 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Monitoring of Colorimetric Leaf Sensors for Precision Agriculture
May 20, 2025Current remote sensing technologies that measure crop health e.g. RGB, multispectral, hyperspectral, and LiDAR, are indirect, and cannot capture plant stress indicators directly. Instead, low-cost leaf sensors that directly interface with the crop surface present an opportunity to advance real-time direct monitoring. To this end, we co-design a sensor-detector system, where the sensor is a novel colorimetric leaf sensor that directly measures crop health in a precision agriculture setting, and the detector autonomously obtains optical signals from these leaf sensors. This system integrates a ground robot platform with an on-board monocular RGB camera and object detector to localize the leaf sensor, and a hyperspectral camera with motorized mirror and an on-board halogen light to acquire a hyperspectral reflectance image of the leaf sensor, from which a spectral response characterizing crop health can be extracted. We show a successful demonstration of our co-designed system operating in outdoor environments, obtaining spectra that are interpretable when compared to controlled laboratory-grade spectrometer measurements. The system is demonstrated in row-crop environments both indoors and outdoors where it is able to autonomously navigate, locate and obtain a hyperspectral image of all leaf sensors present, and retrieve interpretable spectral resonance from leaf sensors.
ClipRover: Zero-shot Vision-Language Exploration and Target Discovery by Mobile Robots
Feb 12, 2025Vision-language navigation (VLN) has emerged as a promising paradigm, enabling mobile robots to perform zero-shot inference and execute tasks without specific pre-programming. However, current systems often separate map exploration and path planning, with exploration relying on inefficient algorithms due to limited (partially observed) environmental information. In this paper, we present a novel navigation pipeline named ''ClipRover'' for simultaneous exploration and target discovery in unknown environments, leveraging the capabilities of a vision-language model named CLIP. Our approach requires only monocular vision and operates without any prior map or knowledge about the target. For comprehensive evaluations, we design the functional prototype of a UGV (unmanned ground vehicle) system named ''Rover Master'', a customized platform for general-purpose VLN tasks. We integrate and deploy the ClipRover pipeline on Rover Master to evaluate its throughput, obstacle avoidance capability, and trajectory performance across various real-world scenarios. Experimental results demonstrate that ClipRover consistently outperforms traditional map traversal algorithms and achieves performance comparable to path-planning methods that depend on prior map and target knowledge. Notably, ClipRover offers real-time active navigation without requiring pre-captured candidate images or pre-built node graphs, addressing key limitations of existing VLN pipelines.
FoveaSPAD: Exploiting Depth Priors for Adaptive and Efficient Single-Photon 3D Imaging
Dec 03, 2024



Fast, efficient, and accurate depth-sensing is important for safety-critical applications such as autonomous vehicles. Direct time-of-flight LiDAR has the potential to fulfill these demands, thanks to its ability to provide high-precision depth measurements at long standoff distances. While conventional LiDAR relies on avalanche photodiodes (APDs), single-photon avalanche diodes (SPADs) are an emerging image-sensing technology that offer many advantages such as extreme sensitivity and time resolution. In this paper, we remove the key challenges to widespread adoption of SPAD-based LiDARs: their susceptibility to ambient light and the large amount of raw photon data that must be processed to obtain in-pixel depth estimates. We propose new algorithms and sensing policies that improve signal-to-noise ratio (SNR) and increase computing and memory efficiency for SPAD-based LiDARs. During capture, we use external signals to \emph{foveate}, i.e., guide how the SPAD system estimates scene depths. This foveated approach allows our method to ``zoom into'' the signal of interest, reducing the amount of raw photon data that needs to be stored and transferred from the SPAD sensor, while also improving resilience to ambient light. We show results both in simulation and also with real hardware emulation, with specific implementations achieving a 1548-fold reduction in memory usage, and our algorithms can be applied to newly available and future SPAD arrays.
Cost-efficient Active Illumination Camera For Hyper-spectral Reconstruction
Jun 27, 2024
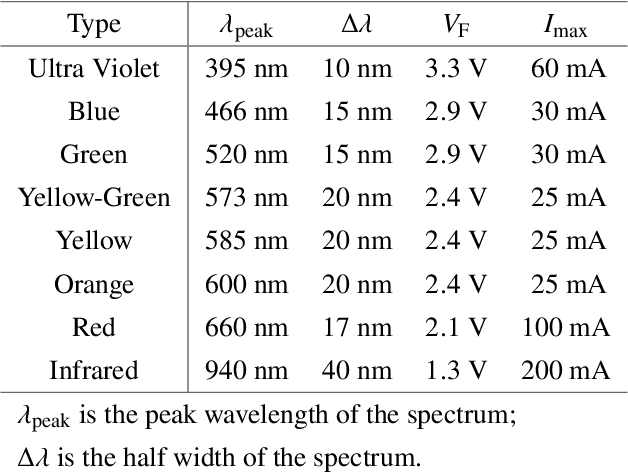

Hyper-spectral imaging has recently gained increasing attention for use in different applications, including agricultural investigation, ground tracking, remote sensing and many other. However, the high cost, large physical size and complicated operation process stop hyperspectral cameras from being employed for various applications and research fields. In this paper, we introduce a cost-efficient, compact and easy to use active illumination camera that may benefit many applications. We developed a fully functional prototype of such camera. With the hope of helping with agricultural research, we tested our camera for plant root imaging. In addition, a U-Net model for spectral reconstruction was trained by using a reference hyperspectral camera's data as ground truth and our camera's data as input. We demonstrated our camera's ability to obtain additional information over a typical RGB camera. In addition, the ability to reconstruct hyperspectral data from multi-spectral input makes our device compatible to models and algorithms developed for hyperspectral applications with no modifications required.
SpectralZoom: Efficient Segmentation with an Adaptive Hyperspectral Camera
Jun 06, 2024



Hyperspectral image segmentation is crucial for many fields such as agriculture, remote sensing, biomedical imaging, battlefield sensing and astronomy. However, the challenge of hyper and multi spectral imaging is its large data footprint. We propose both a novel camera design and a vision transformer-based (ViT) algorithm that alleviate both the captured data footprint and the computational load for hyperspectral segmentation. Our camera is able to adaptively sample image regions or patches at different resolutions, instead of capturing the entire hyperspectral cube at one high resolution. Our segmentation algorithm works in concert with the camera, applying ViT-based segmentation only to adaptively selected patches. We show results both in simulation and on a real hardware platform demonstrating both accurate segmentation results and reduced computational burden.
Schrödinger's Camera: First Steps Towards a Quantum-Based Privacy Preserving Camera
Mar 13, 2023Privacy-preserving vision must overcome the dual challenge of utility and privacy. Too much anonymity renders the images useless, but too little privacy does not protect sensitive data. We propose a novel design for privacy preservation, where the imagery is stored in quantum states. In the future, this will be enabled by quantum imaging cameras, and, currently, storing very low resolution imagery in quantum states is possible. Quantum state imagery has the advantage of being both private and non-private till the point of measurement. This occurs even when images are manipulated, since every quantum action is fully reversible. We propose a control algorithm, based on double deep Q-learning, to learn how to anonymize the image before measurement. After learning, the RL weights are fixed, and new attack neural networks are trained from scratch to break the system's privacy. Although all our results are in simulation, we demonstrate, with these first steps, that it is possible to control both privacy and utility in a quantum-based manner.
Design of an Adaptive Lightweight LiDAR to Decouple Robot-Camera Geometry
Feb 28, 2023



A fundamental challenge in robot perception is the coupling of the sensor pose and robot pose. This has led to research in active vision where robot pose is changed to reorient the sensor to areas of interest for perception. Further, egomotion such as jitter, and external effects such as wind and others affect perception requiring additional effort in software such as image stabilization. This effect is particularly pronounced in micro-air vehicles and micro-robots who typically are lighter and subject to larger jitter but do not have the computational capability to perform stabilization in real-time. We present a novel microelectromechanical (MEMS) mirror LiDAR system to change the field of view of the LiDAR independent of the robot motion. Our design has the potential for use on small, low-power systems where the expensive components of the LiDAR can be placed external to the small robot. We show the utility of our approach in simulation and on prototype hardware mounted on a UAV. We believe that this LiDAR and its compact movable scanning design provide mechanisms to decouple robot and sensor geometry allowing us to simplify robot perception. We also demonstrate examples of motion compensation using IMU and external odometry feedback in hardware.
SaccadeCam: Adaptive Visual Attention for Monocular Depth Sensing
Mar 26, 2021



Most monocular depth sensing methods use conventionally captured images that are created without considering scene content. In contrast, animal eyes have fast mechanical motions, called saccades, that control how the scene is imaged by the fovea, where resolution is highest. In this paper, we present the SaccadeCam framework for adaptively distributing resolution onto regions of interest in the scene. Our algorithm for adaptive resolution is a self-supervised network and we demonstrate results for end-to-end learning for monocular depth estimation. We also show preliminary results with a real SaccadeCam hardware prototype.
A MEMS-based Foveating LIDAR to enable Real-time Adaptive Depth Sensing
Mar 21, 2020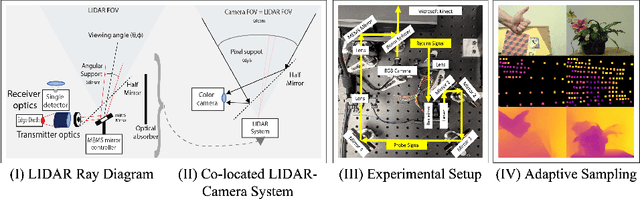


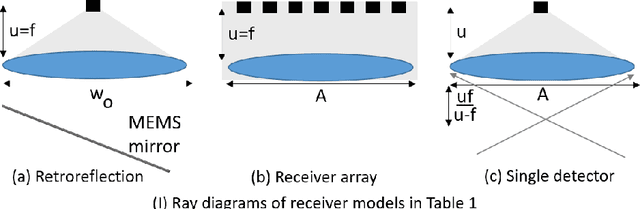
Most active depth sensors sample their visual field using a fixed pattern, decided by accuracy, speed and cost trade-offs, rather than scene content. However, a number of recent works have demonstrated that adapting measurement patterns to scene content can offer significantly better trade-offs. We propose a hardware LIDAR design that allows flexible real-time measurements according to dynamically specified measurement patterns. Our flexible depth sensor design consists of a controllable scanning LIDAR that can foveate, or increase resolution in regions of interest, and that can fully leverage the power of adaptive depth sensing. We describe our optical setup and calibration, which enables fast sparse depth measurements using a scanning MEMS (micro-electro mechanical) mirror. We validate the efficacy of our prototype LIDAR design by testing on over 75 static and dynamic scenes spanning a range of environments. We also show CNN-based depth-map completion of sparse measurements obtained by our sensor. Our experiments show that our sensor can realize adaptive depth sensing systems.
Revealing Scenes by Inverting Structure from Motion Reconstructions
Apr 05, 2019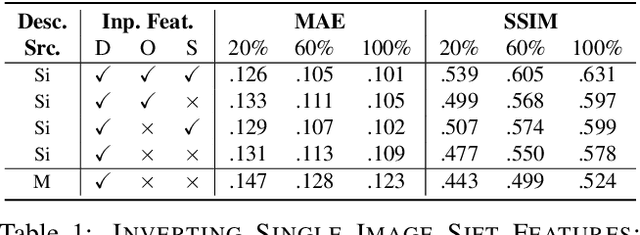
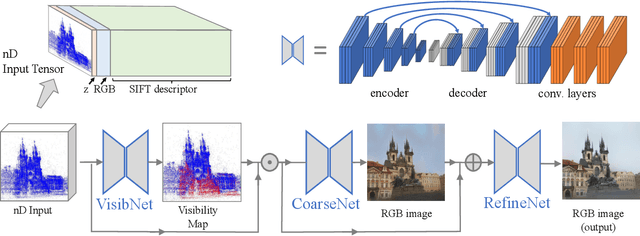
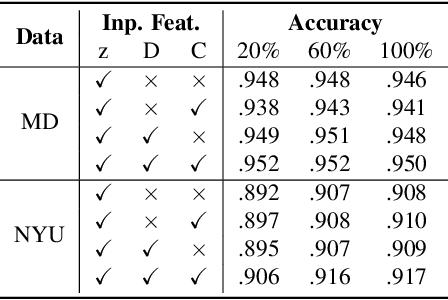

Many 3D vision systems localize cameras within a scene using 3D point clouds. Such point clouds are often obtained using structure from motion (SfM), after which the images are discarded to preserve privacy. In this paper, we show, for the first time, that such point clouds retain enough information to reveal scene appearance and compromise privacy. We present a privacy attack that reconstructs color images of the scene from the point cloud. Our method is based on a cascaded U-Net that takes as input, a 2D multichannel image of the points rendered from a specific viewpoint containing point depth and optionally color and SIFT descriptors and outputs a color image of the scene from that viewpoint. Unlike previous feature inversion methods, we deal with highly sparse and irregular 2D point distributions and inputs where many point attributes are missing, namely keypoint orientation and scale, the descriptor image source and the 3D point visibility. We evaluate our attack algorithm on public datasets and analyze the significance of the point cloud attributes. Finally, we show that novel views can also be generated thereby enabling compelling virtual tours of the underlying scene.