 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePassage-Aware Structural Mapping for RGB-D Visual SLAM
Apr 27, 2026Doorways and passages are critical structural elements for indoor robot navigation, yet they remain underexplored in modern Visual SLAM (VSLAM) frameworks. This paper presents a passage-aware structural mapping approach for RGB-D VSLAM that detects doors and traversable openings by jointly fusing geometric, semantic, and topological cues. Doors are modeled as planar entities embedded within walls and classified as traversable or non-traversable based on their coplanarity with the supporting wall. Passages are inferred through two complementary strategies: traversal evidence accumulated from camera-wall interactions across consecutive keyframes, and geometric opening validation based on discontinuities in the mapped wall geometry. The proposed method is integrated into vS-Graphs as a proof of concept, enriching its scene graph with passage-level abstractions and improving room connectivity modeling. Qualitative evaluations on indoor office sequences demonstrate reliable doorway detection, and the framework lays the foundation for exploiting these elements in BIM-informed VSLAM. The source code is publicly available at https://github.com/snt-arg/visual_sgraphs/tree/doorway_integration.
Human Interaction for Collaborative Semantic SLAM using Extended Reality
Sep 18, 2025Semantic SLAM (Simultaneous Localization and Mapping) systems enrich robot maps with structural and semantic information, enabling robots to operate more effectively in complex environments. However, these systems struggle in real-world scenarios with occlusions, incomplete data, or ambiguous geometries, as they cannot fully leverage the higher-level spatial and semantic knowledge humans naturally apply. We introduce HICS-SLAM, a Human-in-the-Loop semantic SLAM framework that uses a shared extended reality environment for real-time collaboration. The system allows human operators to directly interact with and visualize the robot's 3D scene graph, and add high-level semantic concepts (e.g., rooms or structural entities) into the mapping process. We propose a graph-based semantic fusion methodology that integrates these human interventions with robot perception, enabling scalable collaboration for enhanced situational awareness. Experimental evaluations on real-world construction site datasets demonstrate improvements in room detection accuracy, map precision, and semantic completeness compared to automated baselines, demonstrating both the effectiveness of the approach and its potential for future extensions.
BIM Informed Visual SLAM for Construction Monitoring
Sep 17, 2025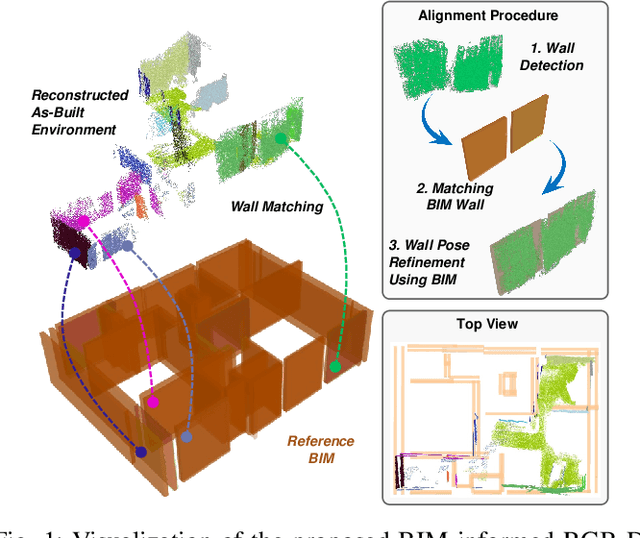

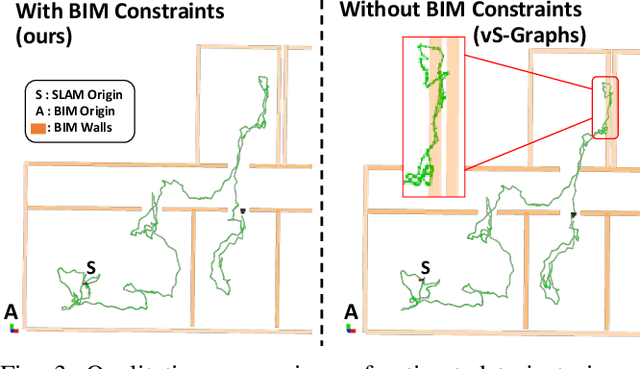

Simultaneous Localization and Mapping (SLAM) is a key tool for monitoring construction sites, where aligning the evolving as-built state with the as-planned design enables early error detection and reduces costly rework. LiDAR-based SLAM achieves high geometric precision, but its sensors are typically large and power-demanding, limiting their use on portable platforms. Visual SLAM offers a practical alternative with lightweight cameras already embedded in most mobile devices. however, visually mapping construction environments remains challenging: repetitive layouts, occlusions, and incomplete or low-texture structures often cause drift in the trajectory map. To mitigate this, we propose an RGB-D SLAM system that incorporates the Building Information Model (BIM) as structural prior knowledge. Instead of relying solely on visual cues, our system continuously establishes correspondences between detected wall and their BIM counterparts, which are then introduced as constraints in the back-end optimization. The proposed method operates in real time and has been validated on real construction sites, reducing trajectory error by an average of 23.71% and map RMSE by 7.14% compared to visual SLAM baselines. These results demonstrate that BIM constraints enable reliable alignment of the digital plan with the as-built scene, even under partially constructed conditions.
SMapper: A Multi-Modal Data Acquisition Platform for SLAM Benchmarking
Sep 11, 2025Advancing research in fields like Simultaneous Localization and Mapping (SLAM) and autonomous navigation critically depends on reliable and reproducible multimodal datasets. While several influential datasets have driven progress in these domains, they often suffer from limitations in sensing modalities, environmental diversity, and the reproducibility of the underlying hardware setups. To address these challenges, this paper introduces SMapper, a novel open-hardware, multi-sensor platform designed explicitly for, though not limited to, SLAM research. The device integrates synchronized LiDAR, multi-camera, and inertial sensing, supported by a robust calibration and synchronization pipeline that ensures precise spatio-temporal alignment across modalities. Its open and replicable design allows researchers to extend its capabilities and reproduce experiments across both handheld and robot-mounted scenarios. To demonstrate its practicality, we additionally release SMapper-light, a publicly available SLAM dataset containing representative indoor and outdoor sequences. The dataset includes tightly synchronized multimodal data and ground-truth trajectories derived from offline LiDAR-based SLAM with sub-centimeter accuracy, alongside dense 3D reconstructions. Furthermore, the paper contains benchmarking results on state-of-the-art LiDAR and visual SLAM frameworks using the SMapper-light dataset. By combining open-hardware design, reproducible data collection, and comprehensive benchmarking, SMapper establishes a robust foundation for advancing SLAM algorithm development, evaluation, and reproducibility.
Situationally-aware Path Planning Exploiting 3D Scene Graphs
Aug 08, 20253D Scene Graphs integrate both metric and semantic information, yet their structure remains underutilized for improving path planning efficiency and interpretability. In this work, we present S-Path, a situationally-aware path planner that leverages the metric-semantic structure of indoor 3D Scene Graphs to significantly enhance planning efficiency. S-Path follows a two-stage process: it first performs a search over a semantic graph derived from the scene graph to yield a human-understandable high-level path. This also identifies relevant regions for planning, which later allows the decomposition of the problem into smaller, independent subproblems that can be solved in parallel. We also introduce a replanning mechanism that, in the event of an infeasible path, reuses information from previously solved subproblems to update semantic heuristics and prioritize reuse to further improve the efficiency of future planning attempts. Extensive experiments on both real-world and simulated environments show that S-Path achieves average reductions of 5.7x in planning time while maintaining comparable path optimality to classical sampling-based planners and surpassing them in complex scenarios, making it an efficient and interpretable path planner for environments represented by indoor 3D Scene Graphs.
ViLLA-MMBench: A Unified Benchmark Suite for LLM-Augmented Multimodal Movie Recommendation
Aug 06, 2025Recommending long-form video content demands joint modeling of visual, audio, and textual modalities, yet most benchmarks address only raw features or narrow fusion. We present ViLLA-MMBench, a reproducible, extensible benchmark for LLM-augmented multimodal movie recommendation. Built on MovieLens and MMTF-14K, it aligns dense item embeddings from three modalities: audio (block-level, i-vector), visual (CNN, AVF), and text. Missing or sparse metadata is automatically enriched using state-of-the-art LLMs (e.g., OpenAI Ada), generating high-quality synopses for thousands of movies. All text (raw or augmented) is embedded with configurable encoders (Ada, LLaMA-2, Sentence-T5), producing multiple ready-to-use sets. The pipeline supports interchangeable early-, mid-, and late-fusion (concatenation, PCA, CCA, rank-aggregation) and multiple backbones (MF, VAECF, VBPR, AMR, VMF) for ablation. Experiments are fully declarative via a single YAML file. Evaluation spans accuracy (Recall, nDCG) and beyond-accuracy metrics: cold-start rate, coverage, novelty, diversity, fairness. Results show LLM-based augmentation and strong text embeddings boost cold-start and coverage, especially when fused with audio-visual features. Systematic benchmarking reveals universal versus backbone- or metric-specific combinations. Open-source code, embeddings, and configs enable reproducible, fair multimodal RS research and advance principled generative AI integration in large-scale recommendation. Code: https://recsys-lab.github.io/ViLLA-MMBench
RAG-VisualRec: An Open Resource for Vision- and Text-Enhanced Retrieval-Augmented Generation in Recommendation
Jun 25, 2025This paper addresses the challenge of developing multimodal recommender systems for the movie domain, where limited metadata (e.g., title, genre) often hinders the generation of robust recommendations. We introduce a resource that combines LLM-generated plot descriptions with trailer-derived visual embeddings in a unified pipeline supporting both Retrieval-Augmented Generation (RAG) and collaborative filtering. Central to our approach is a data augmentation step that transforms sparse metadata into richer textual signals, alongside fusion strategies (e.g., PCA, CCA) that integrate visual cues. Experimental evaluations demonstrate that CCA-based fusion significantly boosts recall compared to unimodal baselines, while an LLM-driven re-ranking step further improves NDCG, particularly in scenarios with limited textual data. By releasing this framework, we invite further exploration of multi-modal recommendation techniques tailored to cold-start, novelty-focused, and domain-specific settings. All code, data, and detailed documentation are publicly available at: https://github.com/RecSys-lab/RAG-VisualRec
vS-Graphs: Integrating Visual SLAM and Situational Graphs through Multi-level Scene Understanding
Mar 03, 2025Current Visual Simultaneous Localization and Mapping (VSLAM) systems often struggle to create maps that are both semantically rich and easily interpretable. While incorporating semantic scene knowledge aids in building richer maps with contextual associations among mapped objects, representing them in structured formats like scene graphs has not been widely addressed, encountering complex map comprehension and limited scalability. This paper introduces visual S-Graphs (vS-Graphs), a novel real-time VSLAM framework that integrates vision-based scene understanding with map reconstruction and comprehensible graph-based representation. The framework infers structural elements (i.e., rooms and corridors) from detected building components (i.e., walls and ground surfaces) and incorporates them into optimizable 3D scene graphs. This solution enhances the reconstructed map's semantic richness, comprehensibility, and localization accuracy. Extensive experiments on standard benchmarks and real-world datasets demonstrate that vS-Graphs outperforms state-of-the-art VSLAM methods, reducing trajectory error by an average of 3.38% and up to 9.58% on real-world data. Furthermore, the proposed framework achieves environment-driven semantic entity detection accuracy comparable to precise LiDAR-based frameworks using only visual features. A web page containing more media and evaluation outcomes is available on https://snt-arg.github.io/vsgraphs-results/.
Unveiling the Potential of iMarkers: Invisible Fiducial Markers for Advanced Robotics
Jan 26, 2025



Fiducial markers are widely used in various robotics tasks, facilitating enhanced navigation, object recognition, and scene understanding. Despite their advantages for robots and Augmented Reality (AR) applications, they often disrupt the visual aesthetics of environments because they are visible to humans, making them unsuitable for non-intrusive use cases. To address this gap, this paper presents "iMarkers"-innovative, unobtrusive fiducial markers detectable exclusively by robots equipped with specialized sensors. These markers offer high flexibility in production, allowing customization of their visibility range and encoding algorithms to suit various demands. The paper also introduces the hardware designs and software algorithms developed for detecting iMarkers, highlighting their adaptability and robustness in the detection and recognition stages. Various evaluations have demonstrated the effectiveness of iMarkers compared to conventional (printed) and blended fiducial markers and confirmed their applicability in diverse robotics scenarios.
Towards Localizing Structural Elements: Merging Geometrical Detection with Semantic Verification in RGB-D Data
Sep 10, 2024



RGB-D cameras supply rich and dense visual and spatial information for various robotics tasks such as scene understanding, map reconstruction, and localization. Integrating depth and visual information can aid robots in localization and element mapping, advancing applications like 3D scene graph generation and Visual Simultaneous Localization and Mapping (VSLAM). While point cloud data containing such information is primarily used for enhanced scene understanding, exploiting their potential to capture and represent rich semantic information has yet to be adequately targeted. This paper presents a real-time pipeline for localizing building components, including wall and ground surfaces, by integrating geometric calculations for pure 3D plane detection followed by validating their semantic category using point cloud data from RGB-D cameras. It has a parallel multi-thread architecture to precisely estimate poses and equations of all the planes detected in the environment, filters the ones forming the map structure using a panoptic segmentation validation, and keeps only the validated building components. Incorporating the proposed method into a VSLAM framework confirmed that constraining the map with the detected environment-driven semantic elements can improve scene understanding and map reconstruction accuracy. It can also ensure (re-)association of these detected components into a unified 3D scene graph, bridging the gap between geometric accuracy and semantic understanding. Additionally, the pipeline allows for the detection of potential higher-level structural entities, such as rooms, by identifying the relationships between building components based on their layout.