 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Distance-Guided Unsupervised Domain Adaptation for Automated Multi-Class Cardiovascular Magnetic Resonance Image Quality Assessment
Aug 31, 2024This study proposes an attention-based statistical distance-guided unsupervised domain adaptation model for multi-class cardiovascular magnetic resonance (CMR) image quality assessment. The proposed model consists of a feature extractor, a label predictor and a statistical distance estimator. An annotated dataset as the source set and an unlabeled dataset as the target set with different statistical distributions are considered inputs. The statistical distance estimator approximates the Wasserstein distance between the extracted feature vectors from the source and target data in a mini-batch. The label predictor predicts data labels of source data and uses a combinational loss function for training, which includes cross entropy and centre loss functions plus the estimated value of the distance estimator. Four datasets, including imaging and k-space data, were used to evaluate the proposed model in identifying four common CMR imaging artefacts: respiratory and cardiac motions, Gibbs ringing and Aliasing. The results of the extensive experiments showed that the proposed model, both in image and k-space analysis, has an acceptable performance in covering the domain shift between the source and target sets. The model explainability evaluations and the ablation studies confirmed the proper functioning and effectiveness of all the model's modules. The proposed model outperformed the previous studies regarding performance and the number of examined artefacts. The proposed model can be used for CMR post-imaging quality control or in large-scale cohort studies for image and k-space quality assessment due to the appropriate performance in domain shift coverage without a tedious data-labelling process.
Multiple Teachers-Meticulous Student: A Domain Adaptive Meta-Knowledge Distillation Model for Medical Image Classification
Mar 17, 2024



Background: Image classification can be considered one of the key pillars of medical image analysis. Deep learning (DL) faces challenges that prevent its practical applications despite the remarkable improvement in medical image classification. The data distribution differences can lead to a drop in the efficiency of DL, known as the domain shift problem. Besides, requiring bulk annotated data for model training, the large size of models, and the privacy-preserving of patients are other challenges of using DL in medical image classification. This study presents a strategy that can address the mentioned issues simultaneously. Method: The proposed domain adaptive model based on knowledge distillation can classify images by receiving limited annotated data of different distributions. The designed multiple teachers-meticulous student model trains a student network that tries to solve the challenges by receiving the parameters of several teacher networks. The proposed model was evaluated using six available datasets of different distributions by defining the respiratory motion artefact detection task. Results: The results of extensive experiments using several datasets show the superiority of the proposed model in addressing the domain shift problem and lack of access to bulk annotated data. Besides, the privacy preservation of patients by receiving only the teacher network parameters instead of the original data and consolidating the knowledge of several DL models into a model with almost similar performance are other advantages of the proposed model. Conclusions: The proposed model can pave the way for practical clinical applications of deep classification methods by achieving the mentioned objectives simultaneously.
A Generalised Deep Meta-Learning Model for Automated Quality Control of Cardiovascular Magnetic Resonance Images
Mar 23, 2023


Background and Objectives: Cardiovascular magnetic resonance (CMR) imaging is a powerful modality in functional and anatomical assessment for various cardiovascular diseases. Sufficient image quality is essential to achieve proper diagnosis and treatment. A large number of medical images, the variety of imaging artefacts, and the workload of imaging centres are among the things that reveal the necessity of automatic image quality assessment (IQA). However, automated IQA requires access to bulk annotated datasets for training deep learning (DL) models. Labelling medical images is a tedious, costly and time-consuming process, which creates a fundamental challenge in proposing DL-based methods for medical applications. This study aims to present a new method for CMR IQA when there is limited access to annotated datasets. Methods: The proposed generalised deep meta-learning model can evaluate the quality by learning tasks in the prior stage and then fine-tuning the resulting model on a small labelled dataset of the desired tasks. This model was evaluated on the data of over 6,000 subjects from the UK Biobank for five defined tasks, including detecting respiratory motion, cardiac motion, Aliasing and Gibbs ringing artefacts and images without artefacts. Results: The results of extensive experiments show the superiority of the proposed model. Besides, comparing the model's accuracy with the domain adaptation model indicates a significant difference by using only 64 annotated images related to the desired tasks. Conclusion: The proposed model can identify unknown artefacts in images with acceptable accuracy, which makes it suitable for medical applications and quality assessment of large cohorts.
Fully Automated Assessment of Cardiac Coverage in Cine Cardiovascular Magnetic Resonance Images using an Explainable Deep Visual Salient Region Detection Model
Jun 14, 2022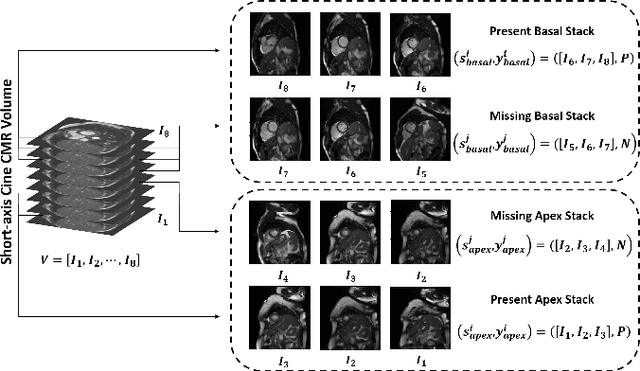

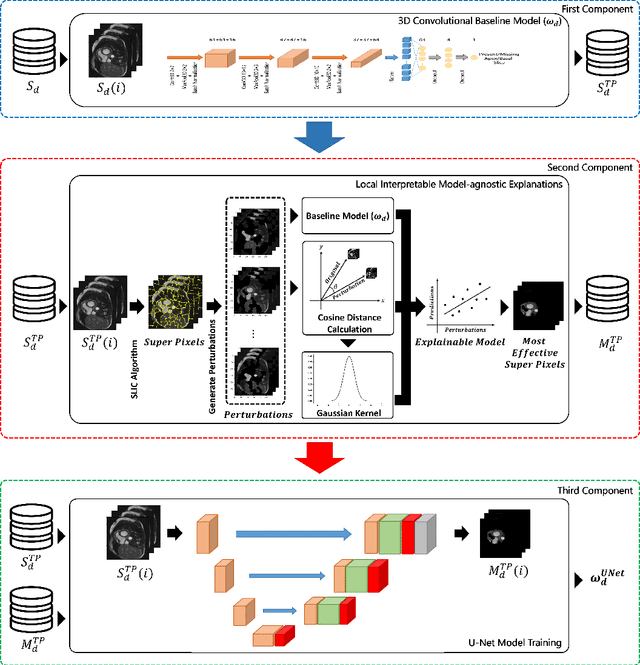
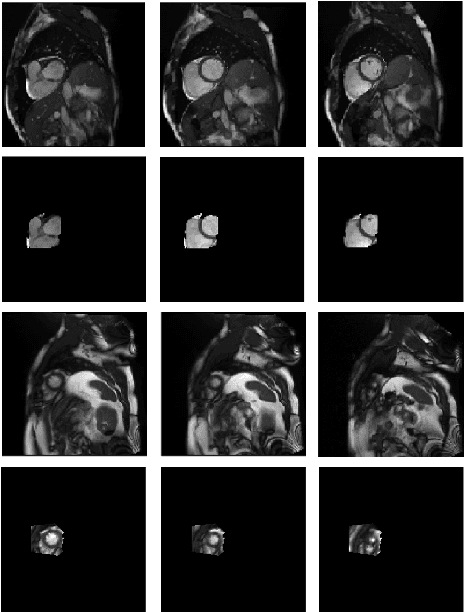
Cardiovascular magnetic resonance (CMR) imaging has become a modality with superior power for the diagnosis and prognosis of cardiovascular diseases. One of the essential basic quality controls of CMR images is to investigate the complete cardiac coverage, which is necessary for the volumetric and functional assessment. This study examines the full cardiac coverage using a 3D convolutional model and then reduces the number of false predictions using an innovative salient region detection model. Salient regions are extracted from the short-axis cine CMR stacks using a three-step proposed algorithm. Combining the 3D CNN baseline model with the proposed salient region detection model provides a cascade detector that can reduce the number of false negatives of the baseline model. The results obtained on the images of over 6,200 participants of the UK Biobank population cohort study show the superiority of the proposed model over the previous state-of-the-art studies. The dataset is the largest regarding the number of participants to control the cardiac coverage. The accuracy of the baseline model in identifying the presence/absence of basal/apical slices is 96.25\% and 94.51\%, respectively, which increases to 96.88\% and 95.72\% after improving using the proposed salient region detection model. Using the salient region detection model by forcing the baseline model to focus on the most informative areas of the images can help the model correct misclassified samples' predictions. The proposed fully automated model's performance indicates that this model can be used in image quality control in population cohort datasets and also real-time post-imaging quality assessments.
Automatic Multi-Class Cardiovascular Magnetic Resonance Image Quality Assessment using Unsupervised Domain Adaptation in Spatial and Frequency Domains
Dec 13, 2021
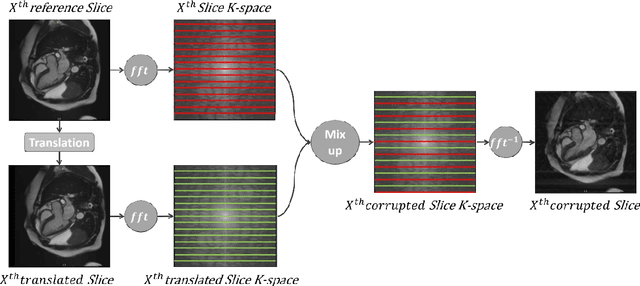
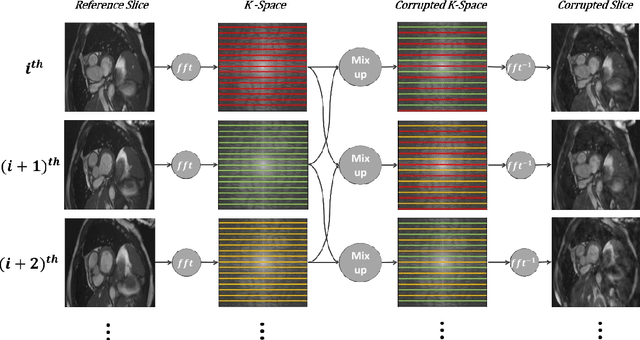
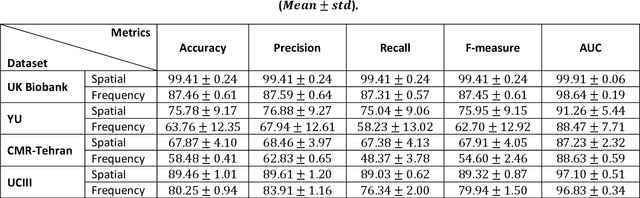
Population imaging studies rely upon good quality medical imagery before downstream image quantification. This study provides an automated approach to assess image quality from cardiovascular magnetic resonance (CMR) imaging at scale. We identify four common CMR imaging artefacts, including respiratory motion, cardiac motion, Gibbs ringing, and aliasing. The model can deal with images acquired in different views, including two, three, and four-chamber long-axis and short-axis cine CMR images. Two deep learning-based models in spatial and frequency domains are proposed. Besides recognising these artefacts, the proposed models are suitable to the common challenges of not having access to data labels. An unsupervised domain adaptation method and a Fourier-based convolutional neural network are proposed to overcome these challenges. We show that the proposed models reliably allow for CMR image quality assessment. The accuracies obtained for the spatial model in supervised and weakly supervised learning are 99.41+0.24 and 96.37+0.66 for the UK Biobank dataset, respectively. Using unsupervised domain adaptation can somewhat overcome the challenge of not having access to the data labels. The maximum achieved domain gap coverage in unsupervised domain adaptation is 16.86%. Domain adaptation can significantly improve a 5-class classification task and deal with considerable domain shift without data labels. Increasing the speed of training and testing can be achieved with the proposed model in the frequency domain. The frequency-domain model can achieve the same accuracy yet 1.548 times faster than the spatial model. This model can also be used directly on k-space data, and there is no need for image reconstruction.
Medical Imaging and Computational Image Analysis in COVID-19 Diagnosis: A Review
Oct 01, 2020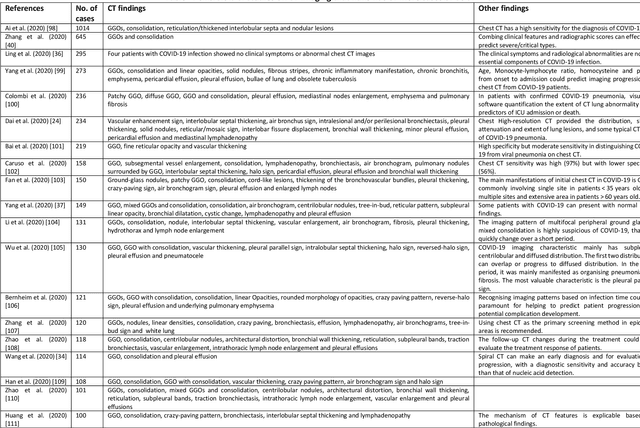
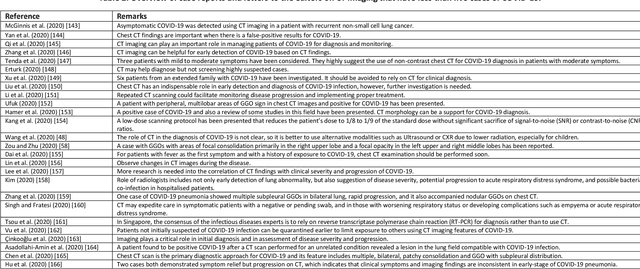

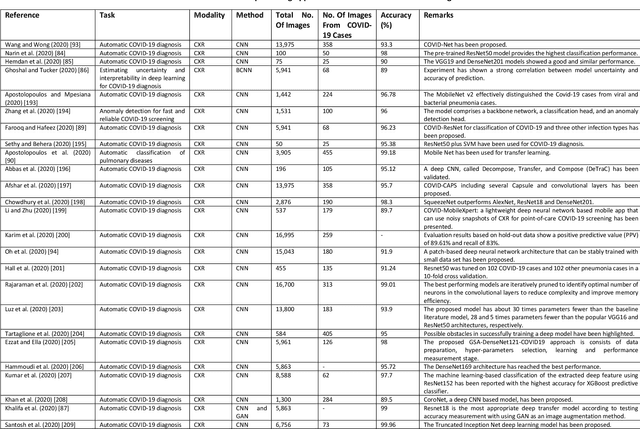
Coronavirus disease (COVID-19) is an infectious disease caused by a newly discovered coronavirus. The disease presents with symptoms such as shortness of breath, fever, dry cough, and chronic fatigue, amongst others. Sometimes the symptoms of the disease increase so much they lead to the death of the patients. The disease may be asymptomatic in some patients in the early stages, which can lead to increased transmission of the disease to others. Many studies have tried to use medical imaging for early diagnosis of COVID-19. This study attempts to review papers on automatic methods for medical image analysis and diagnosis of COVID-19. For this purpose, PubMed, Google Scholar, arXiv and medRxiv were searched to find related studies by the end of April 2020, and the essential points of the collected studies were summarised. The contribution of this study is four-fold: 1) to use as a tutorial of the field for both clinicians and technologists, 2) to comprehensively review the characteristics of COVID-19 as presented in medical images, 3) to examine automated artificial intelligence-based approaches for COVID-19 diagnosis based on the accuracy and the method used, 4) to express the research limitations in this field and the methods used to overcome them. COVID-19 reveals signs in medical images can be used for early diagnosis of the disease even in asymptomatic patients. Using automated machine learning-based methods can diagnose the disease with high accuracy from medical images and reduce time, cost and error of diagnostic procedure. It is recommended to collect bulk imaging data from patients in the shortest possible time to improve the performance of COVID-19 automated diagnostic methods.
Mining Shape of Expertise: A Novel Approach Based on Convolutional Neural Network
Apr 05, 2020
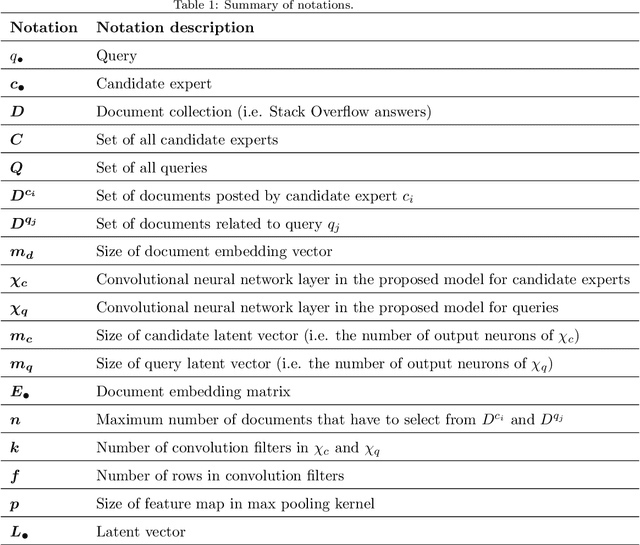
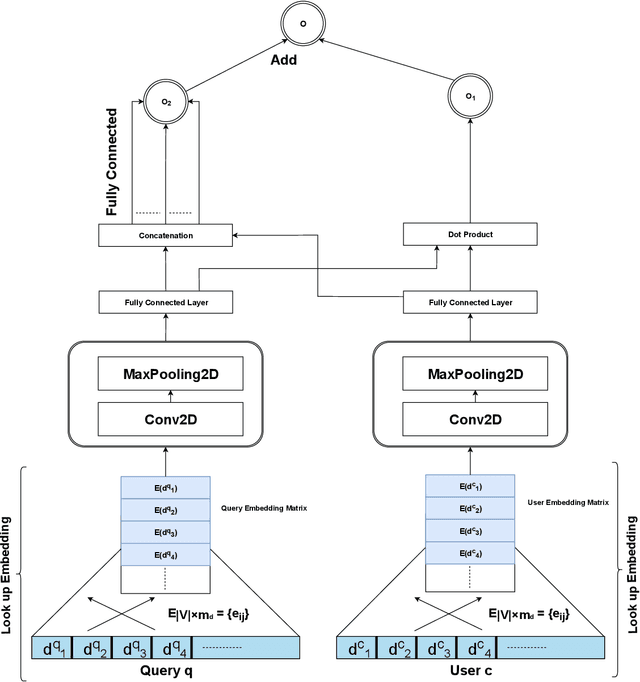

Expert finding addresses the task of retrieving and ranking talented people on the subject of user query. It is a practical issue in the Community Question Answering networks. Recruiters looking for knowledgeable people for their job positions are the most important clients of expert finding systems. In addition to employee expertise, the cost of hiring new staff is another significant concern for organizations. An efficient solution to cope with this concern is to hire T-shaped experts that are cost-effective. In this study, we have proposed a new deep model for T-shaped experts finding based on Convolutional Neural Networks. The proposed model tries to match queries and users by extracting local and position-invariant features from their corresponding documents. In other words, it detects users' shape of expertise by learning patterns from documents of users and queries simultaneously. The proposed model contains two parallel CNN's that extract latent vectors of users and queries based on their corresponding documents and join them together in the last layer to match queries with users. Experiments on a large subset of Stack Overflow documents indicate the effectiveness of the proposed method against baselines in terms of NDCG, MRR, and ERR evaluation metrics.