 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Vision and Location with Transformers: A Multimodal Deep Learning Framework for Medical Wound Analysis
Apr 14, 2025Effective recognition of acute and difficult-to-heal wounds is a necessary step in wound diagnosis. An efficient classification model can help wound specialists classify wound types with less financial and time costs and also help in deciding on the optimal treatment method. Traditional machine learning models suffer from feature selection and are usually cumbersome models for accurate recognition. Recently, deep learning (DL) has emerged as a powerful tool in wound diagnosis. Although DL seems promising for wound type recognition, there is still a large scope for improving the efficiency and accuracy of the model. In this study, a DL-based multimodal classifier was developed using wound images and their corresponding locations to classify them into multiple classes, including diabetic, pressure, surgical, and venous ulcers. A body map was also created to provide location data, which can help wound specialists label wound locations more effectively. The model uses a Vision Transformer to extract hierarchical features from input images, a Discrete Wavelet Transform (DWT) layer to capture low and high frequency components, and a Transformer to extract spatial features. The number of neurons and weight vector optimization were performed using three swarm-based optimization techniques (Monster Gorilla Toner (MGTO), Improved Gray Wolf Optimization (IGWO), and Fox Optimization Algorithm). The evaluation results show that weight vector optimization using optimization algorithms can increase diagnostic accuracy and make it a very effective approach for wound detection. In the classification using the original body map, the proposed model was able to achieve an accuracy of 0.8123 using image data and an accuracy of 0.8007 using a combination of image data and wound location. Also, the accuracy of the model in combination with the optimization models varied from 0.7801 to 0.8342.
UNet++ and LSTM combined approach for Breast Ultrasound Image Segmentation
Dec 07, 2024



Breast cancer stands as a prevalent cause of fatality among females on a global scale, with prompt detection playing a pivotal role in diminishing mortality rates. The utilization of ultrasound scans in the BUSI dataset for medical imagery pertaining to breast cancer has exhibited commendable segmentation outcomes through the application of UNet and UNet++ networks. Nevertheless, a notable drawback of these models resides in their inattention towards the temporal aspects embedded within the images. This research endeavors to enrich the UNet++ architecture by integrating LSTM layers and self-attention mechanisms to exploit temporal characteristics for segmentation purposes. Furthermore, the incorporation of a Multiscale Feature Extraction Module aims to grasp varied scale features within the UNet++. Through the amalgamation of our proposed methodology with data augmentation on the BUSI with GT dataset, an accuracy rate of 98.88%, specificity of 99.53%, precision of 95.34%, sensitivity of 91.20%, F1-score of 93.74, and Dice coefficient of 92.74% are achieved. These findings demonstrate competitiveness with cutting-edge techniques outlined in existing literature.
Enhancing Skin Cancer Diagnosis (SCD) Using Late Discrete Wavelet Transform (DWT) and New Swarm-Based Optimizers
Nov 30, 2024



Skin cancer (SC) stands out as one of the most life-threatening forms of cancer, with its danger amplified if not diagnosed and treated promptly. Early intervention is critical, as it allows for more effective treatment approaches. In recent years, Deep Learning (DL) has emerged as a powerful tool in the early detection and skin cancer diagnosis (SCD). Although the DL seems promising for the diagnosis of skin cancer, still ample scope exists for improving model efficiency and accuracy. This paper proposes a novel approach to skin cancer detection, utilizing optimization techniques in conjunction with pre-trained networks and wavelet transformations. First, normalized images will undergo pre-trained networks such as Densenet-121, Inception, Xception, and MobileNet to extract hierarchical features from input images. After feature extraction, the feature maps are passed through a Discrete Wavelet Transform (DWT) layer to capture low and high-frequency components. Then the self-attention module is integrated to learn global dependencies between features and focus on the most relevant parts of the feature maps. The number of neurons and optimization of the weight vectors are performed using three new swarm-based optimization techniques, such as Modified Gorilla Troops Optimizer (MGTO), Improved Gray Wolf Optimization (IGWO), and Fox optimization algorithm. Evaluation results demonstrate that optimizing weight vectors using optimization algorithms can enhance diagnostic accuracy and make it a highly effective approach for SCD. The proposed method demonstrates substantial improvements in accuracy, achieving top rates of 98.11% with the MobileNet + Wavelet + FOX and DenseNet + Wavelet + Fox combination on the ISIC-2016 dataset and 97.95% with the Inception + Wavelet + MGTO combination on the ISIC-2017 dataset, which improves accuracy by at least 1% compared to other methods.
Classifying Objects in 3D Point Clouds Using Recurrent Neural Network: A GRU LSTM Hybrid Approach
Mar 09, 2024Accurate classification of objects in 3D point clouds is a significant problem in several applications, such as autonomous navigation and augmented/virtual reality scenarios, which has become a research hot spot. In this paper, we presented a deep learning strategy for 3D object classification in augmented reality. The proposed approach is a combination of the GRU and LSTM. LSTM networks learn longer dependencies well, but due to the number of gates, it takes longer to train; on the other hand, GRU networks have a weaker performance than LSTM, but their training speed is much higher than GRU, which is The speed is due to its fewer gates. The proposed approach used the combination of speed and accuracy of these two networks. The proposed approach achieved an accuracy of 0.99 in the 4,499,0641 points dataset, which includes eight classes (unlabeled, man-made terrain, natural terrain, high vegetation, low vegetation, buildings, hardscape, scanning artifacts, cars). Meanwhile, the traditional machine learning approaches could achieve a maximum accuracy of 0.9489 in the best case. Keywords: Point Cloud Classification, Virtual Reality, Hybrid Model, GRULSTM, GRU, LSTM
weighted CapsuleNet networks for Persian multi-domain sentiment analysis
Jul 01, 2023Sentiment classification is a fundamental task in natural language processing, assigning one of the three classes, positive, negative, or neutral, to free texts. However, sentiment classification models are highly domain dependent; the classifier may perform classification with reasonable accuracy in one domain but not in another due to the Semantic multiplicity of words getting poor accuracy. This article presents a new Persian/Arabic multi-domain sentiment analysis method using the cumulative weighted capsule networks approach. Weighted capsule ensemble consists of training separate capsule networks for each domain and a weighting measure called domain belonging degree (DBD). This criterion consists of TF and IDF, which calculates the dependency of each document for each domain separately; this value is multiplied by the possible output that each capsule creates. In the end, the sum of these multiplications is the title of the final output, and is used to determine the polarity. And the most dependent domain is considered the final output for each domain. The proposed method was evaluated using the Digikala dataset and obtained acceptable accuracy compared to the existing approaches. It achieved an accuracy of 0.89 on detecting the domain of belonging and 0.99 on detecting the polarity. Also, for the problem of dealing with unbalanced classes, a cost-sensitive function was used. This function was able to achieve 0.0162 improvements in accuracy for sentiment classification. This approach on Amazon Arabic data can achieve 0.9695 accuracies in domain classification.
SLCNN: Sentence-Level Convolutional Neural Network for Text Classification
Jan 27, 2023Text classification is a fundamental task in natural language processing (NLP). Several recent studies show the success of deep learning on text processing. Convolutional neural network (CNN), as a popular deep learning model, has shown remarkable success in the task of text classification. In this paper, new baseline models have been studied for text classification using CNN. In these models, documents are fed to the network as a three-dimensional tensor representation to provide sentence-level analysis. Applying such a method enables the models to take advantage of the positional information of the sentences in the text. Besides, analysing adjacent sentences allows extracting additional features. The proposed models have been compared with the state-of-the-art models using several datasets. The results have shown that the proposed models have better performance, particularly in the longer documents.
TI-Capsule: Capsule Network for Stock Exchange Prediction
Feb 15, 2021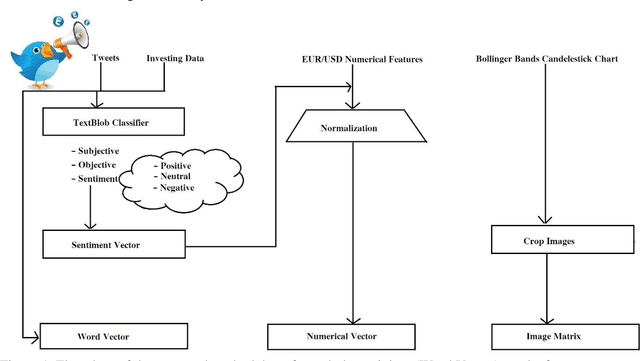
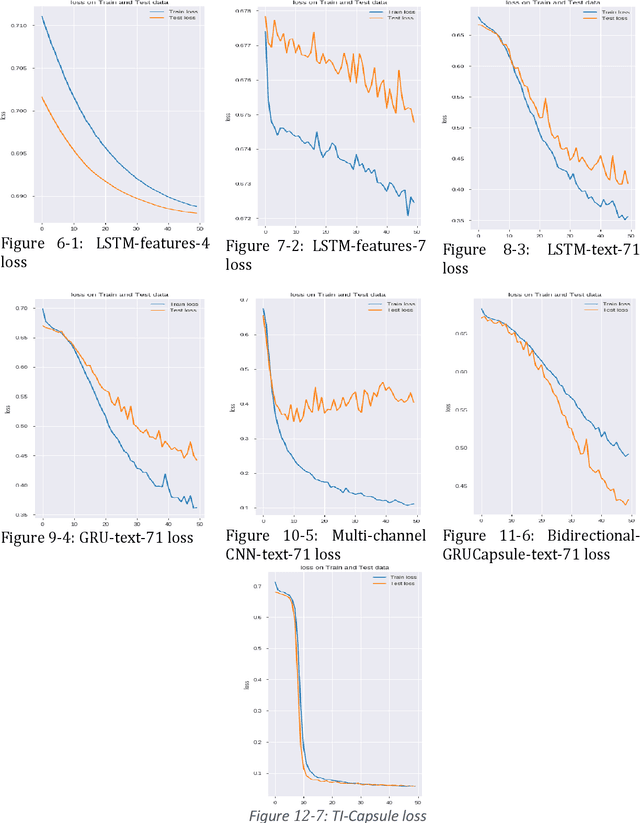

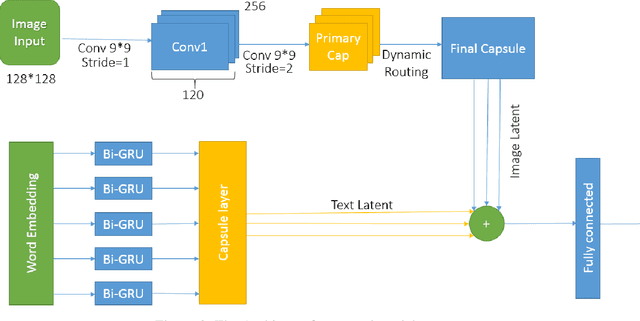
Today, the use of social networking data has attracted a lot of academic and commercial attention in predicting the stock market. In most studies in this area, the sentiment analysis of the content of user posts on social networks is used to predict market fluctuations. Predicting stock marketing is challenging because of the variables involved. In the short run, the market behaves like a voting machine, but in the long run, it acts like a weighing machine. The purpose of this study is to predict EUR/USD stock behavior using Capsule Network on finance texts and Candlestick images. One of the most important features of Capsule Network is the maintenance of features in a vector, which also takes into account the space between features. The proposed model, TI-Capsule (Text and Image information based Capsule Neural Network), is trained with both the text and image information simultaneously. Extensive experiments carried on the collected dataset have demonstrated the effectiveness of TI-Capsule in solving the stock exchange prediction problem with 91% accuracy.