 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGNN-MoE: Context-Aware Patch Routing using GNNs for Parameter-Efficient Domain Generalization
Nov 06, 2025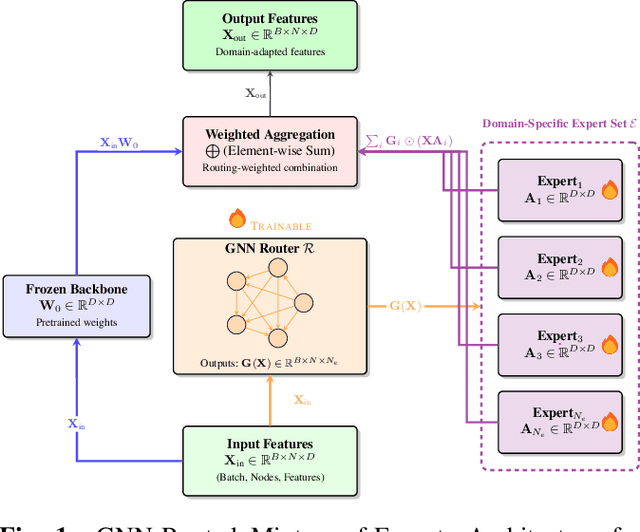
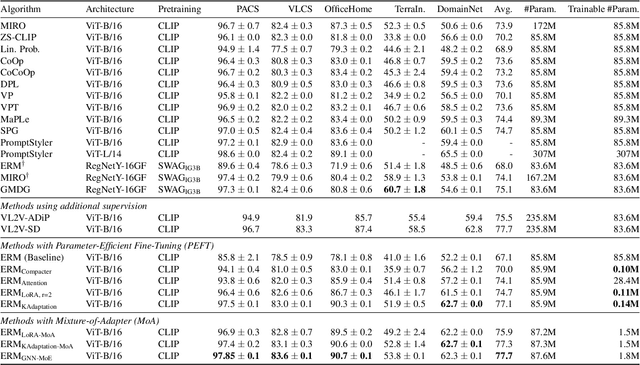

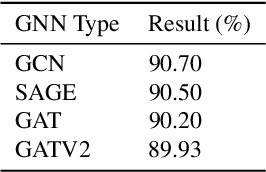
Domain generalization (DG) seeks robust Vision Transformer (ViT) performance on unseen domains. Efficiently adapting pretrained ViTs for DG is challenging; standard fine-tuning is costly and can impair generalization. We propose GNN-MoE, enhancing Parameter-Efficient Fine-Tuning (PEFT) for DG with a Mixture-of-Experts (MoE) framework using efficient Kronecker adapters. Instead of token-based routing, a novel Graph Neural Network (GNN) router (GCN, GAT, SAGE) operates on inter-patch graphs to dynamically assign patches to specialized experts. This context-aware GNN routing leverages inter-patch relationships for better adaptation to domain shifts. GNN-MoE achieves state-of-the-art or competitive DG benchmark performance with high parameter efficiency, highlighting the utility of graph-based contextual routing for robust, lightweight DG.
Universal Medical Imaging Model for Domain Generalization with Data Privacy
Jul 20, 2024



Achieving domain generalization in medical imaging poses a significant challenge, primarily due to the limited availability of publicly labeled datasets in this domain. This limitation arises from concerns related to data privacy and the necessity for medical expertise to accurately label the data. In this paper, we propose a federated learning approach to transfer knowledge from multiple local models to a global model, eliminating the need for direct access to the local datasets used to train each model. The primary objective is to train a global model capable of performing a wide variety of medical imaging tasks. This is done while ensuring the confidentiality of the private datasets utilized during the training of these models. To validate the effectiveness of our approach, extensive experiments were conducted on eight datasets, each corresponding to a different medical imaging application. The client's data distribution in our experiments varies significantly as they originate from diverse domains. Despite this variation, we demonstrate a statistically significant improvement over a state-of-the-art baseline utilizing masked image modeling over a diverse pre-training dataset that spans different body parts and scanning types. This improvement is achieved by curating information learned from clients without accessing any labeled dataset on the server.
FedPartWhole: Federated domain generalization via consistent part-whole hierarchies
Jul 20, 2024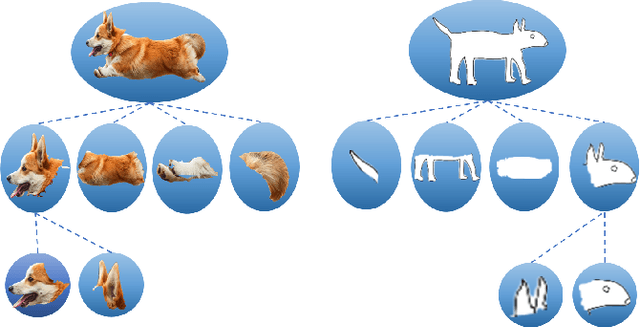
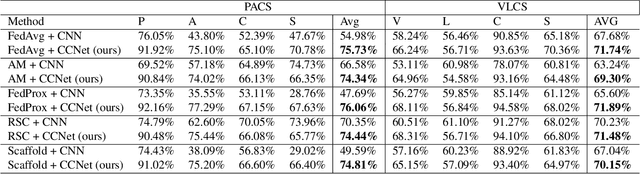
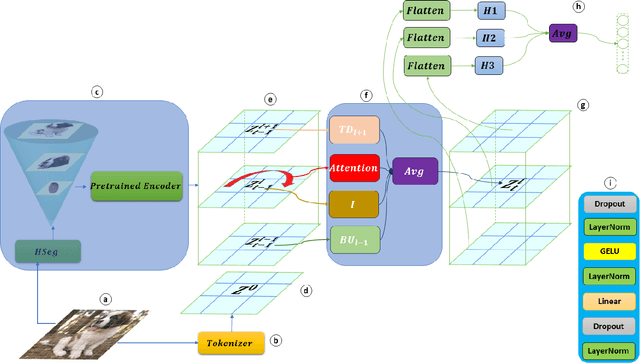

Federated Domain Generalization (FedDG), aims to tackle the challenge of generalizing to unseen domains at test time while catering to the data privacy constraints that prevent centralized data storage from different domains originating at various clients. Existing approaches can be broadly categorized into four groups: domain alignment, data manipulation, learning strategies, and optimization of model aggregation weights. This paper proposes a novel approach to Federated Domain Generalization that tackles the problem from the perspective of the backbone model architecture. The core principle is that objects, even under substantial domain shifts and appearance variations, maintain a consistent hierarchical structure of parts and wholes. For instance, a photograph and a sketch of a dog share the same hierarchical organization, consisting of a head, body, limbs, and so on. The introduced architecture explicitly incorporates a feature representation for the image parse tree. To the best of our knowledge, this is the first work to tackle Federated Domain Generalization from a model architecture standpoint. Our approach outperforms a convolutional architecture of comparable size by over 12\%, despite utilizing fewer parameters. Additionally, it is inherently interpretable, contrary to the black-box nature of CNNs, which fosters trust in its predictions, a crucial asset in federated learning.
UAV-assisted Visual SLAM Generating Reconstructed 3D Scene Graphs in GPS-denied Environments
Feb 12, 2024
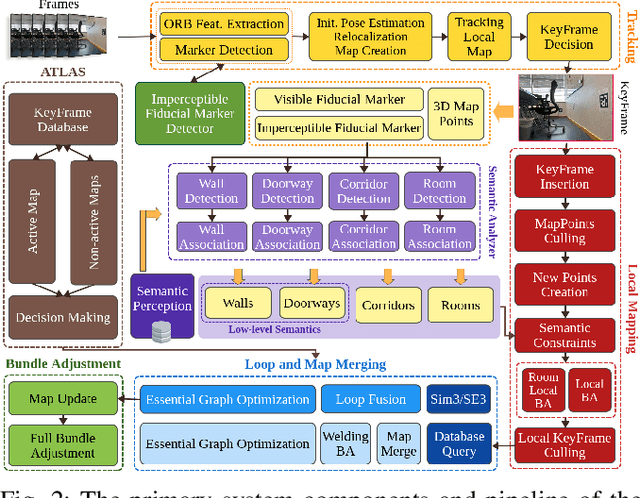

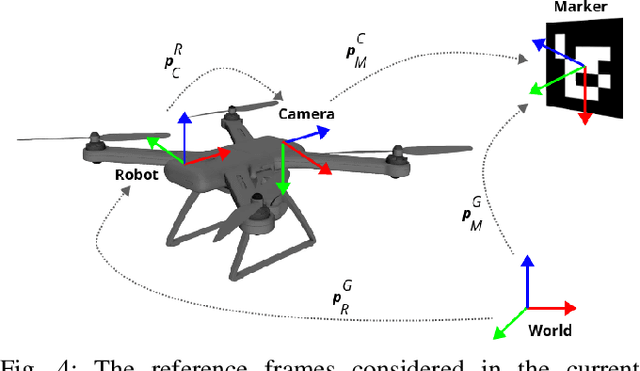
Aerial robots play a vital role in various applications where the situational awareness of the robots concerning the environment is a fundamental demand. As one such use case, drones in GPS-denied environments require equipping with different sensors (e.g., vision sensors) that provide reliable sensing results while performing pose estimation and localization. In this paper, reconstructing the maps of indoor environments alongside generating 3D scene graphs for a high-level representation using a camera mounted on a drone is targeted. Accordingly, an aerial robot equipped with a companion computer and an RGB-D camera was built and employed to be appropriately integrated with a Visual Simultaneous Localization and Mapping (VSLAM) framework proposed by the authors. To enhance the situational awareness of the robot while reconstructing maps, various structural elements, including doors and walls, were labeled with printed fiducial markers, and a dictionary of the topological relations among them was fed to the system. The VSLAM system detects markers and reconstructs the map of the indoor areas enriched with higher-level semantic entities, including corridors and rooms. Another achievement is generating multi-layered vision-based situational graphs containing enhanced hierarchical representations of the indoor environment. In this regard, integrating VSLAM into the employed drone is the primary target of this paper to provide an end-to-end robot application for GPS-denied environments. To show the practicality of the system, various real-world condition experiments have been conducted in indoor scenarios with dissimilar structural layouts. Evaluations show the proposed drone application can perform adequately w.r.t. the ground-truth data and its baseline.
Addressing Bias Through Ensemble Learning and Regularized Fine-Tuning
Feb 01, 2024Addressing biases in AI models is crucial for ensuring fair and accurate predictions. However, obtaining large, unbiased datasets for training can be challenging. This paper proposes a comprehensive approach using multiple methods to remove bias in AI models, with only a small dataset and a potentially biased pretrained model. We train multiple models with the counter-bias of the pre-trained model through data splitting, local training, and regularized fine-tuning, gaining potentially counter-biased models. Then, we employ ensemble learning for all models to reach unbiased predictions. To further accelerate the inference time of our ensemble model, we conclude our solution with knowledge distillation that results in a single unbiased neural network. We demonstrate the effectiveness of our approach through experiments on the CIFAR10 and HAM10000 datasets, showcasing promising results. This work contributes to the ongoing effort to create more unbiased and reliable AI models, even with limited data availability.
Investigating certain choices of CNN configurations for brain lesion segmentation
Dec 02, 2022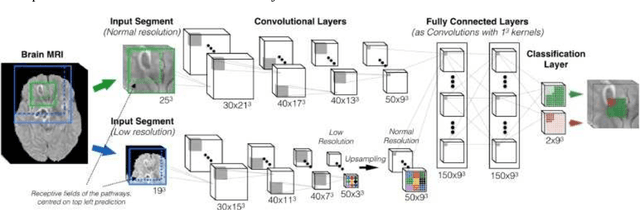

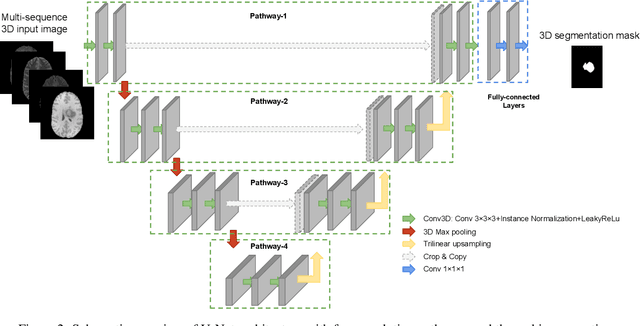

Brain tumor imaging has been part of the clinical routine for many years to perform non-invasive detection and grading of tumors. Tumor segmentation is a crucial step for managing primary brain tumors because it allows a volumetric analysis to have a longitudinal follow-up of tumor growth or shrinkage to monitor disease progression and therapy response. In addition, it facilitates further quantitative analysis such as radiomics. Deep learning models, in particular CNNs, have been a methodology of choice in many applications of medical image analysis including brain tumor segmentation. In this study, we investigated the main design aspects of CNN models for the specific task of MRI-based brain tumor segmentation. Two commonly used CNN architectures (i.e. DeepMedic and U-Net) were used to evaluate the impact of the essential parameters such as learning rate, batch size, loss function, and optimizer. The performance of CNN models using different configurations was assessed with the BraTS 2018 dataset to determine the most performant model. Then, the generalization ability of the model was assessed using our in-house dataset. For all experiments, U-Net achieved a higher DSC compared to the DeepMedic. However, the difference was only statistically significant for whole tumor segmentation using FLAIR sequence data and tumor core segmentation using T1w sequence data. Adam and SGD both with the initial learning rate set to 0.001 provided the highest segmentation DSC when training the CNN model using U-Net and DeepMedic architectures, respectively. No significant difference was observed when using different normalization approaches. In terms of loss functions, a weighted combination of soft Dice and cross-entropy loss with the weighting term set to 0.5 resulted in an improved segmentation performance and training stability for both DeepMedic and U-Net models.