 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototypical Metric Transfer Learning for Continuous Speech Keyword Spotting With Limited Training Data
Paper and Code

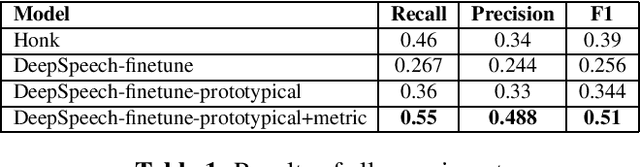
Continuous Speech Keyword Spotting (CSKS) is the problem of spotting keywords in recorded conversations, when a small number of instances of keywords are available in training data. Unlike the more common Keyword Spotting, where an algorithm needs to detect lone keywords or short phrases like "Alexa", "Cortana", "Hi Alexa!", "Whatsup Octavia?" etc. in speech, CSKS needs to filter out embedded words from a continuous flow of speech, ie. spot "Anna" and "github" in "I know a developer named Anna who can look into this github issue." Apart from the issue of limited training data availability, CSKS is an extremely imbalanced classification problem. We address the limitations of simple keyword spotting baselines for both aforementioned challenges by using a novel combination of loss functions (Prototypical networks' loss and metric loss) and transfer learning. Our method improves F1 score by over 10%.