 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Pros and Cons of Using Machine Learning and Interpretable Machine Learning Methods in psychiatry detection applications, specifically depression disorder: A Brief Review
Nov 11, 2023The COVID-19 pandemic has forced many people to limit their social activities, which has resulted in a rise in mental illnesses, particularly depression. To diagnose these illnesses with accuracy and speed, and prevent severe outcomes such as suicide, the use of machine learning has become increasingly important. Additionally, to provide precise and understandable diagnoses for better treatment, AI scientists and researchers must develop interpretable AI-based solutions. This article provides an overview of relevant articles in the field of machine learning and interpretable AI, which helps to understand the advantages and disadvantages of using AI in psychiatry disorder detection applications.
A Generalised Deep Meta-Learning Model for Automated Quality Control of Cardiovascular Magnetic Resonance Images
Mar 23, 2023


Background and Objectives: Cardiovascular magnetic resonance (CMR) imaging is a powerful modality in functional and anatomical assessment for various cardiovascular diseases. Sufficient image quality is essential to achieve proper diagnosis and treatment. A large number of medical images, the variety of imaging artefacts, and the workload of imaging centres are among the things that reveal the necessity of automatic image quality assessment (IQA). However, automated IQA requires access to bulk annotated datasets for training deep learning (DL) models. Labelling medical images is a tedious, costly and time-consuming process, which creates a fundamental challenge in proposing DL-based methods for medical applications. This study aims to present a new method for CMR IQA when there is limited access to annotated datasets. Methods: The proposed generalised deep meta-learning model can evaluate the quality by learning tasks in the prior stage and then fine-tuning the resulting model on a small labelled dataset of the desired tasks. This model was evaluated on the data of over 6,000 subjects from the UK Biobank for five defined tasks, including detecting respiratory motion, cardiac motion, Aliasing and Gibbs ringing artefacts and images without artefacts. Results: The results of extensive experiments show the superiority of the proposed model. Besides, comparing the model's accuracy with the domain adaptation model indicates a significant difference by using only 64 annotated images related to the desired tasks. Conclusion: The proposed model can identify unknown artefacts in images with acceptable accuracy, which makes it suitable for medical applications and quality assessment of large cohorts.
Emotion Recognition In Persian Speech Using Deep Neural Networks
Apr 28, 2022



Speech Emotion Recognition (SER) is of great importance in Human-Computer Interaction (HCI), as it provides a deeper understanding of the situation and results in better interaction. In recent years, various machine learning and deep learning algorithms have been developed to improve SER techniques. Recognition of emotions depends on the type of expression that varies between different languages. In this article, to further study this important factor in Farsi, we examine various deep learning techniques on the SheEMO dataset. Using signal features in low- and high-level descriptions and different deep networks and machine learning techniques, Unweighted Average Recall (UAR) of 65.20 is achieved with an accuracy of 78.29.
* 4 pages, 1 figure, 3 tables
Automatic Multi-Class Cardiovascular Magnetic Resonance Image Quality Assessment using Unsupervised Domain Adaptation in Spatial and Frequency Domains
Dec 13, 2021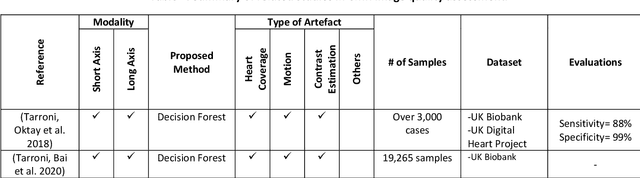
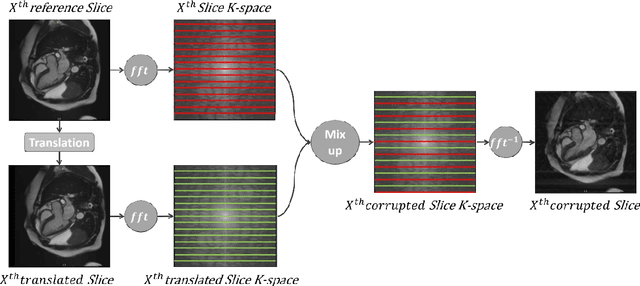
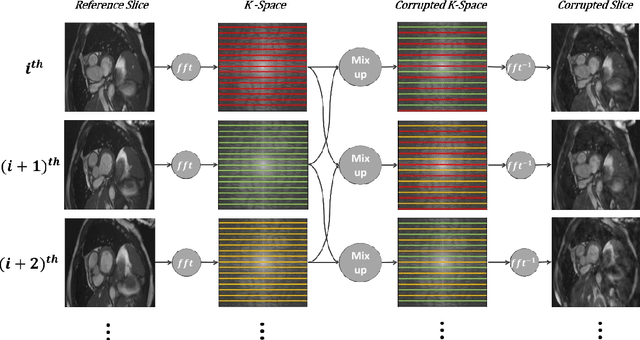
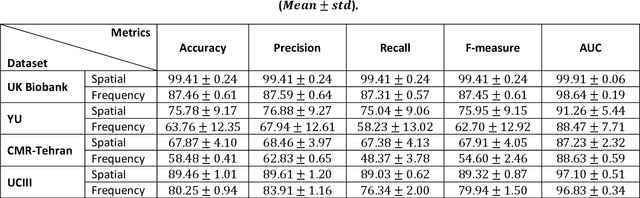
Population imaging studies rely upon good quality medical imagery before downstream image quantification. This study provides an automated approach to assess image quality from cardiovascular magnetic resonance (CMR) imaging at scale. We identify four common CMR imaging artefacts, including respiratory motion, cardiac motion, Gibbs ringing, and aliasing. The model can deal with images acquired in different views, including two, three, and four-chamber long-axis and short-axis cine CMR images. Two deep learning-based models in spatial and frequency domains are proposed. Besides recognising these artefacts, the proposed models are suitable to the common challenges of not having access to data labels. An unsupervised domain adaptation method and a Fourier-based convolutional neural network are proposed to overcome these challenges. We show that the proposed models reliably allow for CMR image quality assessment. The accuracies obtained for the spatial model in supervised and weakly supervised learning are 99.41+0.24 and 96.37+0.66 for the UK Biobank dataset, respectively. Using unsupervised domain adaptation can somewhat overcome the challenge of not having access to the data labels. The maximum achieved domain gap coverage in unsupervised domain adaptation is 16.86%. Domain adaptation can significantly improve a 5-class classification task and deal with considerable domain shift without data labels. Increasing the speed of training and testing can be achieved with the proposed model in the frequency domain. The frequency-domain model can achieve the same accuracy yet 1.548 times faster than the spatial model. This model can also be used directly on k-space data, and there is no need for image reconstruction.