 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedDChest: A Content-Aware Multimodal Foundational Vision Model for Thoracic Imaging
Nov 06, 2025The performance of vision models in medical imaging is often hindered by the prevailing paradigm of fine-tuning backbones pre-trained on out-of-domain natural images. To address this fundamental domain gap, we propose MedDChest, a new foundational Vision Transformer (ViT) model optimized specifically for thoracic imaging. We pre-trained MedDChest from scratch on a massive, curated, multimodal dataset of over 1.2 million images, encompassing different modalities including Chest X-ray and Computed Tomography (CT) compiled from 10 public sources. A core technical contribution of our work is Guided Random Resized Crops, a novel content-aware data augmentation strategy that biases sampling towards anatomically relevant regions, overcoming the inefficiency of standard cropping techniques on medical scans. We validate our model's effectiveness by fine-tuning it on a diverse set of downstream diagnostic tasks. Comprehensive experiments empirically demonstrate that MedDChest significantly outperforms strong, publicly available ImageNet-pretrained models. By establishing the superiority of large-scale, in-domain pre-training combined with domain-specific data augmentation, MedDChest provides a powerful and robust feature extractor that serves as a significantly better starting point for a wide array of thoracic diagnostic tasks. The model weights will be made publicly available to foster future research and applications.
Universal Medical Imaging Model for Domain Generalization with Data Privacy
Jul 20, 2024



Achieving domain generalization in medical imaging poses a significant challenge, primarily due to the limited availability of publicly labeled datasets in this domain. This limitation arises from concerns related to data privacy and the necessity for medical expertise to accurately label the data. In this paper, we propose a federated learning approach to transfer knowledge from multiple local models to a global model, eliminating the need for direct access to the local datasets used to train each model. The primary objective is to train a global model capable of performing a wide variety of medical imaging tasks. This is done while ensuring the confidentiality of the private datasets utilized during the training of these models. To validate the effectiveness of our approach, extensive experiments were conducted on eight datasets, each corresponding to a different medical imaging application. The client's data distribution in our experiments varies significantly as they originate from diverse domains. Despite this variation, we demonstrate a statistically significant improvement over a state-of-the-art baseline utilizing masked image modeling over a diverse pre-training dataset that spans different body parts and scanning types. This improvement is achieved by curating information learned from clients without accessing any labeled dataset on the server.
MedMAE: A Self-Supervised Backbone for Medical Imaging Tasks
Jul 20, 2024



Medical imaging tasks are very challenging due to the lack of publicly available labeled datasets. Hence, it is difficult to achieve high performance with existing deep-learning models as they require a massive labeled dataset to be trained effectively. An alternative solution is to use pre-trained models and fine-tune them using the medical imaging dataset. However, all existing models are pre-trained using natural images, which is a completely different domain from that of medical imaging, which leads to poor performance due to domain shift. To overcome these problems, we propose a large-scale unlabeled dataset of medical images and a backbone pre-trained using the proposed dataset with a self-supervised learning technique called Masked autoencoder. This backbone can be used as a pre-trained model for any medical imaging task, as it is trained to learn a visual representation of different types of medical images. To evaluate the performance of the proposed backbone, we used four different medical imaging tasks. The results are compared with existing pre-trained models. These experiments show the superiority of our proposed backbone in medical imaging tasks.
Lifelong Learning Using a Dynamically Growing Tree of Sub-networks for Domain Generalization in Video Object Segmentation
May 29, 2024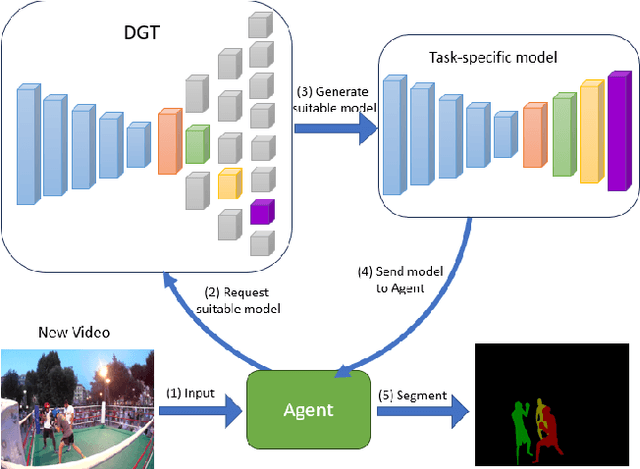
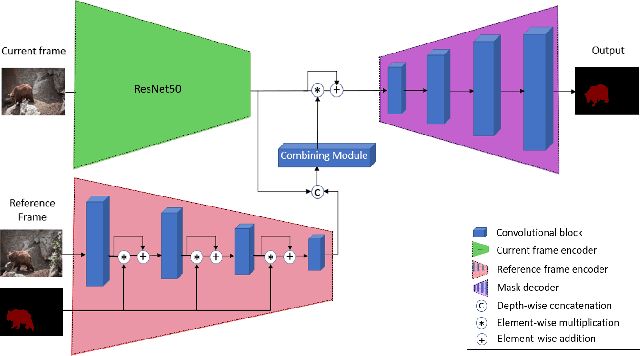
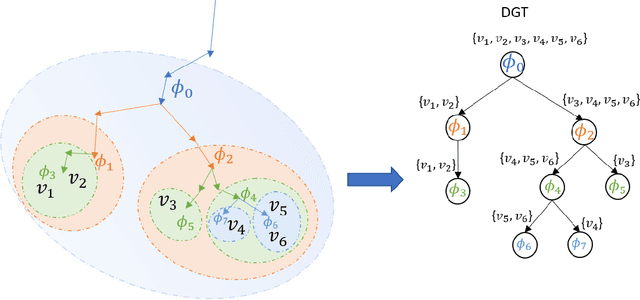
Current state-of-the-art video object segmentation models have achieved great success using supervised learning with massive labeled training datasets. However, these models are trained using a single source domain and evaluated using videos sampled from the same source domain. When these models are evaluated using videos sampled from a different target domain, their performance degrades significantly due to poor domain generalization, i.e., their inability to learn from multi-domain sources simultaneously using traditional supervised learning. In this paper, We propose a dynamically growing tree of sub-networks (DGT) to learn effectively from multi-domain sources. DGT uses a novel lifelong learning technique that allows the model to continuously and effectively learn from new domains without forgetting the previously learned domains. Hence, the model can generalize to out-of-domain videos. The proposed work is evaluated using single-source in-domain (traditional video object segmentation), multi-source in-domain, and multi-source out-of-domain video object segmentation. The results of DGT show a single source in-domain performance gain of 0.2% and 3.5% on the DAVIS16 and DAVIS17 datasets, respectively. However, when DGT is evaluated using in-domain multi-sources, the results show superior performance compared to state-of-the-art video object segmentation and other lifelong learning techniques with an average performance increase in the F-score of 6.9% with minimal catastrophic forgetting. Finally, in the out-of-domain experiment, the performance of DGT is 2.7% and 4% better than state-of-the-art in 1 and 5-shots, respectively.