 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Animated Stickers: Bringing Stickers to Life with Video Diffusion
Feb 08, 2024



We introduce animated stickers, a video diffusion model which generates an animation conditioned on a text prompt and static sticker image. Our model is built on top of the state-of-the-art Emu text-to-image model, with the addition of temporal layers to model motion. Due to the domain gap, i.e. differences in visual and motion style, a model which performed well on generating natural videos can no longer generate vivid videos when applied to stickers. To bridge this gap, we employ a two-stage finetuning pipeline: first with weakly in-domain data, followed by human-in-the-loop (HITL) strategy which we term ensemble-of-teachers. It distills the best qualities of multiple teachers into a smaller student model. We show that this strategy allows us to specifically target improvements to motion quality while maintaining the style from the static image. With inference optimizations, our model is able to generate an eight-frame video with high-quality, interesting, and relevant motion in under one second.
Design of an Adaptive Lightweight LiDAR to Decouple Robot-Camera Geometry
Feb 28, 2023



A fundamental challenge in robot perception is the coupling of the sensor pose and robot pose. This has led to research in active vision where robot pose is changed to reorient the sensor to areas of interest for perception. Further, egomotion such as jitter, and external effects such as wind and others affect perception requiring additional effort in software such as image stabilization. This effect is particularly pronounced in micro-air vehicles and micro-robots who typically are lighter and subject to larger jitter but do not have the computational capability to perform stabilization in real-time. We present a novel microelectromechanical (MEMS) mirror LiDAR system to change the field of view of the LiDAR independent of the robot motion. Our design has the potential for use on small, low-power systems where the expensive components of the LiDAR can be placed external to the small robot. We show the utility of our approach in simulation and on prototype hardware mounted on a UAV. We believe that this LiDAR and its compact movable scanning design provide mechanisms to decouple robot and sensor geometry allowing us to simplify robot perception. We also demonstrate examples of motion compensation using IMU and external odometry feedback in hardware.
Graph Coarsening with Neural Networks
Feb 02, 2021

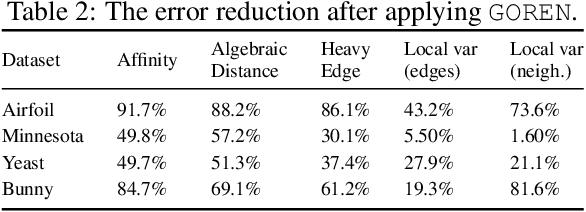
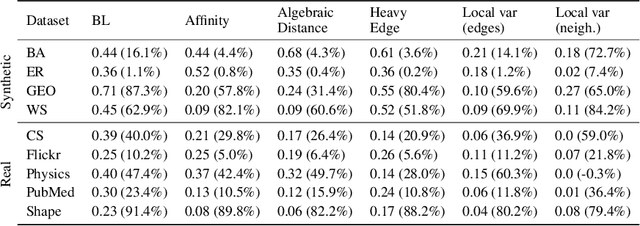
As large-scale graphs become increasingly more prevalent, it poses significant computational challenges to process, extract and analyze large graph data. Graph coarsening is one popular technique to reduce the size of a graph while maintaining essential properties. Despite rich graph coarsening literature, there is only limited exploration of data-driven methods in the field. In this work, we leverage the recent progress of deep learning on graphs for graph coarsening. We first propose a framework for measuring the quality of coarsening algorithm and show that depending on the goal, we need to carefully choose the Laplace operator on the coarse graph and associated projection/lift operators. Motivated by the observation that the current choice of edge weight for the coarse graph may be sub-optimal, we parametrize the weight assignment map with graph neural networks and train it to improve the coarsening quality in an unsupervised way. Through extensive experiments on both synthetic and real networks, we demonstrate that our method significantly improves common graph coarsening methods under various metrics, reduction ratios, graph sizes, and graph types. It generalizes to graphs of larger size ($25\times$ of training graphs), is adaptive to different losses (differentiable and non-differentiable), and scales to much larger graphs than previous work.
Detection and skeletonization of single neurons and tracer injections using topological methods
Mar 20, 2020Neuroscientific data analysis has traditionally relied on linear algebra and stochastic process theory. However, the tree-like shapes of neurons cannot be described easily as points in a vector space (the subtraction of two neuronal shapes is not a meaningful operation), and methods from computational topology are better suited to their analysis. Here we introduce methods from Discrete Morse (DM) Theory to extract the tree-skeletons of individual neurons from volumetric brain image data, and to summarize collections of neurons labelled by tracer injections. Since individual neurons are topologically trees, it is sensible to summarize the collection of neurons using a consensus tree-shape that provides a richer information summary than the traditional regional 'connectivity matrix' approach. The conceptually elegant DM approach lacks hand-tuned parameters and captures global properties of the data as opposed to previous approaches which are inherently local. For individual skeletonization of sparsely labelled neurons we obtain substantial performance gains over state-of-the-art non-topological methods (over 10% improvements in precision and faster proofreading). The consensus-tree summary of tracer injections incorporates the regional connectivity matrix information, but in addition captures the collective collateral branching patterns of the set of neurons connected to the injection site, and provides a bridge between single-neuron morphology and tracer-injection data.