 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-5 vs Other LLMs in Long Short-Context Performance
Feb 15, 2026With the significant expansion of the context window in Large Language Models (LLMs), these models are theoretically capable of processing millions of tokens in a single pass. However, research indicates a significant gap between this theoretical capacity and the practical ability of models to robustly utilize information within long contexts, especially in tasks that require a comprehensive understanding of numerous details. This paper evaluates the performance of four state-of-the-art models (Grok-4, GPT-4, Gemini 2.5, and GPT-5) on long short-context tasks. For this purpose, three datasets were used: two supplementary datasets for retrieving culinary recipes and math problems, and a primary dataset of 20K social media posts for depression detection. The results show that as the input volume on the social media dataset exceeds 5K posts (70K tokens), the performance of all models degrades significantly, with accuracy dropping to around 50-53% for 20K posts. Notably, in the GPT-5 model, despite the sharp decline in accuracy, its precision remained high at approximately 95%, a feature that could be highly effective for sensitive applications like depression detection. This research also indicates that the "lost in the middle" problem has been largely resolved in newer models. This study emphasizes the gap between the theoretical capacity and the actual performance of models on complex, high-volume data tasks and highlights the importance of metrics beyond simple accuracy for practical applications.
Pedestrian Detection in Low-Light Conditions: A Comprehensive Survey
Jan 15, 2024Pedestrian detection remains a critical problem in various domains, such as computer vision, surveillance, and autonomous driving. In particular, accurate and instant detection of pedestrians in low-light conditions and reduced visibility is of utmost importance for autonomous vehicles to prevent accidents and save lives. This paper aims to comprehensively survey various pedestrian detection approaches, baselines, and datasets that specifically target low-light conditions. The survey discusses the challenges faced in detecting pedestrians at night and explores state-of-the-art methodologies proposed in recent years to address this issue. These methodologies encompass a diverse range, including deep learning-based, feature-based, and hybrid approaches, which have shown promising results in enhancing pedestrian detection performance under challenging lighting conditions. Furthermore, the paper highlights current research directions in the field and identifies potential solutions that merit further investigation by researchers. By thoroughly examining pedestrian detection techniques in low-light conditions, this survey seeks to contribute to the advancement of safer and more reliable autonomous driving systems and other applications related to pedestrian safety. Accordingly, most of the current approaches in the field use deep learning-based image fusion methodologies (i.e., early, halfway, and late fusion) for accurate and reliable pedestrian detection. Moreover, the majority of the works in the field (approximately 48%) have been evaluated on the KAIST dataset, while the real-world video feeds recorded by authors have been used in less than six percent of the works.
A Robust Pedestrian Detection Approach for Autonomous Vehicles
Oct 19, 2022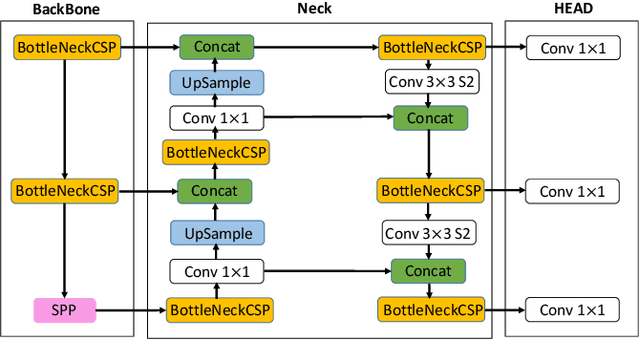

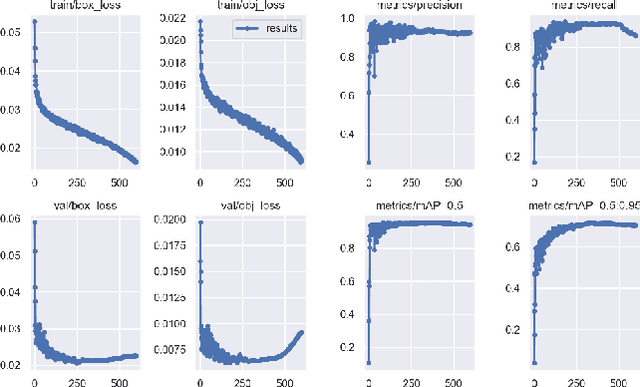
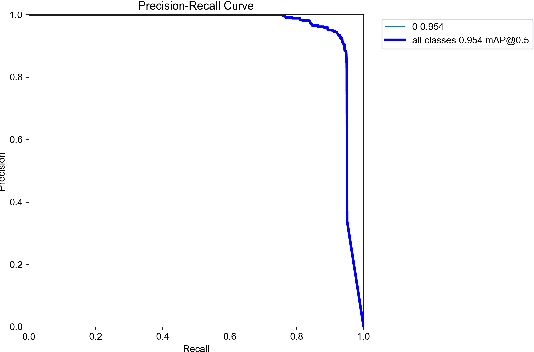
Nowadays, utilizing Advanced Driver-Assistance Systems (ADAS) has absorbed a huge interest as a potential solution for reducing road traffic issues. Despite recent technological advances in such systems, there are still many inquiries that need to be overcome. For instance, ADAS requires accurate and real-time detection of pedestrians in various driving scenarios. To solve the mentioned problem, this paper aims to fine-tune the YOLOv5s framework for handling pedestrian detection challenges on the real-world instances of Caltech pedestrian dataset. We also introduce a developed toolbox for preparing training and test data and annotations of Caltech pedestrian dataset into the format recognizable by YOLOv5. Experimental results of utilizing our approach show that the mean Average Precision (mAP) of our fine-tuned model for pedestrian detection task is more than 91 percent when performing at the highest rate of 70 FPS. Moreover, the experiments on the Caltech pedestrian dataset samples have verified that our proposed approach is an effective and accurate method for pedestrian detection and can outperform other existing methodologies.
Iranis: A Large-scale Dataset of Farsi License Plate Characters
Jan 01, 2021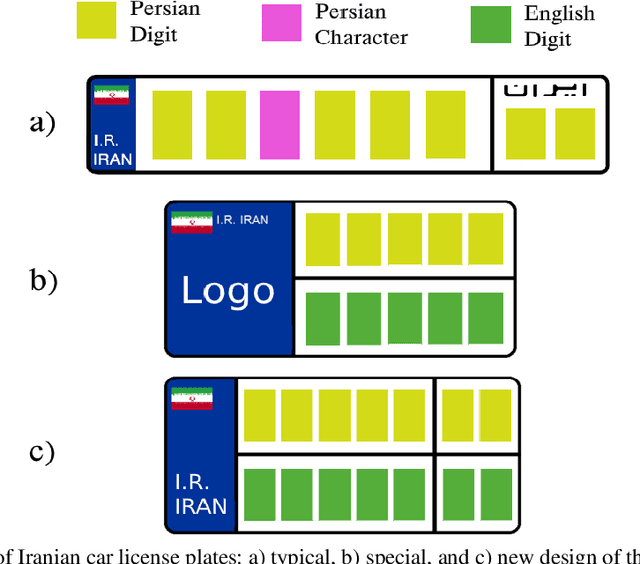

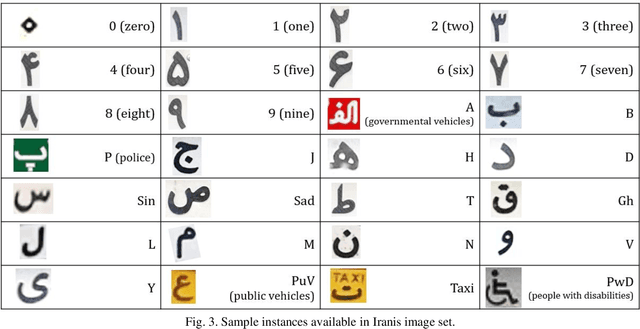

Providing huge amounts of data is a fundamental demand when dealing with Deep Neural Networks (DNNs). Employing these algorithms to solve computer vision problems resulted in the advent of various image datasets to feed the most common visual imagery deep structures, known as Convolutional Neural Networks (CNNs). In this regard, some datasets can be found that contain hundreds or even thousands of images for license plate detection and optical character recognition purposes. However, no publicly available image dataset provides such data for the recognition of Farsi characters used in car license plates. The gap has to be filled due to the numerous advantages of developing accurate deep learning-based systems for law enforcement and surveillance purposes. This paper introduces a large-scale dataset that includes images of numbers and characters used in Iranian car license plates. The dataset, named Iranis, contains more than 83,000 images of Farsi numbers and letters collected from real-world license plate images captured by various cameras. The variety of instances in terms of camera shooting angle, illumination, resolution, and contrast make the dataset a proper choice for training DNNs. Dataset images are manually annotated for object detection and image classification. Finally, and to build a baseline for Farsi character recognition, the paper provides a performance analysis using a YOLO v.3 object detector.