 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemeSys: An Online Underwater Explorer with Goal-Driven Adaptive Autonomy
Jul 16, 2025



Adaptive mission control and dynamic parameter reconfiguration are essential for autonomous underwater vehicles (AUVs) operating in GPS-denied, communication-limited marine environments. However, most current AUV platforms execute static, pre-programmed missions or rely on tethered connections and high-latency acoustic channels for mid-mission updates, significantly limiting their adaptability and responsiveness. In this paper, we introduce NemeSys, a novel AUV system designed to support real-time mission reconfiguration through compact optical and magnetoelectric (OME) signaling facilitated by floating buoys. We present the full system design, control architecture, and a semantic mission encoding framework that enables interactive exploration and task adaptation via low-bandwidth communication. The proposed system is validated through analytical modeling, controlled experimental evaluations, and open-water trials. Results confirm the feasibility of online mission adaptation and semantic task updates, highlighting NemeSys as an online AUV platform for goal-driven adaptive autonomy in dynamic and uncertain underwater environments.
ClipRover: Zero-shot Vision-Language Exploration and Target Discovery by Mobile Robots
Feb 12, 2025Vision-language navigation (VLN) has emerged as a promising paradigm, enabling mobile robots to perform zero-shot inference and execute tasks without specific pre-programming. However, current systems often separate map exploration and path planning, with exploration relying on inefficient algorithms due to limited (partially observed) environmental information. In this paper, we present a novel navigation pipeline named ''ClipRover'' for simultaneous exploration and target discovery in unknown environments, leveraging the capabilities of a vision-language model named CLIP. Our approach requires only monocular vision and operates without any prior map or knowledge about the target. For comprehensive evaluations, we design the functional prototype of a UGV (unmanned ground vehicle) system named ''Rover Master'', a customized platform for general-purpose VLN tasks. We integrate and deploy the ClipRover pipeline on Rover Master to evaluate its throughput, obstacle avoidance capability, and trajectory performance across various real-world scenarios. Experimental results demonstrate that ClipRover consistently outperforms traditional map traversal algorithms and achieves performance comparable to path-planning methods that depend on prior map and target knowledge. Notably, ClipRover offers real-time active navigation without requiring pre-captured candidate images or pre-built node graphs, addressing key limitations of existing VLN pipelines.
Demonstrating CavePI: Autonomous Exploration of Underwater Caves by Semantic Guidance
Feb 07, 2025



Enabling autonomous robots to safely and efficiently navigate, explore, and map underwater caves is of significant importance to water resource management, hydrogeology, archaeology, and marine robotics. In this work, we demonstrate the system design and algorithmic integration of a visual servoing framework for semantically guided autonomous underwater cave exploration. We present the hardware and edge-AI design considerations to deploy this framework on a novel AUV (Autonomous Underwater Vehicle) named CavePI. The guided navigation is driven by a computationally light yet robust deep visual perception module, delivering a rich semantic understanding of the environment. Subsequently, a robust control mechanism enables CavePI to track the semantic guides and navigate within complex cave structures. We evaluate the system through field experiments in natural underwater caves and spring-water sites and further validate its ROS (Robot Operating System)-based digital twin in a simulation environment. Our results highlight how these integrated design choices facilitate reliable navigation under feature-deprived, GPS-denied, and low-visibility conditions.
Human-Machine Interfaces for Subsea Telerobotics: From Soda-straw to Natural Language Interactions
Dec 02, 2024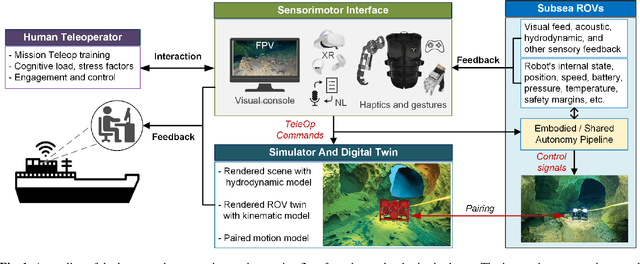
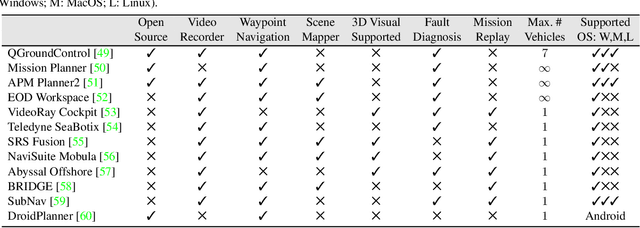
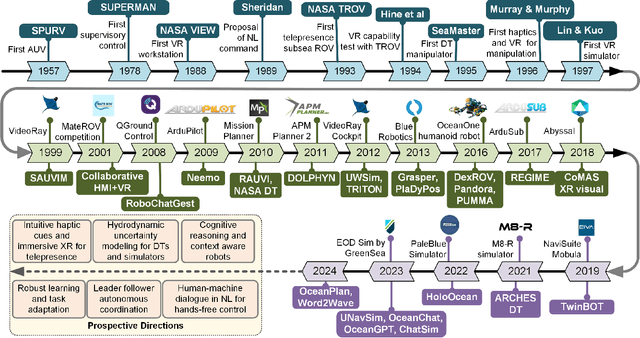
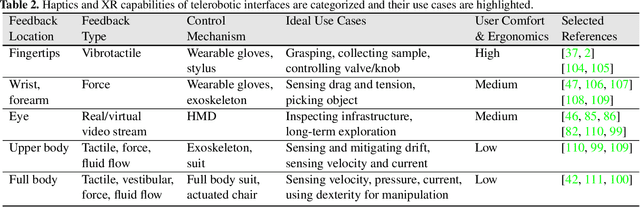
This review explores the evolution of human-machine interfaces (HMIs) for subsea telerobotics, tracing back the transition from traditional first-person "soda-straw" consoles (narrow field-of-view camera feed) to advanced interfaces powered by gesture recognition, virtual reality, and natural language models. First, we discuss various forms of subsea telerobotics applications, current state-of-the-art (SOTA) interface systems, and the challenges they face in robust underwater sensing, real-time estimation, and low-latency communication. Through this analysis, we highlight how advanced HMIs facilitate intuitive interactions between human operators and robots to overcome these challenges. A detailed review then categorizes and evaluates the cutting-edge HMI systems based on their offered features from both human perspectives (e.g., enhancing operator control and situational awareness) and machine perspectives (e.g., improving safety, mission accuracy, and task efficiency). Moreover, we examine the literature on bidirectional interaction and intelligent collaboration in terms of sensory feedback and intuitive control mechanisms for both physical and virtual interfaces. The paper concludes by identifying critical challenges, open research questions, and future directions, emphasizing the need for multidisciplinary collaboration in subsea telerobotics.
Word2Wave: Language Driven Mission Programming for Efficient Subsea Deployments of Marine Robots
Sep 27, 2024



This paper explores the design and development of a language-based interface for dynamic mission programming of autonomous underwater vehicles (AUVs). The proposed 'Word2Wave' (W2W) framework enables interactive programming and parameter configuration of AUVs for remote subsea missions. The W2W framework includes: (i) a set of novel language rules and command structures for efficient language-to-mission mapping; (ii) a GPT-based prompt engineering module for training data generation; (iii) a small language model (SLM)-based sequence-to-sequence learning pipeline for mission command generation from human speech or text; and (iv) a novel user interface for 2D mission map visualization and human-machine interfacing. The proposed learning pipeline adapts an SLM named T5-Small that can learn language-to-mission mapping from processed language data effectively, providing robust and efficient performance. In addition to a benchmark evaluation with state-of-the-art, we conduct a user interaction study to demonstrate the effectiveness of W2W over commercial AUV programming interfaces. Across participants, W2W-based programming required less than 10% time for mission programming compared to traditional interfaces; it is deemed to be a simpler and more natural paradigm for subsea mission programming with a usability score of 76.25. W2W opens up promising future research opportunities on hands-free AUV mission programming for efficient subsea deployments.
Ego-to-Exo: Interfacing Third Person Visuals from Egocentric Views in Real-time for Improved ROV Teleoperation
Jun 30, 2024



Underwater ROVs (Remotely Operated Vehicles) are unmanned submersible vehicles designed for exploring and operating in the depths of the ocean. Despite using high-end cameras, typical teleoperation engines based on first-person (egocentric) views limit a surface operator's ability to maneuver and navigate the ROV in complex deep-water missions. In this paper, we present an interactive teleoperation interface that (i) offers on-demand "third"-person (exocentric) visuals from past egocentric views, and (ii) facilitates enhanced peripheral information with augmented ROV pose in real-time. We achieve this by integrating a 3D geometry-based Ego-to-Exo view synthesis algorithm into a monocular SLAM system for accurate trajectory estimation. The proposed closed-form solution only uses past egocentric views from the ROV and a SLAM backbone for pose estimation, which makes it portable to existing ROV platforms. Unlike data-driven solutions, it is invariant to applications and waterbody-specific scenes. We validate the geometric accuracy of the proposed framework through extensive experiments of 2-DOF indoor navigation and 6-DOF underwater cave exploration in challenging low-light conditions. We demonstrate the benefits of dynamic Ego-to-Exo view generation and real-time pose rendering for remote ROV teleoperation by following navigation guides such as cavelines inside underwater caves. This new way of interactive ROV teleoperation opens up promising opportunities for future research in underwater telerobotics.