 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Image Technical Report
Dec 08, 2025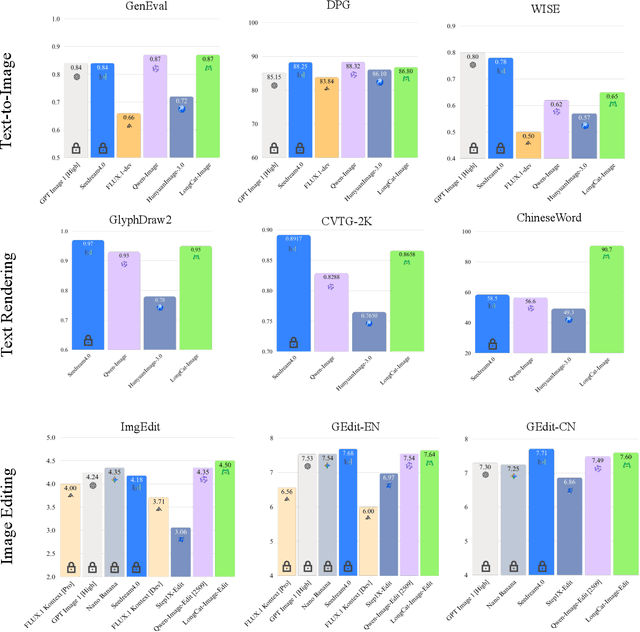

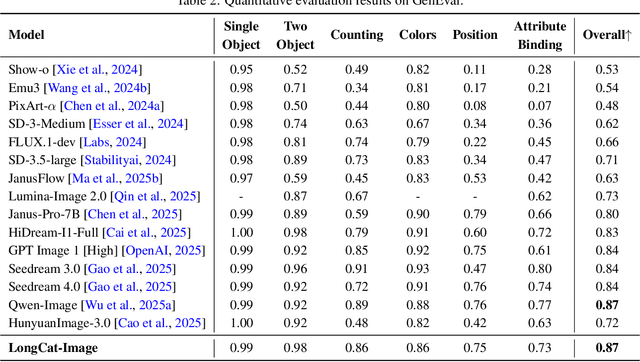
We introduce LongCat-Image, a pioneering open-source and bilingual (Chinese-English) foundation model for image generation, designed to address core challenges in multilingual text rendering, photorealism, deployment efficiency, and developer accessibility prevalent in current leading models. 1) We achieve this through rigorous data curation strategies across the pre-training, mid-training, and SFT stages, complemented by the coordinated use of curated reward models during the RL phase. This strategy establishes the model as a new state-of-the-art (SOTA), delivering superior text-rendering capabilities and remarkable photorealism, and significantly enhancing aesthetic quality. 2) Notably, it sets a new industry standard for Chinese character rendering. By supporting even complex and rare characters, it outperforms both major open-source and commercial solutions in coverage, while also achieving superior accuracy. 3) The model achieves remarkable efficiency through its compact design. With a core diffusion model of only 6B parameters, it is significantly smaller than the nearly 20B or larger Mixture-of-Experts (MoE) architectures common in the field. This ensures minimal VRAM usage and rapid inference, significantly reducing deployment costs. Beyond generation, LongCat-Image also excels in image editing, achieving SOTA results on standard benchmarks with superior editing consistency compared to other open-source works. 4) To fully empower the community, we have established the most comprehensive open-source ecosystem to date. We are releasing not only multiple model versions for text-to-image and image editing, including checkpoints after mid-training and post-training stages, but also the entire toolchain of training procedure. We believe that the openness of LongCat-Image will provide robust support for developers and researchers, pushing the frontiers of visual content creation.
InstructSeg: Unifying Instructed Visual Segmentation with Multi-modal Large Language Models
Dec 18, 2024Boosted by Multi-modal Large Language Models (MLLMs), text-guided universal segmentation models for the image and video domains have made rapid progress recently. However, these methods are often developed separately for specific domains, overlooking the similarities in task settings and solutions across these two areas. In this paper, we define the union of referring segmentation and reasoning segmentation at both the image and video levels as Instructed Visual Segmentation (IVS). Correspondingly, we propose InstructSeg, an end-to-end segmentation pipeline equipped with MLLMs for IVS. Specifically, we employ an object-aware video perceiver to extract temporal and object information from reference frames, facilitating comprehensive video understanding. Additionally, we introduce vision-guided multi-granularity text fusion to better integrate global and detailed text information with fine-grained visual guidance. By leveraging multi-task and end-to-end training, InstructSeg demonstrates superior performance across diverse image and video segmentation tasks, surpassing both segmentation specialists and MLLM-based methods with a single model. Our code is available at https://github.com/congvvc/InstructSeg.
LinVT: Empower Your Image-level Large Language Model to Understand Videos
Dec 06, 2024Large Language Models (LLMs) have been widely used in various tasks, motivating us to develop an LLM-based assistant for videos. Instead of training from scratch, we propose a module to transform arbitrary well-trained image-based LLMs into video-LLMs (after being trained on video data). To better adapt image-LLMs for processing videos, we introduce two design principles: linear transformation to preserve the original visual-language alignment and representative information condensation from redundant video content. Guided by these principles, we propose a plug-and-play Linear Video Tokenizer(LinVT), which enables existing image-LLMs to understand videos. We benchmark LinVT with six recent visual LLMs: Aquila, Blip-3, InternVL2, Mipha, Molmo and Qwen2-VL, showcasing the high compatibility of LinVT. LinVT-based LLMs achieve state-of-the-art performance across various video benchmarks, illustrating the effectiveness of LinVT in multi-modal video understanding.
HyperSeg: Towards Universal Visual Segmentation with Large Language Model
Nov 26, 2024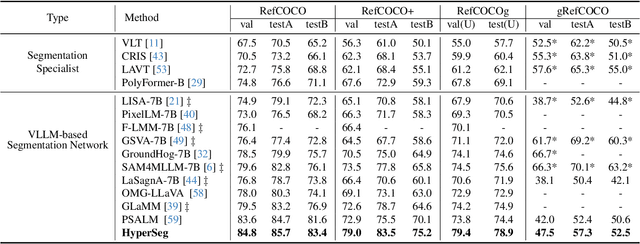
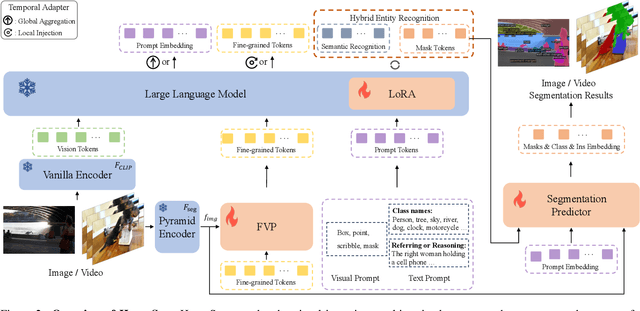
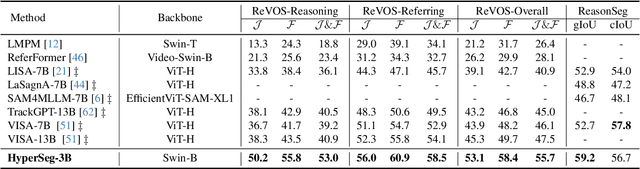
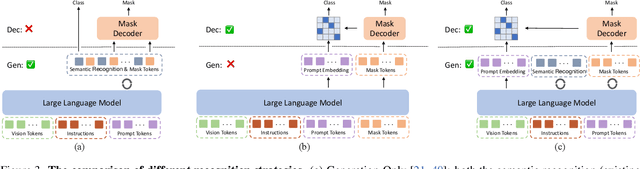
This paper aims to address universal segmentation for image and video perception with the strong reasoning ability empowered by Visual Large Language Models (VLLMs). Despite significant progress in current unified segmentation methods, limitations in adaptation to both image and video scenarios, as well as the complex reasoning segmentation, make it difficult for them to handle various challenging instructions and achieve an accurate understanding of fine-grained vision-language correlations. We propose HyperSeg, the first VLLM-based universal segmentation model for pixel-level image and video perception, encompassing generic segmentation tasks and more complex reasoning perception tasks requiring powerful reasoning abilities and world knowledge. Besides, to fully leverage the recognition capabilities of VLLMs and the fine-grained visual information, HyperSeg incorporates hybrid entity recognition and fine-grained visual perceiver modules for various segmentation tasks. Combined with the temporal adapter, HyperSeg achieves a comprehensive understanding of temporal information. Experimental results validate the effectiveness of our insights in resolving universal image and video segmentation tasks, including the more complex reasoning perception tasks. Our code is available.
LaSagnA: Language-based Segmentation Assistant for Complex Queries
Apr 12, 2024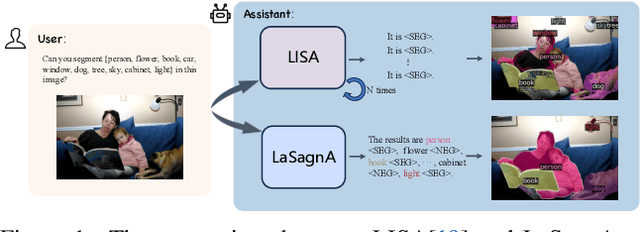
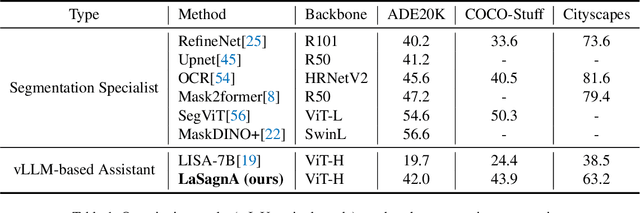

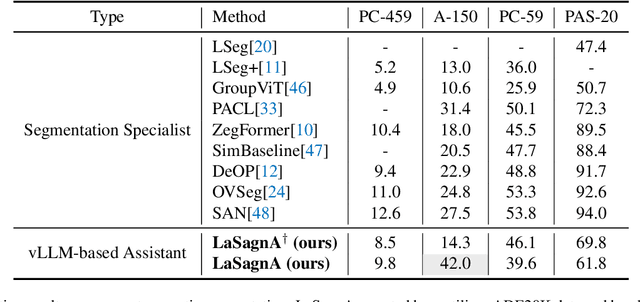
Recent advancements have empowered Large Language Models for Vision (vLLMs) to generate detailed perceptual outcomes, including bounding boxes and masks. Nonetheless, there are two constraints that restrict the further application of these vLLMs: the incapability of handling multiple targets per query and the failure to identify the absence of query objects in the image. In this study, we acknowledge that the main cause of these problems is the insufficient complexity of training queries. Consequently, we define the general sequence format for complex queries. Then we incorporate a semantic segmentation task in the current pipeline to fulfill the requirements of training data. Furthermore, we present three novel strategies to effectively handle the challenges arising from the direct integration of the proposed format. The effectiveness of our model in processing complex queries is validated by the comparable results with conventional methods on both close-set and open-set semantic segmentation datasets. Additionally, we outperform a series of vLLMs in reasoning and referring segmentation, showcasing our model's remarkable capabilities. We release the code at https://github.com/congvvc/LaSagnA.
Mutually-aware Sub-Graphs Differentiable Architecture Search
Jul 12, 2021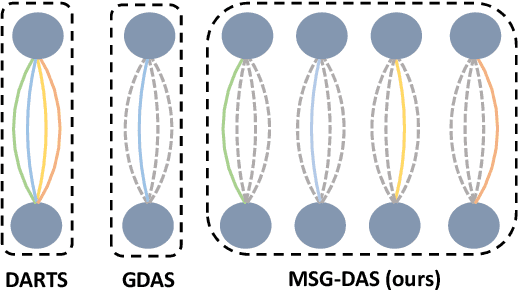
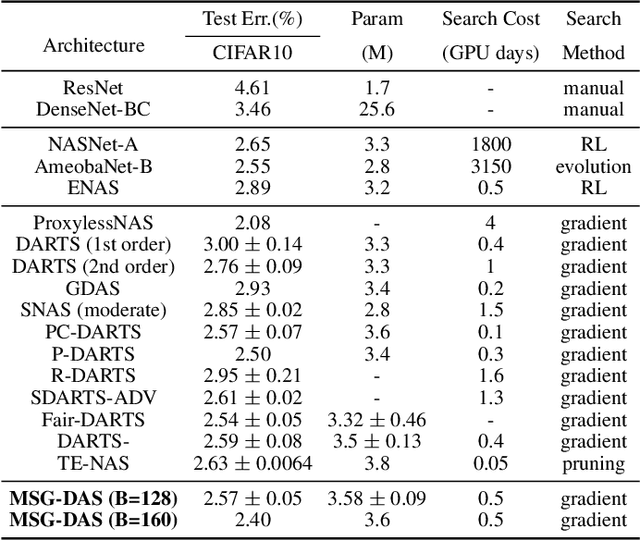
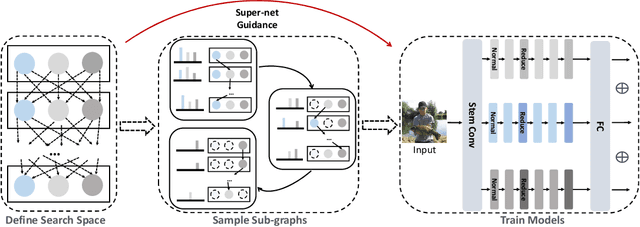
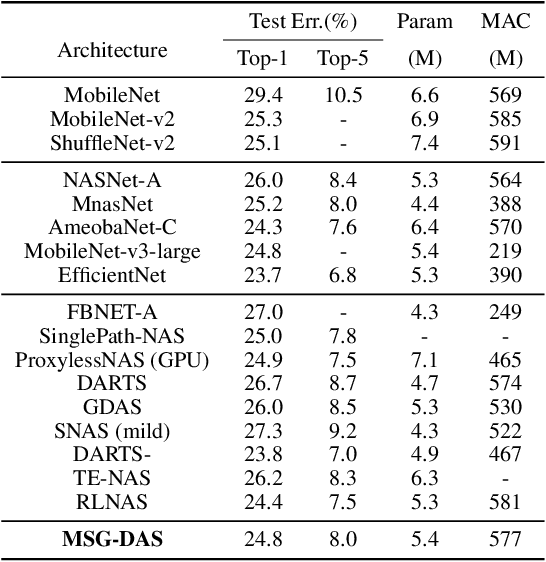
Differentiable architecture search is prevalent in the field of NAS because of its simplicity and efficiency, where two paradigms, multi-path algorithms and single-path methods, are dominated. Multi-path framework (e.g. DARTS) is intuitive but suffers from memory usage and training collapse. Single-path methods (e.g.GDAS and ProxylessNAS) mitigate the memory issue and shrink the gap between searching and evaluation but sacrifice the performance. In this paper, we propose a conceptually simple yet efficient method to bridge these two paradigms, referred as Mutually-aware Sub-Graphs Differentiable Architecture Search (MSG-DAS). The core of our framework is a differentiable Gumbel-TopK sampler that produces multiple mutually exclusive single-path sub-graphs. To alleviate the severer skip-connect issue brought by multiple sub-graphs setting, we propose a Dropblock-Identity module to stabilize the optimization. To make best use of the available models (super-net and sub-graphs), we introduce a memory-efficient super-net guidance distillation to improve training. The proposed framework strikes a balance between flexible memory usage and searching quality. We demonstrate the effectiveness of our methods on ImageNet and CIFAR10, where the searched models show a comparable performance as the most recent approaches.
A Coordinate-wise Optimization Algorithm for Sparse Inverse Covariance Selection
Apr 04, 2018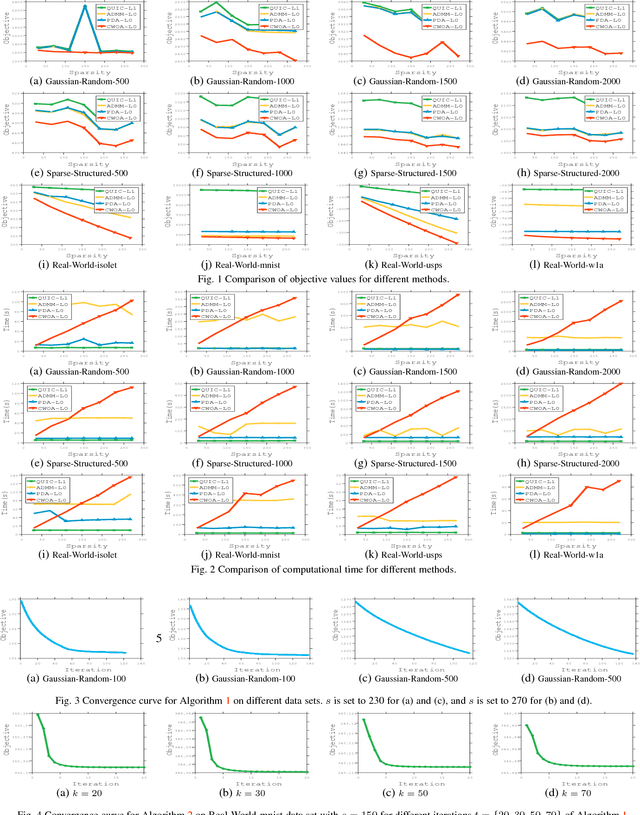
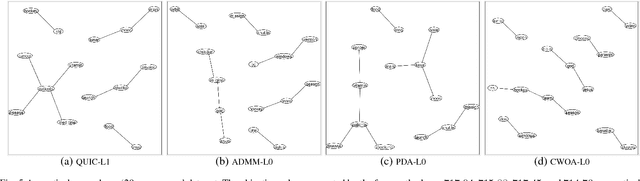
Sparse inverse covariance selection is a fundamental problem for analyzing dependencies in high dimensional data. However, such a problem is difficult to solve since it is NP-hard. Existing solutions are primarily based on convex approximation and iterative hard thresholding, which only lead to sub-optimal solutions. In this work, we propose a coordinate-wise optimization algorithm to solve this problem which is guaranteed to converge to a coordinate-wise minimum point. The algorithm iteratively and greedily selects one variable or swaps two variables to identify the support set, and then solves a reduced convex optimization problem over the support set to achieve the greatest descent. As a side contribution of this paper, we propose a Newton-like algorithm to solve the reduced convex sub-problem, which is proven to always converge to the optimal solution with global linear convergence rate and local quadratic convergence rate. Finally, we demonstrate the efficacy of our method on synthetic data and real-world data sets. As a result, the proposed method consistently outperforms existing solutions in terms of accuracy.