFs with Trainable Collision Mitigation
Aug 19, 2023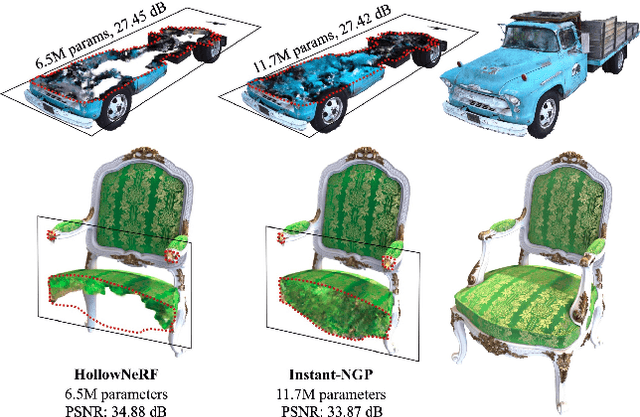
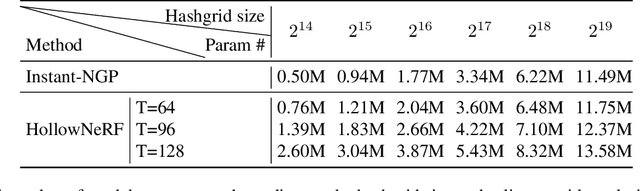
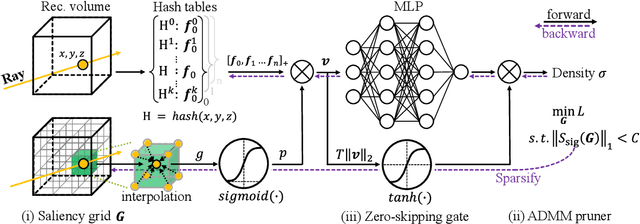
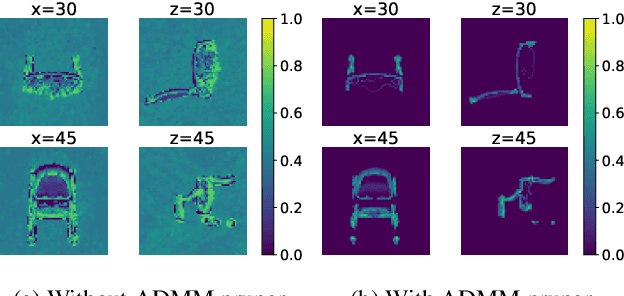
Neural radiance fields (NeRF) have garnered significant attention, with recent works such as Instant-NGP accelerating NeRF training and evaluation through a combination of hashgrid-based positional encoding and neural networks. However, effectively leveraging the spatial sparsity of 3D scenes remains a challenge. To cull away unnecessary regions of the feature grid, existing solutions rely on prior knowledge of object shape or periodically estimate object shape during training by repeated model evaluations, which are costly and wasteful. To address this issue, we propose HollowNeRF, a novel compression solution for hashgrid-based NeRF which automatically sparsifies the feature grid during the training phase. Instead of directly compressing dense features, HollowNeRF trains a coarse 3D saliency mask that guides efficient feature pruning, and employs an alternating direction method of multipliers (ADMM) pruner to sparsify the 3D saliency mask during training. By exploiting the sparsity in the 3D scene to redistribute hash collisions, HollowNeRF improves rendering quality while using a fraction of the parameters of comparable state-of-the-art solutions, leading to a better cost-accuracy trade-off. Our method delivers comparable rendering quality to Instant-NGP, while utilizing just 31% of the parameters. In addition, our solution can achieve a PSNR accuracy gain of up to 1dB using only 56% of the parameters.
AutoShot: A Short Video Dataset and State-of-the-Art Shot Boundary Detection
Apr 12, 2023The short-form videos have explosive popularity and have dominated the new social media trends. Prevailing short-video platforms,~\textit{e.g.}, Kuaishou (Kwai), TikTok, Instagram Reels, and YouTube Shorts, have changed the way we consume and create content. For video content creation and understanding, the shot boundary detection (SBD) is one of the most essential components in various scenarios. In this work, we release a new public Short video sHot bOundary deTection dataset, named SHOT, consisting of 853 complete short videos and 11,606 shot annotations, with 2,716 high quality shot boundary annotations in 200 test videos. Leveraging this new data wealth, we propose to optimize the model design for video SBD, by conducting neural architecture search in a search space encapsulating various advanced 3D ConvNets and Transformers. Our proposed approach, named AutoShot, achieves higher F1 scores than previous state-of-the-art approaches, e.g., outperforming TransNetV2 by 4.2%, when being derived and evaluated on our newly constructed SHOT dataset. Moreover, to validate the generalizability of the AutoShot architecture, we directly evaluate it on another three public datasets: ClipShots, BBC and RAI, and the F1 scores of AutoShot outperform previous state-of-the-art approaches by 1.1%, 0.9% and 1.2%, respectively. The SHOT dataset and code can be found in https://github.com/wentaozhu/AutoShot.git .
Partial Weight Adaptation for Robust DNN Inference
Mar 13, 2020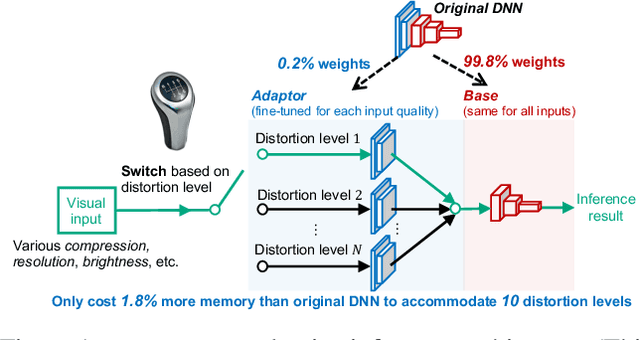
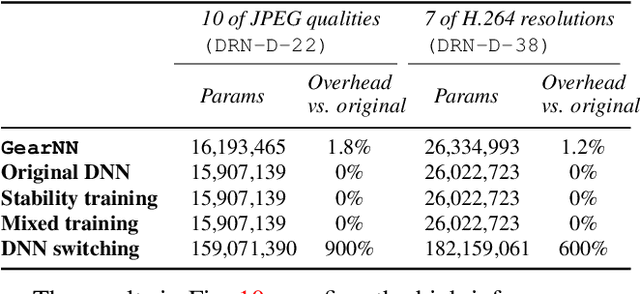
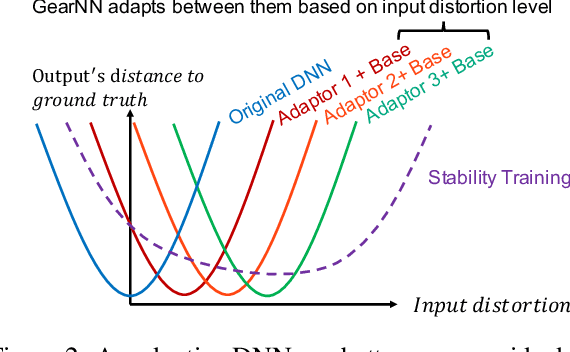
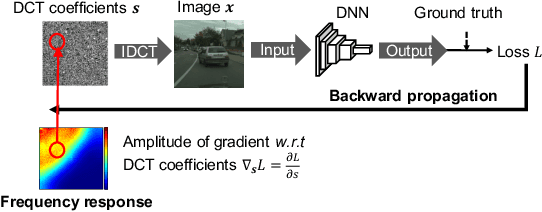
Mainstream video analytics uses a pre-trained DNN model with an assumption that inference input and training data follow the same probability distribution. However, this assumption does not always hold in the wild: autonomous vehicles may capture video with varying brightness; unstable wireless bandwidth calls for adaptive bitrate streaming of video; and, inference servers may serve inputs from heterogeneous IoT devices/cameras. In such situations, the level of input distortion changes rapidly, thus reshaping the probability distribution of the input. We present GearNN, an adaptive inference architecture that accommodates heterogeneous DNN inputs. GearNN employs an optimization algorithm to identify a small set of "distortion-sensitive" DNN parameters, given a memory budget. Based on the distortion level of the input, GearNN then adapts only the distortion-sensitive parameters, while reusing the rest of constant parameters across all input qualities. In our evaluation of DNN inference with dynamic input distortions, GearNN improves the accuracy (mIoU) by an average of 18.12% over a DNN trained with the undistorted dataset and 4.84% over stability training from Google, with only 1.8% extra memory overhead.