 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealism in Action: Anomaly-Aware Diagnosis of Brain Tumors from Medical Images Using YOLOv8 and DeiT
Jan 10, 2024In the field of medical sciences, reliable detection and classification of brain tumors from images remains a formidable challenge due to the rarity of tumors within the population of patients. Therefore, the ability to detect tumors in anomaly scenarios is paramount for ensuring timely interventions and improved patient outcomes. This study addresses the issue by leveraging deep learning (DL) techniques to detect and classify brain tumors in challenging situations. The curated data set from the National Brain Mapping Lab (NBML) comprises 81 patients, including 30 Tumor cases and 51 Normal cases. The detection and classification pipelines are separated into two consecutive tasks. The detection phase involved comprehensive data analysis and pre-processing to modify the number of image samples and the number of patients of each class to anomaly distribution (9 Normal per 1 Tumor) to comply with real world scenarios. Next, in addition to common evaluation metrics for the testing, we employed a novel performance evaluation method called Patient to Patient (PTP), focusing on the realistic evaluation of the model. In the detection phase, we fine-tuned a YOLOv8n detection model to detect the tumor region. Subsequent testing and evaluation yielded competitive performance both in Common Evaluation Metrics and PTP metrics. Furthermore, using the Data Efficient Image Transformer (DeiT) module, we distilled a Vision Transformer (ViT) model from a fine-tuned ResNet152 as a teacher in the classification phase. This approach demonstrates promising strides in reliable tumor detection and classification, offering potential advancements in tumor diagnosis for real-world medical imaging scenarios.
Provider Fairness and Beyond-Accuracy Trade-offs in Recommender Systems
Sep 08, 2023
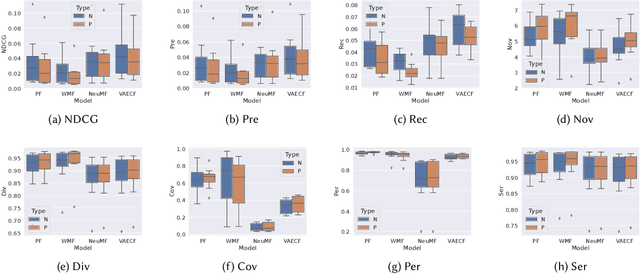
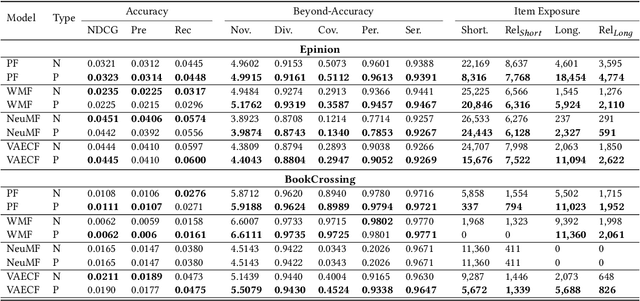
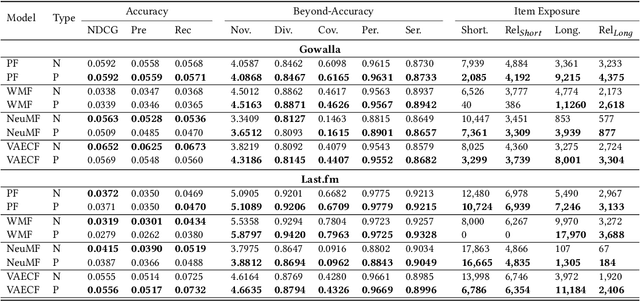
Recommender systems, while transformative in online user experiences, have raised concerns over potential provider-side fairness issues. These systems may inadvertently favor popular items, thereby marginalizing less popular ones and compromising provider fairness. While previous research has recognized provider-side fairness issues, the investigation into how these biases affect beyond-accuracy aspects of recommendation systems - such as diversity, novelty, coverage, and serendipity - has been less emphasized. In this paper, we address this gap by introducing a simple yet effective post-processing re-ranking model that prioritizes provider fairness, while simultaneously maintaining user relevance and recommendation quality. We then conduct an in-depth evaluation of the model's impact on various aspects of recommendation quality across multiple datasets. Specifically, we apply the post-processing algorithm to four distinct recommendation models across four varied domain datasets, assessing the improvement in each metric, encompassing both accuracy and beyond-accuracy aspects. This comprehensive analysis allows us to gauge the effectiveness of our approach in mitigating provider biases. Our findings underscore the effectiveness of the adopted method in improving provider fairness and recommendation quality. They also provide valuable insights into the trade-offs involved in achieving fairness in recommender systems, contributing to a more nuanced understanding of this complex issue.
SLCNN: Sentence-Level Convolutional Neural Network for Text Classification
Jan 27, 2023Text classification is a fundamental task in natural language processing (NLP). Several recent studies show the success of deep learning on text processing. Convolutional neural network (CNN), as a popular deep learning model, has shown remarkable success in the task of text classification. In this paper, new baseline models have been studied for text classification using CNN. In these models, documents are fed to the network as a three-dimensional tensor representation to provide sentence-level analysis. Applying such a method enables the models to take advantage of the positional information of the sentences in the text. Besides, analysing adjacent sentences allows extracting additional features. The proposed models have been compared with the state-of-the-art models using several datasets. The results have shown that the proposed models have better performance, particularly in the longer documents.
FR-Detect: A Multi-Modal Framework for Early Fake News Detection on Social Media Using Publishers Features
Sep 10, 2021



In recent years, with the expansion of the Internet and attractive social media infrastructures, people prefer to follow the news through these media. Despite the many advantages of these media in the news field, the lack of any control and verification mechanism has led to the spread of fake news, as one of the most important threats to democracy, economy, journalism and freedom of expression. Designing and using automatic methods to detect fake news on social media has become a significant challenge. In this paper, we examine the publishers' role in detecting fake news on social media. We also suggest a high accurate multi-modal framework, namely FR-Detect, using user-related and content-related features with early detection capability. For this purpose, two new user-related features, namely Activity Credibility and Influence, have been introduced for publishers. Furthermore, a sentence-level convolutional neural network is provided to combine these features with latent textual content features properly. Experimental results have shown that the publishers' features can improve the performance of content-based models by up to 13% and 29% in accuracy and F1-score, respectively.
TI-Capsule: Capsule Network for Stock Exchange Prediction
Feb 15, 2021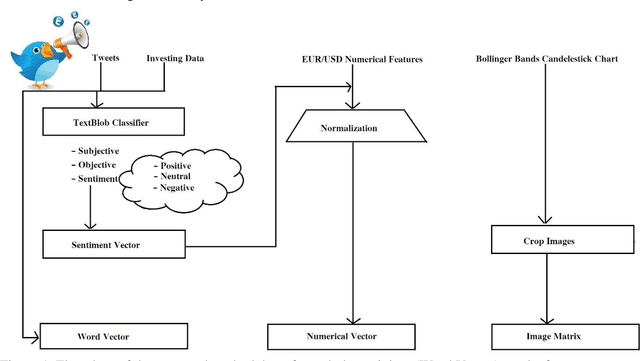
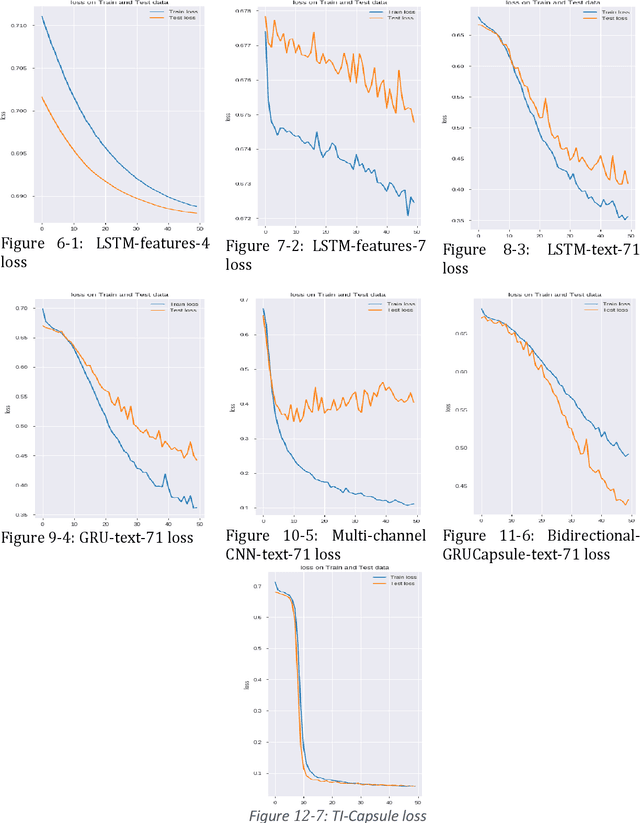

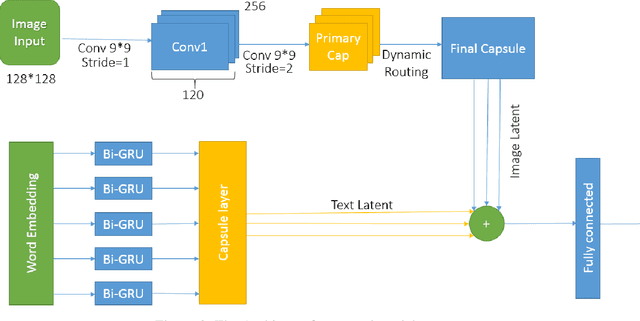
Today, the use of social networking data has attracted a lot of academic and commercial attention in predicting the stock market. In most studies in this area, the sentiment analysis of the content of user posts on social networks is used to predict market fluctuations. Predicting stock marketing is challenging because of the variables involved. In the short run, the market behaves like a voting machine, but in the long run, it acts like a weighing machine. The purpose of this study is to predict EUR/USD stock behavior using Capsule Network on finance texts and Candlestick images. One of the most important features of Capsule Network is the maintenance of features in a vector, which also takes into account the space between features. The proposed model, TI-Capsule (Text and Image information based Capsule Neural Network), is trained with both the text and image information simultaneously. Extensive experiments carried on the collected dataset have demonstrated the effectiveness of TI-Capsule in solving the stock exchange prediction problem with 91% accuracy.
A Study of Recent Contributions on Information Extraction
Mar 15, 2018
This paper reports on modern approaches in Information Extraction (IE) and its two main sub-tasks of Named Entity Recognition (NER) and Relation Extraction (RE). Basic concepts and the most recent approaches in this area are reviewed, which mainly include Machine Learning (ML) based approaches and the more recent trend to Deep Learning (DL) based methods.