 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Correcting Large Language Models: Generation vs. Multiple Choice
Nov 12, 2025Large language models have recently demonstrated remarkable abilities to self-correct their responses through iterative refinement, often referred to as self-consistency or self-reflection. However, the dynamics of this self-correction mechanism may differ substantially depending on whether the model is tasked with open-ended text generation or with selecting the most appropriate response from multiple predefined options. In this paper, we conduct a systematic investigation of these two paradigms by comparing performance trends and error-correction behaviors across various natural language understanding and reasoning tasks, covering language models of different scales and families. Our experimental results reveal distinct patterns of improvement and failure modes: \textit{While open-ended generation often benefits from the flexibility of re-interpretation and compositional refinement, multiple-choice selection can leverage clearer solution boundaries but may be limited by the provided options}. This contrast also reflects the dual demands faced by emerging agentic LLM applications: effective agents must not only generate and refine open-ended plans or explanations, but also make reliable discrete choices when operating within constrained action spaces. Our findings, therefore, highlight that the design of self-correction mechanisms should take into account the interaction between task structure and output space, with implications for both knowledge-intensive reasoning and decision-oriented applications of LLMs.
Clarifying the Path to User Satisfaction: An Investigation into Clarification Usefulness
Feb 02, 2024



Clarifying questions are an integral component of modern information retrieval systems, directly impacting user satisfaction and overall system performance. Poorly formulated questions can lead to user frustration and confusion, negatively affecting the system's performance. This research addresses the urgent need to identify and leverage key features that contribute to the classification of clarifying questions, enhancing user satisfaction. To gain deeper insights into how different features influence user satisfaction, we conduct a comprehensive analysis, considering a broad spectrum of lexical, semantic, and statistical features, such as question length and sentiment polarity. Our empirical results provide three main insights into the qualities of effective query clarification: (1) specific questions are more effective than generic ones; (2) the subjectivity and emotional tone of a question play a role; and (3) shorter and more ambiguous queries benefit significantly from clarification. Based on these insights, we implement feature-integrated user satisfaction prediction using various classifiers, both traditional and neural-based, including random forest, BERT, and large language models. Our experiments show a consistent and significant improvement, particularly in traditional classifiers, with a minimum performance boost of 45\%. This study presents invaluable guidelines for refining the formulation of clarifying questions and enhancing both user satisfaction and system performance.
A Personalized Framework for Consumer and Producer Group Fairness Optimization in Recommender Systems
Feb 01, 2024In recent years, there has been an increasing recognition that when machine learning (ML) algorithms are used to automate decisions, they may mistreat individuals or groups, with legal, ethical, or economic implications. Recommender systems are prominent examples of these machine learning (ML) systems that aid users in making decisions. The majority of past literature research on RS fairness treats user and item fairness concerns independently, ignoring the fact that recommender systems function in a two-sided marketplace. In this paper, we propose CP-FairRank, an optimization-based re-ranking algorithm that seamlessly integrates fairness constraints from both the consumer and producer side in a joint objective framework. The framework is generalizable and may take into account varied fairness settings based on group segmentation, recommendation model selection, and domain, which is one of its key characteristics. For instance, we demonstrate that the system may jointly increase consumer and producer fairness when (un)protected consumer groups are defined on the basis of their activity level and main-streamness, while producer groups are defined according to their popularity level. For empirical validation, through large-scale on eight datasets and four mainstream collaborative filtering (CF) recommendation models, we demonstrate that our proposed strategy is able to improve both consumer and producer fairness without compromising or very little overall recommendation quality, demonstrating the role algorithms may play in avoiding data biases.
Provider Fairness and Beyond-Accuracy Trade-offs in Recommender Systems
Sep 08, 2023
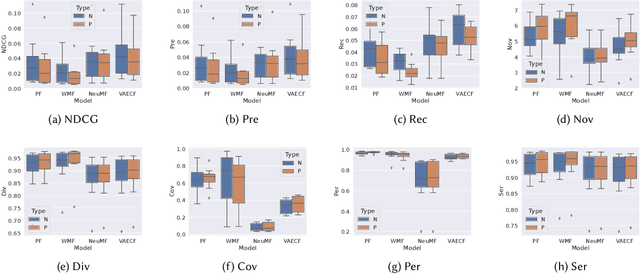
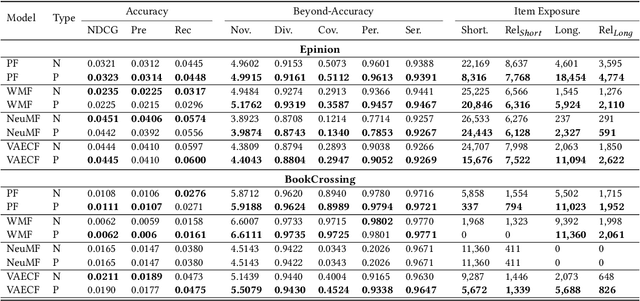
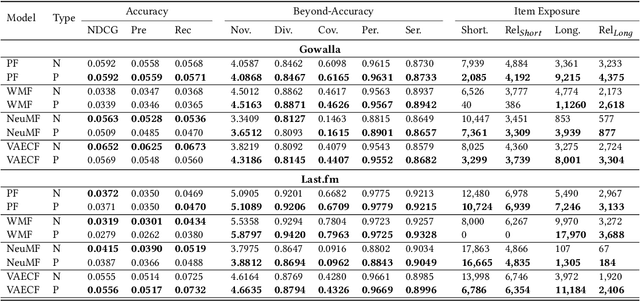
Recommender systems, while transformative in online user experiences, have raised concerns over potential provider-side fairness issues. These systems may inadvertently favor popular items, thereby marginalizing less popular ones and compromising provider fairness. While previous research has recognized provider-side fairness issues, the investigation into how these biases affect beyond-accuracy aspects of recommendation systems - such as diversity, novelty, coverage, and serendipity - has been less emphasized. In this paper, we address this gap by introducing a simple yet effective post-processing re-ranking model that prioritizes provider fairness, while simultaneously maintaining user relevance and recommendation quality. We then conduct an in-depth evaluation of the model's impact on various aspects of recommendation quality across multiple datasets. Specifically, we apply the post-processing algorithm to four distinct recommendation models across four varied domain datasets, assessing the improvement in each metric, encompassing both accuracy and beyond-accuracy aspects. This comprehensive analysis allows us to gauge the effectiveness of our approach in mitigating provider biases. Our findings underscore the effectiveness of the adopted method in improving provider fairness and recommendation quality. They also provide valuable insights into the trade-offs involved in achieving fairness in recommender systems, contributing to a more nuanced understanding of this complex issue.
CAPRI: Context-Aware Interpretable Point-of-Interest Recommendation Framework
Jun 20, 2023Point-of-Interest (POI ) recommendation systems have gained popularity for their unique ability to suggest geographical destinations with the incorporation of contextual information such as time, location, and user-item interaction. Existing recommendation frameworks lack the contextual fusion required for POI systems. This paper presents CAPRI, a novel POI recommendation framework that effectively integrates context-aware models, such as GeoSoCa, LORE, and USG, and introduces a novel strategy for the efficient merging of contextual information. CAPRI integrates an evaluation module that expands the evaluation scope beyond accuracy to include novelty, personalization, diversity, and fairness. With an aim to establish a new industry standard for reproducible results in the realm of POI recommendation systems, we have made CAPRI openly accessible on GitHub, facilitating easy access and contribution to the continued development and refinement of this innovative framework.
Towards Confidence-aware Calibrated Recommendation
Aug 22, 2022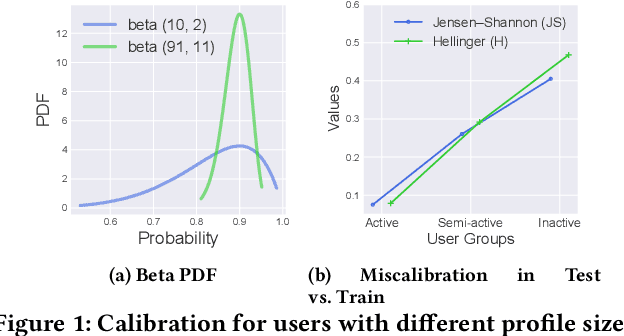
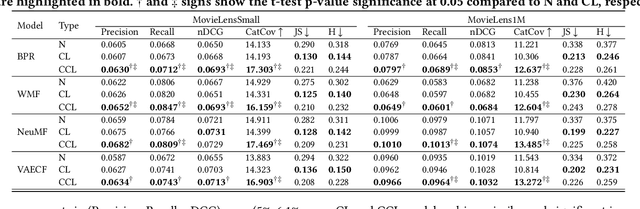
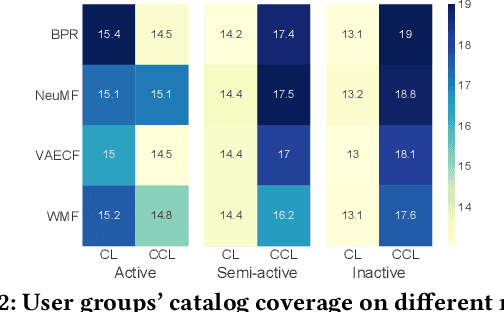
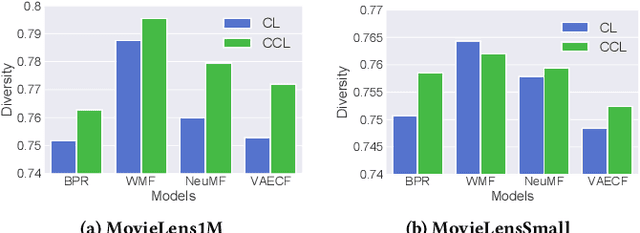
Recommender systems utilize users' historical data to learn and predict their future interests, providing them with suggestions tailored to their tastes. Calibration ensures that the distribution of recommended item categories is consistent with the user's historical data. Mitigating miscalibration brings various benefits to a recommender system. For example, it becomes less likely that a system overlooks categories with less interaction on a user's profile by only recommending popular categories. Despite the notable success, calibration methods have several drawbacks, such as limiting the diversity of the recommended items and not considering the calibration confidence. This work, presents a set of properties that address various aspects of a desired calibrated recommender system. Considering these properties, we propose a confidence-aware optimization-based re-ranking algorithm to find the balance between calibration, relevance, and item diversity, while simultaneously accounting for calibration confidence based on user profile size. Our model outperforms state-of-the-art methods in terms of various accuracy and beyond-accuracy metrics for different user groups.
Exploring the Impact of Temporal Bias in Point-of-Interest Recommendation
Jul 23, 2022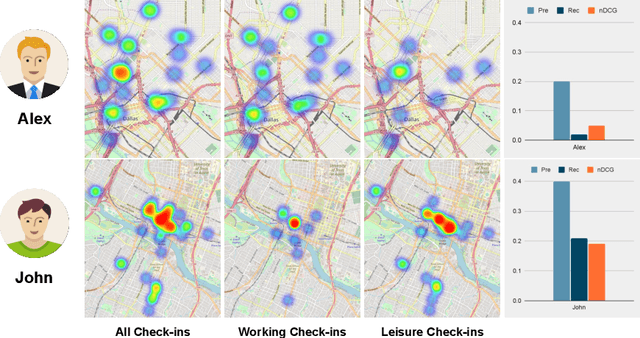


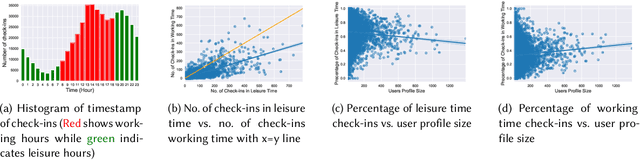
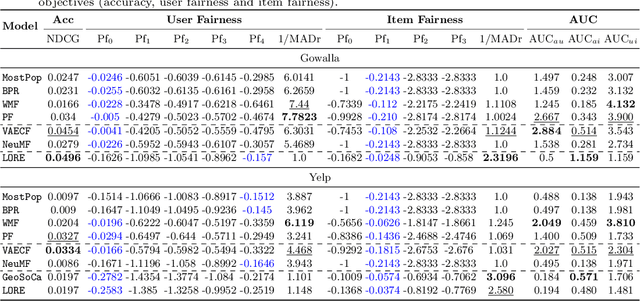
Recommending appropriate travel destinations to consumers based on contextual information such as their check-in time and location is a primary objective of Point-of-Interest (POI) recommender systems. However, the issue of contextual bias (i.e., how much consumers prefer one situation over another) has received little attention from the research community. This paper examines the effect of temporal bias, defined as the difference between users' check-in hours, leisure vs.~work hours, on the consumer-side fairness of context-aware recommendation algorithms. We believe that eliminating this type of temporal (and geographical) bias might contribute to a drop in traffic-related air pollution, noting that rush-hour traffic may be more congested. To surface effective POI recommendations, we evaluated the sensitivity of state-of-the-art context-aware models to the temporal bias contained in users' check-in activities on two POI datasets, namely Gowalla and Yelp. The findings show that the examined context-aware recommendation models prefer one group of users over another based on the time of check-in and that this preference persists even when users have the same amount of interactions.
Experiments on Generalizability of User-Oriented Fairness in Recommender Systems
May 17, 2022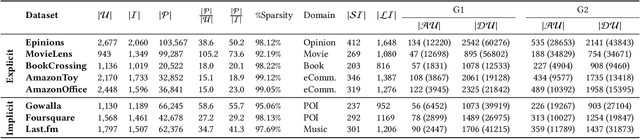
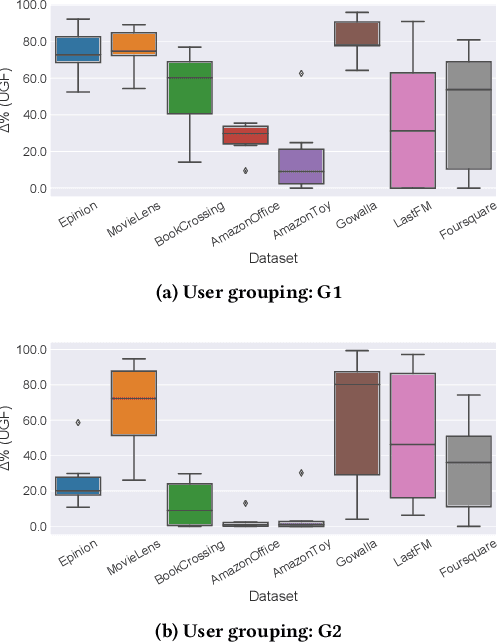
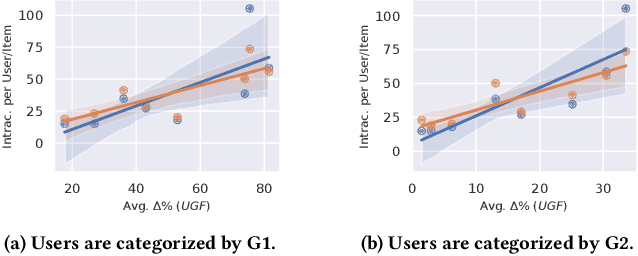
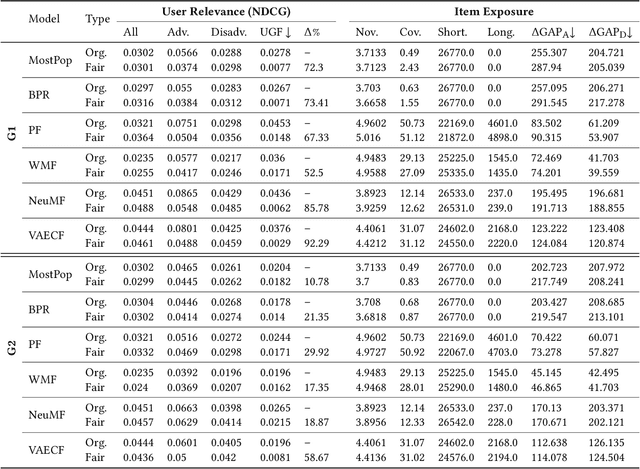
Recent work in recommender systems mainly focuses on fairness in recommendations as an important aspect of measuring recommendations quality. A fairness-aware recommender system aims to treat different user groups similarly. Relevant work on user-oriented fairness highlights the discriminative behavior of fairness-unaware recommendation algorithms towards a certain user group, defined based on users' activity level. Typical solutions include proposing a user-centered fairness re-ranking framework applied on top of a base ranking model to mitigate its unfair behavior towards a certain user group i.e., disadvantaged group. In this paper, we re-produce a user-oriented fairness study and provide extensive experiments to analyze the dependency of their proposed method on various fairness and recommendation aspects, including the recommendation domain, nature of the base ranking model, and user grouping method. Moreover, we evaluate the final recommendations provided by the re-ranking framework from both user- (e.g., NDCG, user-fairness) and item-side (e.g., novelty, item-fairness) metrics. We discover interesting trends and trade-offs between the model's performance in terms of different evaluation metrics. For instance, we see that the definition of the advantaged/disadvantaged user groups plays a crucial role in the effectiveness of the fairness algorithm and how it improves the performance of specific base ranking models. Finally, we highlight some important open challenges and future directions in this field. We release the data, evaluation pipeline, and the trained models publicly on https://github.com/rahmanidashti/FairRecSys.
CPFair: Personalized Consumer and Producer Fairness Re-ranking for Recommender Systems
Apr 17, 2022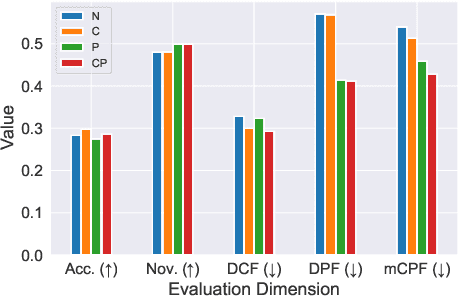

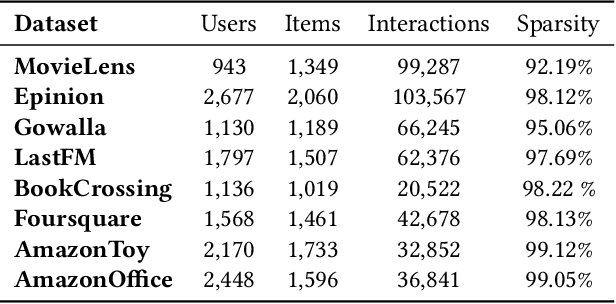
Recently, there has been a rising awareness that when machine learning (ML) algorithms are used to automate choices, they may treat/affect individuals unfairly, with legal, ethical, or economic consequences. Recommender systems are prominent examples of such ML systems that assist users in making high-stakes judgments. A common trend in the previous literature research on fairness in recommender systems is that the majority of works treat user and item fairness concerns separately, ignoring the fact that recommender systems operate in a two-sided marketplace. In this work, we present an optimization-based re-ranking approach that seamlessly integrates fairness constraints from both the consumer and producer-side in a joint objective framework. We demonstrate through large-scale experiments on 8 datasets that our proposed method is capable of improving both consumer and producer fairness without reducing overall recommendation quality, demonstrating the role algorithms may play in minimizing data biases.
The Unfairness of Active Users and Popularity Bias in Point-of-Interest Recommendation
Apr 08, 2022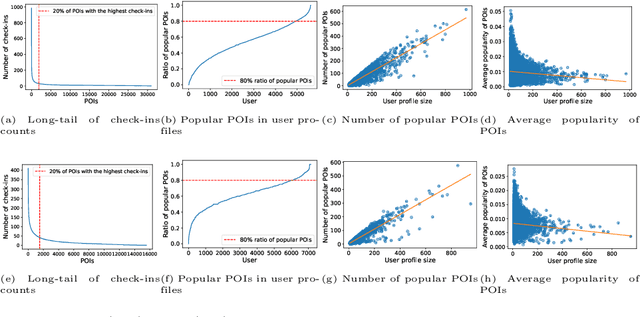
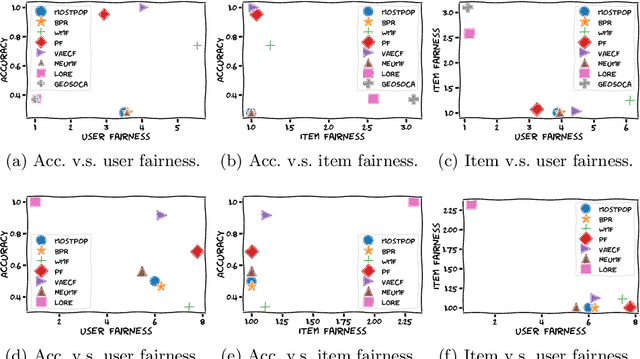
Point-of-Interest (POI) recommender systems provide personalized recommendations to users and help businesses attract potential customers. Despite their success, recent studies suggest that highly data-driven recommendations could be impacted by data biases, resulting in unfair outcomes for different stakeholders, mainly consumers (users) and providers (items). Most existing fairness-related research works in recommender systems treat user fairness and item fairness issues individually, disregarding that RS work in a two-sided marketplace. This paper studies the interplay between (i) the unfairness of active users, (ii) the unfairness of popular items, and (iii) the accuracy (personalization) of recommendation as three angles of our study triangle. We group users into advantaged and disadvantaged levels to measure user fairness based on their activity level. For item fairness, we divide items into short-head, mid-tail, and long-tail groups and study the exposure of these item groups into the top-k recommendation list of users. Experimental validation of eight different recommendation models commonly used for POI recommendation (e.g., contextual, CF) on two publicly available POI recommendation datasets, Gowalla and Yelp, indicate that most well-performing models suffer seriously from the unfairness of popularity bias (provider unfairness). Furthermore, our study shows that most recommendation models cannot satisfy both consumer and producer fairness, indicating a trade-off between these variables possibly due to natural biases in data. We choose the POI recommendation as our test scenario; however, the insights should be trivially extendable on other domains.