 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Weight Adaptation for Robust DNN Inference
Paper and Code
Mar 13, 2020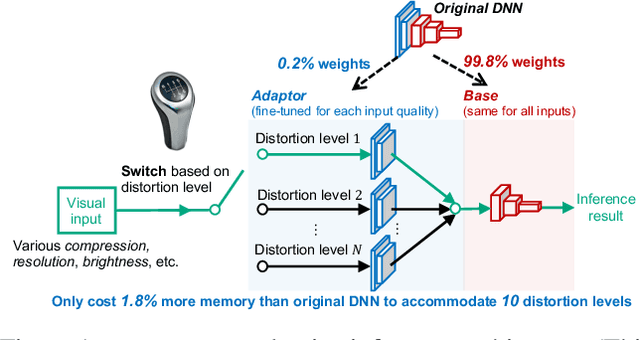
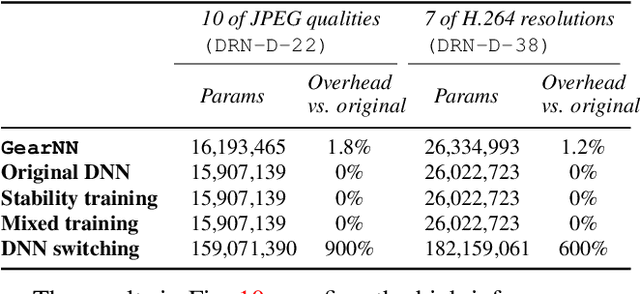
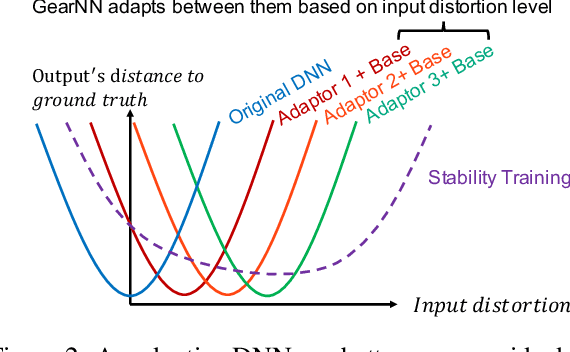
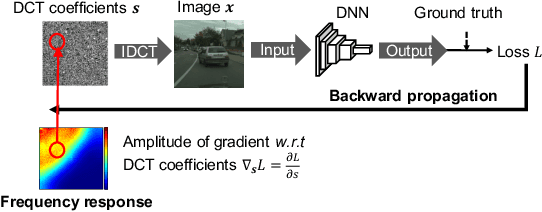
Mainstream video analytics uses a pre-trained DNN model with an assumption that inference input and training data follow the same probability distribution. However, this assumption does not always hold in the wild: autonomous vehicles may capture video with varying brightness; unstable wireless bandwidth calls for adaptive bitrate streaming of video; and, inference servers may serve inputs from heterogeneous IoT devices/cameras. In such situations, the level of input distortion changes rapidly, thus reshaping the probability distribution of the input. We present GearNN, an adaptive inference architecture that accommodates heterogeneous DNN inputs. GearNN employs an optimization algorithm to identify a small set of "distortion-sensitive" DNN parameters, given a memory budget. Based on the distortion level of the input, GearNN then adapts only the distortion-sensitive parameters, while reusing the rest of constant parameters across all input qualities. In our evaluation of DNN inference with dynamic input distortions, GearNN improves the accuracy (mIoU) by an average of 18.12% over a DNN trained with the undistorted dataset and 4.84% over stability training from Google, with only 1.8% extra memory overhead.