 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware, Algorithms, and Applications of the Neuromorphic Vision Sensor: a Review
Apr 11, 2025Neuromorphic, or event, cameras represent a transformation in the classical approach to visual sensing encodes detected instantaneous per-pixel illumination changes into an asynchronous stream of event packets. Their novelty compared to standard cameras lies in the transition from capturing full picture frames at fixed time intervals to a sparse data format which, with its distinctive qualities, offers potential improvements in various applications. However, these advantages come at the cost of reinventing algorithmic procedures or adapting them to effectively process the new data format. In this survey, we systematically examine neuromorphic vision along three main dimensions. First, we highlight the technological evolution and distinctive hardware features of neuromorphic cameras from their inception to recent models. Second, we review image processing algorithms developed explicitly for event-based data, covering key works on feature detection, tracking, and optical flow -which form the basis for analyzing image elements and transformations -as well as depth and pose estimation or object recognition, which interpret more complex scene structures and components. These techniques, drawn from classical computer vision and modern data-driven approaches, are examined to illustrate the breadth of applications for event-based cameras. Third, we present practical application case studies demonstrating how event cameras have been successfully used across various industries and scenarios. Finally, we analyze the challenges limiting widespread adoption, identify significant research gaps compared to standard imaging techniques, and outline promising future directions and opportunities that neuromorphic vision offers.
Category-level Meta-learned NeRF Priors for Efficient Object Mapping
Mar 05, 2025In 3D object mapping, category-level priors enable efficient object reconstruction and canonical pose estimation, requiring only a single prior per semantic category (e.g., chair, book, laptop). Recently, DeepSDF has predominantly been used as a category-level shape prior, but it struggles to reconstruct sharp geometry and is computationally expensive. In contrast, NeRFs capture fine details but have yet to be effectively integrated with category-level priors in a real-time multi-object mapping framework. To bridge this gap, we introduce PRENOM, a Prior-based Efficient Neural Object Mapper that integrates category-level priors with object-level NeRFs to enhance reconstruction efficiency while enabling canonical object pose estimation. PRENOM gets to know objects on a first-name basis by meta-learning on synthetic reconstruction tasks generated from open-source shape datasets. To account for object category variations, it employs a multi-objective genetic algorithm to optimize the NeRF architecture for each category, balancing reconstruction quality and training time. Additionally, prior-based probabilistic ray sampling directs sampling toward expected object regions, accelerating convergence and improving reconstruction quality under constrained resources. Experimental results on a low-end GPU highlight the ability of PRENOM to achieve high-quality reconstructions while maintaining computational feasibility. Specifically, comparisons with prior-free NeRF-based approaches on a synthetic dataset show a 21% lower Chamfer distance, demonstrating better reconstruction quality. Furthermore, evaluations against other approaches using shape priors on a noisy real-world dataset indicate a 13% improvement averaged across all reconstruction metrics, and comparable pose and size estimation accuracy, while being trained for 5x less time.
Constraint-Based Modeling of Dynamic Entities in 3D Scene Graphs for Robust SLAM
Mar 03, 2025Autonomous robots depend crucially on their ability to perceive and process information from dynamic, ever-changing environments. Traditional simultaneous localization and mapping (SLAM) approaches struggle to maintain consistent scene representations because of numerous moving objects, often treating dynamic elements as outliers rather than explicitly modeling them in the scene representation. In this paper, we present a novel hierarchical 3D scene graph-based SLAM framework that addresses the challenge of modeling and estimating the pose of dynamic objects and agents. We use fiducial markers to detect dynamic entities and to extract their attributes while improving keyframe selection and implementing new capabilities for dynamic entity mapping. We maintain a hierarchical representation where dynamic objects are registered in the SLAM graph and are constrained with robot keyframes and the floor level of the building with our novel entity-keyframe constraints and intra-entity constraints. By combining semantic and geometric constraints between dynamic entities and the environment, our system jointly optimizes the SLAM graph to estimate the pose of the robot and various dynamic agents and objects while maintaining an accurate map. Experimental evaluation demonstrates that our approach achieves a 27.57% reduction in pose estimation error compared to traditional methods and enables higher-level reasoning about scene dynamics.
vS-Graphs: Integrating Visual SLAM and Situational Graphs through Multi-level Scene Understanding
Mar 03, 2025Current Visual Simultaneous Localization and Mapping (VSLAM) systems often struggle to create maps that are both semantically rich and easily interpretable. While incorporating semantic scene knowledge aids in building richer maps with contextual associations among mapped objects, representing them in structured formats like scene graphs has not been widely addressed, encountering complex map comprehension and limited scalability. This paper introduces visual S-Graphs (vS-Graphs), a novel real-time VSLAM framework that integrates vision-based scene understanding with map reconstruction and comprehensible graph-based representation. The framework infers structural elements (i.e., rooms and corridors) from detected building components (i.e., walls and ground surfaces) and incorporates them into optimizable 3D scene graphs. This solution enhances the reconstructed map's semantic richness, comprehensibility, and localization accuracy. Extensive experiments on standard benchmarks and real-world datasets demonstrate that vS-Graphs outperforms state-of-the-art VSLAM methods, reducing trajectory error by an average of 3.38% and up to 9.58% on real-world data. Furthermore, the proposed framework achieves environment-driven semantic entity detection accuracy comparable to precise LiDAR-based frameworks using only visual features. A web page containing more media and evaluation outcomes is available on https://snt-arg.github.io/vsgraphs-results/.
S-Graphs 2.0 -- A Hierarchical-Semantic Optimization and Loop Closure for SLAM
Feb 25, 2025Works based on localization and mapping do not exploit the inherent semantic-relational information from the environment for faster and efficient management and optimization of the robot poses and its map elements, often leading to pose and map inaccuracies and computational inefficiencies in large scale environments. 3D scene graph representations which distributes the environment in an hierarchical manner can be exploited to enhance the management/optimization of underlying robot poses and its map. In this direction, we present our work Situational Graphs 2.0, which leverages the hierarchical structure of indoor scenes for efficient data management and optimization. Our algorithm begins by constructing a situational graph that organizes the environment into four layers: Keyframes, Walls, Rooms, and Floors. Our first novelty lies in the front-end which includes a floor detection module capable of identifying stairways and assigning a floor-level semantic-relations to the underlying layers. This floor-level semantic enables a floor-based loop closure strategy, rejecting false-positive loop closures in visually similar areas on different floors. Our second novelty is in exploiting the hierarchy for an improved optimization. It consists of: (1) local optimization, optimizing a window of recent keyframes and their connected components, (2) floor-global optimization, which focuses only on keyframes and their connections within the current floor during loop closures, and (3) room-local optimization, marginalizing redundant keyframes that share observations within the room. We validate our algorithm extensively in different real multi-floor environments. Our approach can demonstrate state-of-art-art results in large scale multi-floor environments creating hierarchical maps while bounding the computational complexity where several baseline works fail to execute efficiently.
Motion Control in Multi-Rotor Aerial Robots Using Deep Reinforcement Learning
Feb 09, 2025This paper investigates the application of Deep Reinforcement (DRL) Learning to address motion control challenges in drones for additive manufacturing (AM). Drone-based additive manufacturing promises flexible and autonomous material deposition in large-scale or hazardous environments. However, achieving robust real-time control of a multi-rotor aerial robot under varying payloads and potential disturbances remains challenging. Traditional controllers like PID often require frequent parameter re-tuning, limiting their applicability in dynamic scenarios. We propose a DRL framework that learns adaptable control policies for multi-rotor drones performing waypoint navigation in AM tasks. We compare Deep Deterministic Policy Gradient (DDPG) and Twin Delayed Deep Deterministic Policy Gradient (TD3) within a curriculum learning scheme designed to handle increasing complexity. Our experiments show TD3 consistently balances training stability, accuracy, and success, particularly when mass variability is introduced. These findings provide a scalable path toward robust, autonomous drone control in additive manufacturing.
Unveiling the Potential of iMarkers: Invisible Fiducial Markers for Advanced Robotics
Jan 26, 2025Fiducial markers are widely used in various robotics tasks, facilitating enhanced navigation, object recognition, and scene understanding. Despite their advantages for robots and Augmented Reality (AR) applications, they often disrupt the visual aesthetics of environments because they are visible to humans, making them unsuitable for non-intrusive use cases. To address this gap, this paper presents "iMarkers"-innovative, unobtrusive fiducial markers detectable exclusively by robots equipped with specialized sensors. These markers offer high flexibility in production, allowing customization of their visibility range and encoding algorithms to suit various demands. The paper also introduces the hardware designs and software algorithms developed for detecting iMarkers, highlighting their adaptability and robustness in the detection and recognition stages. Various evaluations have demonstrated the effectiveness of iMarkers compared to conventional (printed) and blended fiducial markers and confirmed their applicability in diverse robotics scenarios.
Metric-Semantic Factor Graph Generation based on Graph Neural Networks
Sep 18, 2024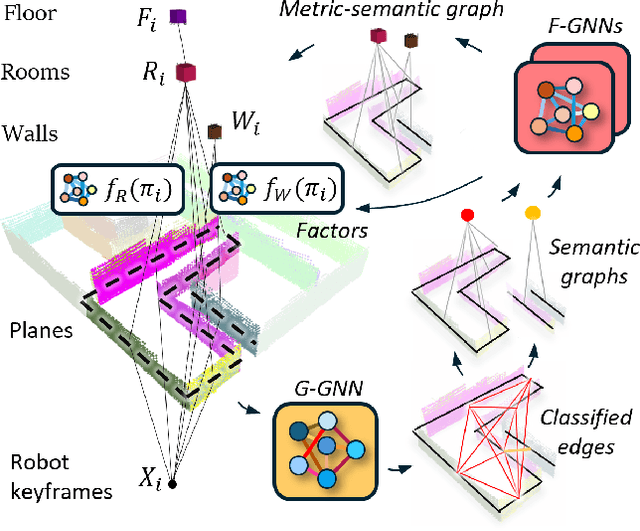
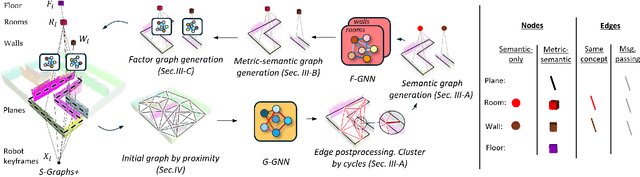
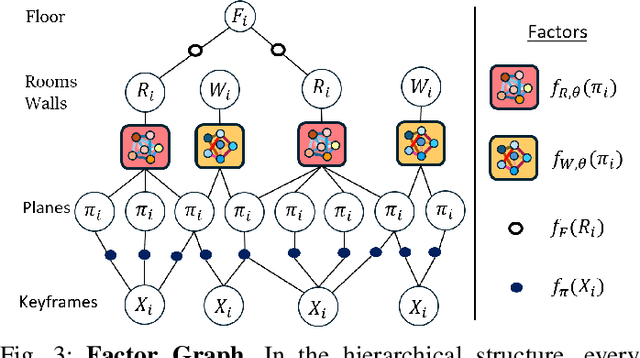
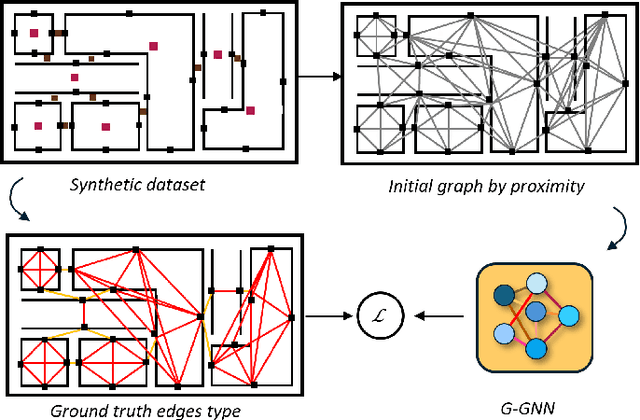
Understanding the relationships between geometric structures and semantic concepts is crucial for building accurate models of complex environments. In indoors, certain spatial constraints, such as the relative positioning of planes, remain consistent despite variations in layout. This paper explores how these invariant relationships can be captured in a graph SLAM framework by representing high-level concepts like rooms and walls, linking them to geometric elements like planes through an optimizable factor graph. Several efforts have tackled this issue with add-hoc solutions for each concept generation and with manually-defined factors. This paper proposes a novel method for metric-semantic factor graph generation which includes defining a semantic scene graph, integrating geometric information, and learning the interconnecting factors, all based on Graph Neural Networks (GNNs). An edge classification network (G-GNN) sorts the edges between planes into same room, same wall or none types. The resulting relations are clustered, generating a room or wall for each cluster. A second family of networks (F-GNN) infers the geometrical origin of the new nodes. The definition of the factors employs the same F-GNN used for the metric attribute of the generated nodes. Furthermore, share the new factor graph with the S-Graphs+ algorithm, extending its graph expressiveness and scene representation with the ultimate goal of improving the SLAM performance. The complexity of the environments is increased to N-plane rooms by training the networks on L-shaped rooms. The framework is evaluated in synthetic and simulated scenarios as no real datasets of the required complex layouts are available.
Towards Localizing Structural Elements: Merging Geometrical Detection with Semantic Verification in RGB-D Data
Sep 10, 2024



RGB-D cameras supply rich and dense visual and spatial information for various robotics tasks such as scene understanding, map reconstruction, and localization. Integrating depth and visual information can aid robots in localization and element mapping, advancing applications like 3D scene graph generation and Visual Simultaneous Localization and Mapping (VSLAM). While point cloud data containing such information is primarily used for enhanced scene understanding, exploiting their potential to capture and represent rich semantic information has yet to be adequately targeted. This paper presents a real-time pipeline for localizing building components, including wall and ground surfaces, by integrating geometric calculations for pure 3D plane detection followed by validating their semantic category using point cloud data from RGB-D cameras. It has a parallel multi-thread architecture to precisely estimate poses and equations of all the planes detected in the environment, filters the ones forming the map structure using a panoptic segmentation validation, and keeps only the validated building components. Incorporating the proposed method into a VSLAM framework confirmed that constraining the map with the detected environment-driven semantic elements can improve scene understanding and map reconstruction accuracy. It can also ensure (re-)association of these detected components into a unified 3D scene graph, bridging the gap between geometric accuracy and semantic understanding. Additionally, the pipeline allows for the detection of potential higher-level structural entities, such as rooms, by identifying the relationships between building components based on their layout.
Real-time Localization and Mapping in Architectural Plans with Deviations
Aug 03, 2024Having prior knowledge of an environment boosts the localization and mapping accuracy of robots. Several approaches in the literature have utilized architectural plans in this regard. However, almost all of them overlook the deviations between actual as-built environments and as-planned architectural designs, introducing bias in the estimations. To address this issue, we present a novel localization and mapping method denoted as deviations-informed Situational Graphs or diS-Graphs that integrates prior knowledge from architectural plans even in the presence of deviations. It is based on Situational Graphs (S-Graphs) that merge geometric models of the environment with 3D scene graphs into a multi-layered jointly optimizable factor graph. Our diS-Graph extracts information from architectural plans by first modeling them as a hierarchical factor graph, which we will call an Architectural Graph (A-Graph). While the robot explores the real environment, it estimates an S-Graph from its onboard sensors. We then use a novel matching algorithm to register the A-Graph and S-Graph in the same reference, and merge both of them with an explicit model of deviations. Finally, an alternating graph optimization strategy allows simultaneous global localization and mapping, as well as deviation estimation between both the A-Graph and the S-Graph. We perform several experiments in simulated and real datasets in the presence of deviations. On average, our diS-Graphs outperforms the baselines by a margin of approximately 43% in simulated environments and by 7% in real environments, while being able to estimate deviations up to 35 cm and 15 degrees.