 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoShot: A Short Video Dataset and State-of-the-Art Shot Boundary Detection
Apr 12, 2023The short-form videos have explosive popularity and have dominated the new social media trends. Prevailing short-video platforms,~\textit{e.g.}, Kuaishou (Kwai), TikTok, Instagram Reels, and YouTube Shorts, have changed the way we consume and create content. For video content creation and understanding, the shot boundary detection (SBD) is one of the most essential components in various scenarios. In this work, we release a new public Short video sHot bOundary deTection dataset, named SHOT, consisting of 853 complete short videos and 11,606 shot annotations, with 2,716 high quality shot boundary annotations in 200 test videos. Leveraging this new data wealth, we propose to optimize the model design for video SBD, by conducting neural architecture search in a search space encapsulating various advanced 3D ConvNets and Transformers. Our proposed approach, named AutoShot, achieves higher F1 scores than previous state-of-the-art approaches, e.g., outperforming TransNetV2 by 4.2%, when being derived and evaluated on our newly constructed SHOT dataset. Moreover, to validate the generalizability of the AutoShot architecture, we directly evaluate it on another three public datasets: ClipShots, BBC and RAI, and the F1 scores of AutoShot outperform previous state-of-the-art approaches by 1.1%, 0.9% and 1.2%, respectively. The SHOT dataset and code can be found in https://github.com/wentaozhu/AutoShot.git .
IR-GAN: Image Manipulation with Linguistic Instruction by Increment Reasoning
Apr 02, 2022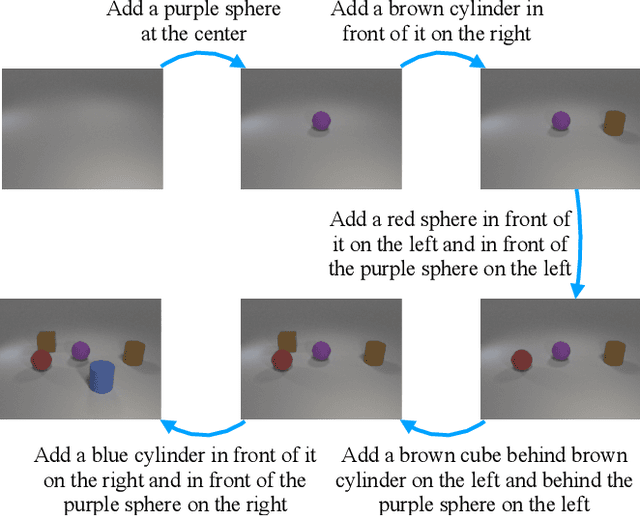

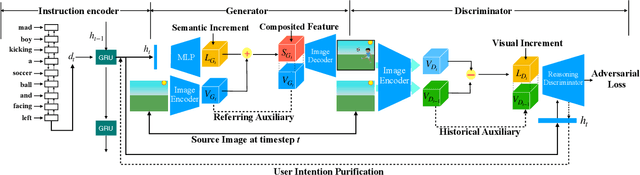
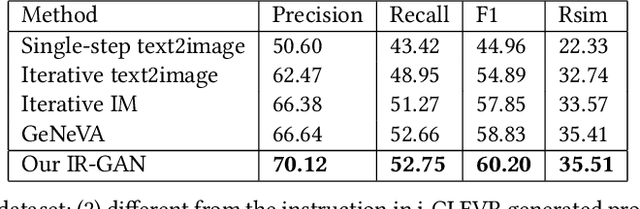
Conditional image generation is an active research topic including text2image and image translation. Recently image manipulation with linguistic instruction brings new challenges of multimodal conditional generation. However, traditional conditional image generation models mainly focus on generating high-quality and visually realistic images, and lack resolving the partial consistency between image and instruction. To address this issue, we propose an Increment Reasoning Generative Adversarial Network (IR-GAN), which aims to reason the consistency between visual increment in images and semantic increment in instructions. First, we introduce the word-level and instruction-level instruction encoders to learn user's intention from history-correlated instructions as semantic increment. Second, we embed the representation of semantic increment into that of source image for generating target image, where source image plays the role of referring auxiliary. Finally, we propose a reasoning discriminator to measure the consistency between visual increment and semantic increment, which purifies user's intention and guarantees the good logic of generated target image. Extensive experiments and visualization conducted on two datasets show the effectiveness of IR-GAN.
EfficientCLIP: Efficient Cross-Modal Pre-training by Ensemble Confident Learning and Language Modeling
Sep 22, 2021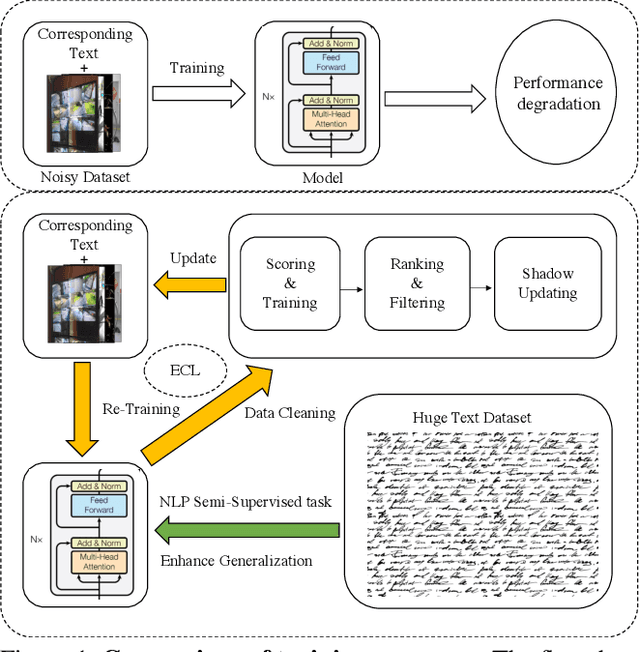
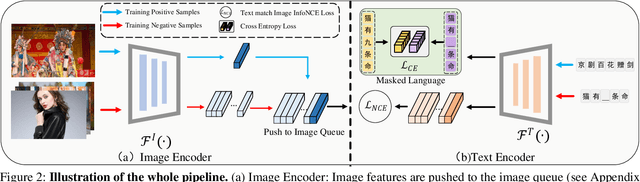
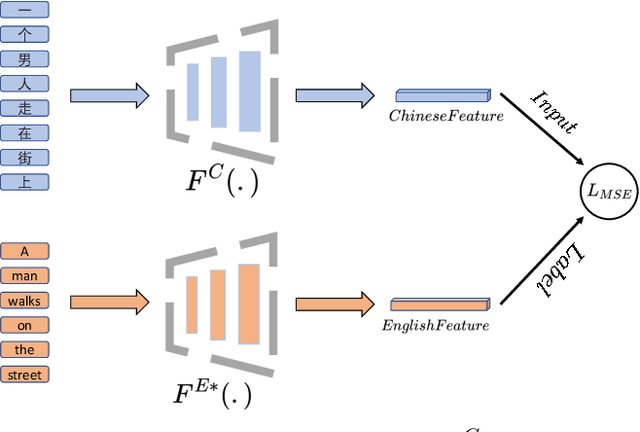
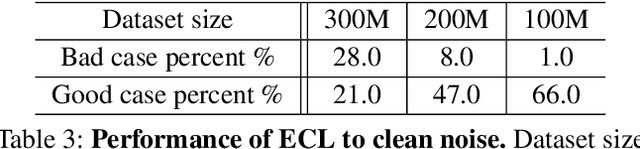
While large scale pre-training has achieved great achievements in bridging the gap between vision and language, it still faces several challenges. First, the cost for pre-training is expensive. Second, there is no efficient way to handle the data noise which degrades model performance. Third, previous methods only leverage limited image-text paired data, while ignoring richer single-modal data, which may result in poor generalization to single-modal downstream tasks. In this work, we propose an EfficientCLIP method via Ensemble Confident Learning to obtain a less noisy data subset. Extra rich non-paired single-modal text data is used for boosting the generalization of text branch. We achieve the state-of-the-art performance on Chinese cross-modal retrieval tasks with only 1/10 training resources compared to CLIP and WenLan, while showing excellent generalization to single-modal tasks, including text retrieval and text classification.
Rethinking Graph Neural Network Search from Message-passing
Apr 18, 2021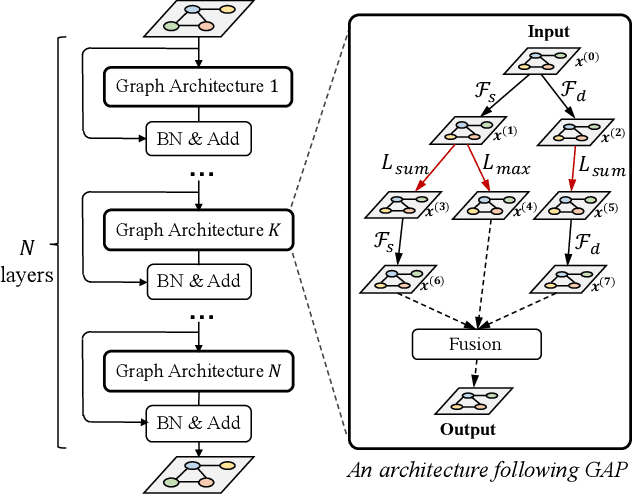

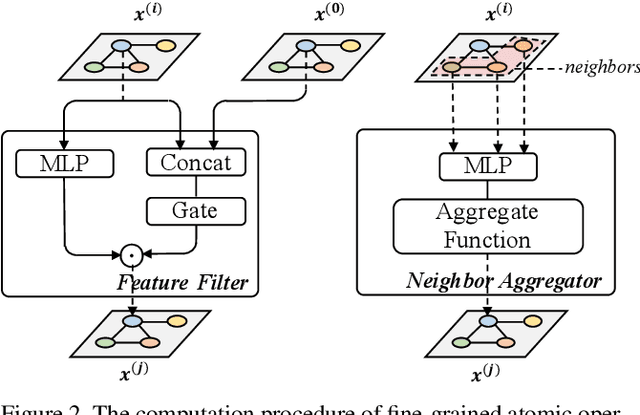
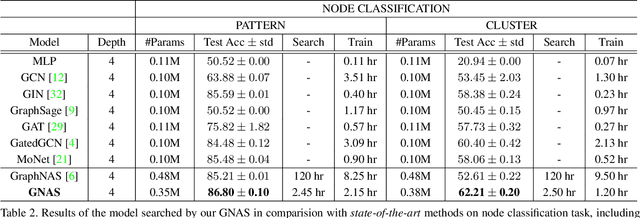
Graph neural networks (GNNs) emerged recently as a standard toolkit for learning from data on graphs. Current GNN designing works depend on immense human expertise to explore different message-passing mechanisms, and require manual enumeration to determine the proper message-passing depth. Inspired by the strong searching capability of neural architecture search (NAS) in CNN, this paper proposes Graph Neural Architecture Search (GNAS) with novel-designed search space. The GNAS can automatically learn better architecture with the optimal depth of message passing on the graph. Specifically, we design Graph Neural Architecture Paradigm (GAP) with tree-topology computation procedure and two types of fine-grained atomic operations (feature filtering and neighbor aggregation) from message-passing mechanism to construct powerful graph network search space. Feature filtering performs adaptive feature selection, and neighbor aggregation captures structural information and calculates neighbors' statistics. Experiments show that our GNAS can search for better GNNs with multiple message-passing mechanisms and optimal message-passing depth. The searched network achieves remarkable improvement over state-of-the-art manual designed and search-based GNNs on five large-scale datasets at three classical graph tasks. Codes can be found at https://github.com/phython96/GNAS-MP.