 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperiments on Generalizability of User-Oriented Fairness in Recommender Systems
May 17, 2022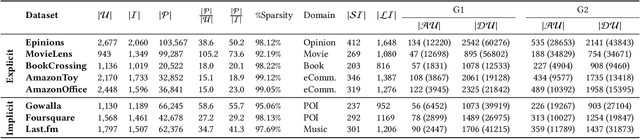
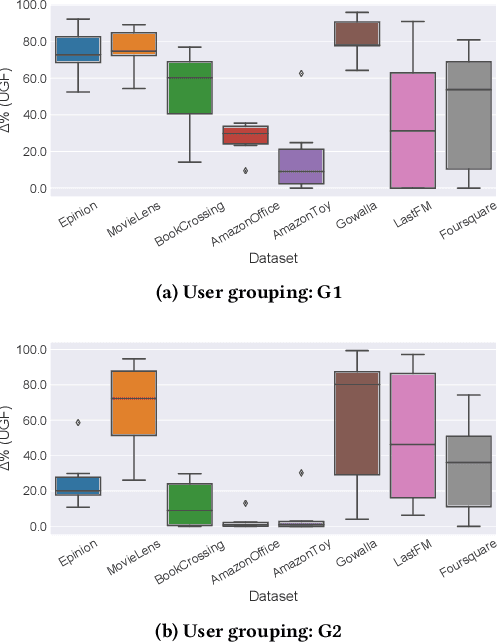
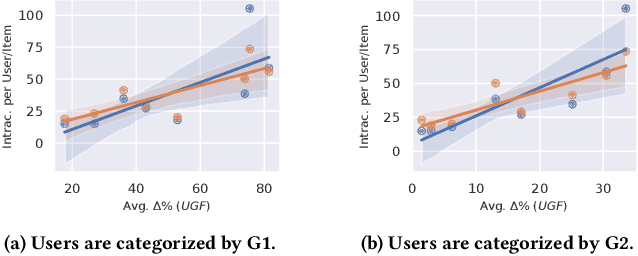
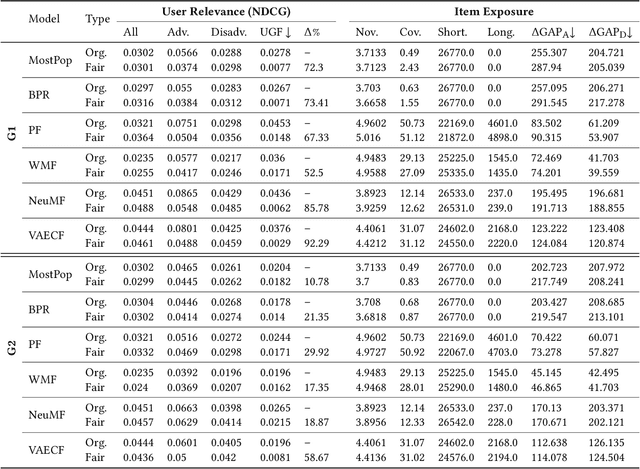
Recent work in recommender systems mainly focuses on fairness in recommendations as an important aspect of measuring recommendations quality. A fairness-aware recommender system aims to treat different user groups similarly. Relevant work on user-oriented fairness highlights the discriminative behavior of fairness-unaware recommendation algorithms towards a certain user group, defined based on users' activity level. Typical solutions include proposing a user-centered fairness re-ranking framework applied on top of a base ranking model to mitigate its unfair behavior towards a certain user group i.e., disadvantaged group. In this paper, we re-produce a user-oriented fairness study and provide extensive experiments to analyze the dependency of their proposed method on various fairness and recommendation aspects, including the recommendation domain, nature of the base ranking model, and user grouping method. Moreover, we evaluate the final recommendations provided by the re-ranking framework from both user- (e.g., NDCG, user-fairness) and item-side (e.g., novelty, item-fairness) metrics. We discover interesting trends and trade-offs between the model's performance in terms of different evaluation metrics. For instance, we see that the definition of the advantaged/disadvantaged user groups plays a crucial role in the effectiveness of the fairness algorithm and how it improves the performance of specific base ranking models. Finally, we highlight some important open challenges and future directions in this field. We release the data, evaluation pipeline, and the trained models publicly on https://github.com/rahmanidashti/FairRecSys.
The Unfairness of Popularity Bias in Book Recommendation
Feb 27, 2022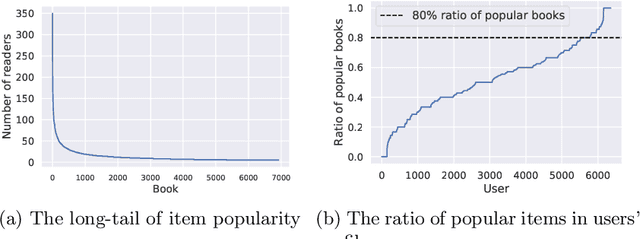

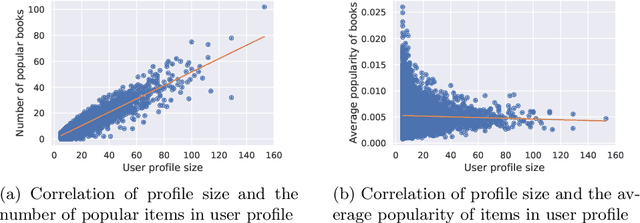
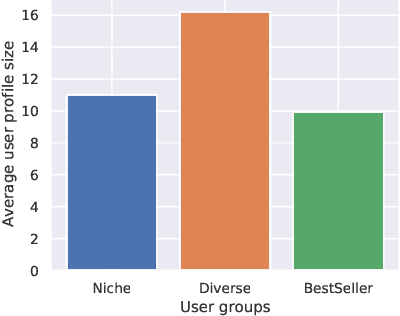
Recent studies have shown that recommendation systems commonly suffer from popularity bias. Popularity bias refers to the problem that popular items (i.e., frequently rated items) are recommended frequently while less popular items are recommended rarely or not at all. Researchers adopted two approaches to examining popularity bias: (i) from the users' perspective, by analyzing how far a recommendation system deviates from user's expectations in receiving popular items, and (ii) by analyzing the amount of exposure that long-tail items receive, measured by overall catalog coverage and novelty. In this paper, we examine the first point of view in the book domain, although the findings may be applied to other domains as well. To this end, we analyze the well-known Book-Crossing dataset and define three user groups based on their tendency towards popular items (i.e., Niche, Diverse, Bestseller-focused). Further, we evaluate the performance of nine state-of-the-art recommendation algorithms and two baselines (i.e., Random, MostPop) from both the accuracy (e.g., NDCG, Precision, Recall) and popularity bias perspectives. Our results indicate that most state-of-the-art recommendation algorithms suffer from popularity bias in the book domain, and fail to meet users' expectations with Niche and Diverse tastes despite having a larger profile size. Conversely, Bestseller-focused users are more likely to receive high-quality recommendations, both in terms of fairness and personalization. Furthermore, our study shows a tradeoff between personalization and unfairness of popularity bias in recommendation algorithms for users belonging to the Diverse and Bestseller groups, that is, algorithms with high capability of personalization suffer from the unfairness of popularity bias.
Mining Shape of Expertise: A Novel Approach Based on Convolutional Neural Network
Apr 05, 2020
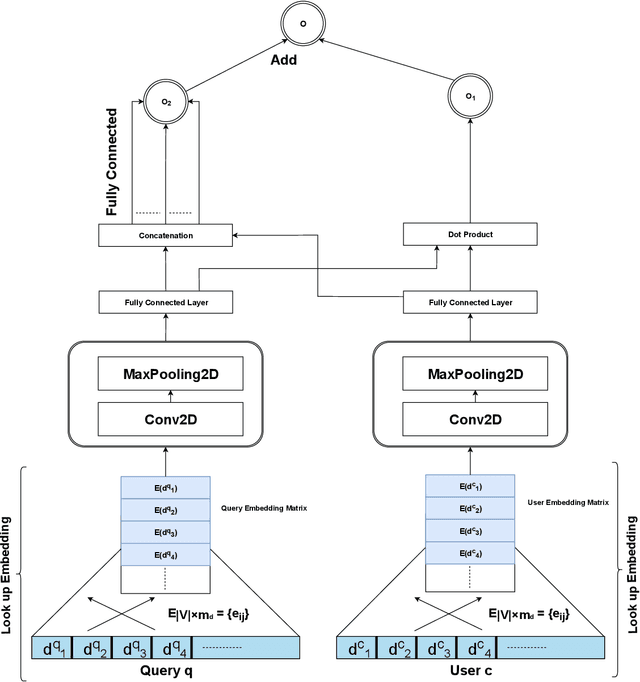

Expert finding addresses the task of retrieving and ranking talented people on the subject of user query. It is a practical issue in the Community Question Answering networks. Recruiters looking for knowledgeable people for their job positions are the most important clients of expert finding systems. In addition to employee expertise, the cost of hiring new staff is another significant concern for organizations. An efficient solution to cope with this concern is to hire T-shaped experts that are cost-effective. In this study, we have proposed a new deep model for T-shaped experts finding based on Convolutional Neural Networks. The proposed model tries to match queries and users by extracting local and position-invariant features from their corresponding documents. In other words, it detects users' shape of expertise by learning patterns from documents of users and queries simultaneously. The proposed model contains two parallel CNN's that extract latent vectors of users and queries based on their corresponding documents and join them together in the last layer to match queries with users. Experiments on a large subset of Stack Overflow documents indicate the effectiveness of the proposed method against baselines in terms of NDCG, MRR, and ERR evaluation metrics.