 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Bias Through Ensemble Learning and Regularized Fine-Tuning
Feb 01, 2024Addressing biases in AI models is crucial for ensuring fair and accurate predictions. However, obtaining large, unbiased datasets for training can be challenging. This paper proposes a comprehensive approach using multiple methods to remove bias in AI models, with only a small dataset and a potentially biased pretrained model. We train multiple models with the counter-bias of the pre-trained model through data splitting, local training, and regularized fine-tuning, gaining potentially counter-biased models. Then, we employ ensemble learning for all models to reach unbiased predictions. To further accelerate the inference time of our ensemble model, we conclude our solution with knowledge distillation that results in a single unbiased neural network. We demonstrate the effectiveness of our approach through experiments on the CIFAR10 and HAM10000 datasets, showcasing promising results. This work contributes to the ongoing effort to create more unbiased and reliable AI models, even with limited data availability.
MVTN: Learning Multi-View Transformations for 3D Understanding
Dec 27, 2022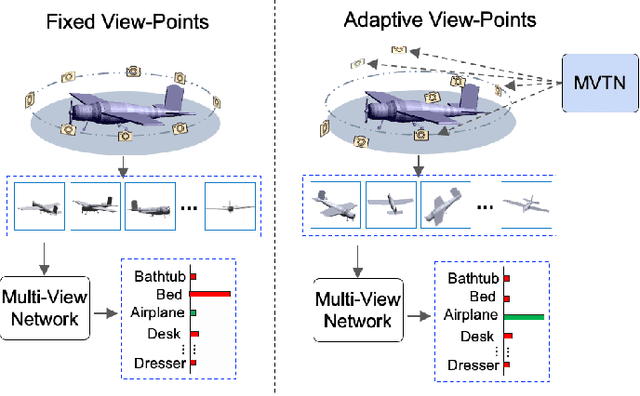
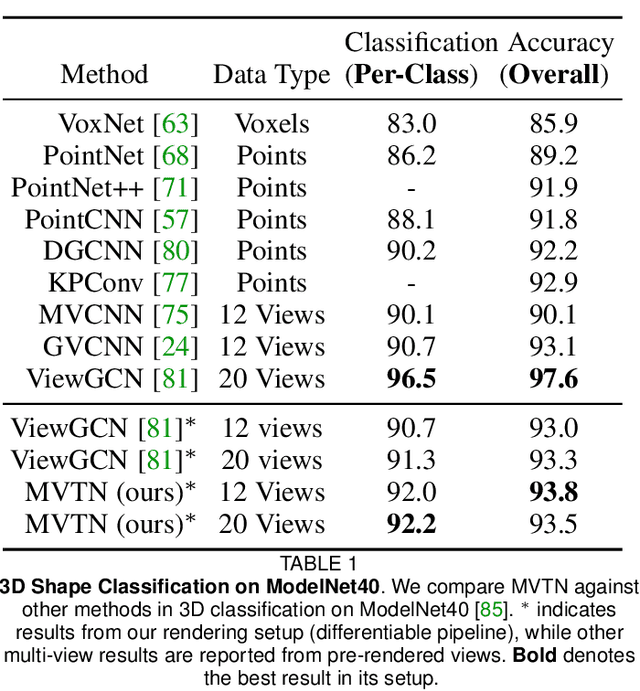
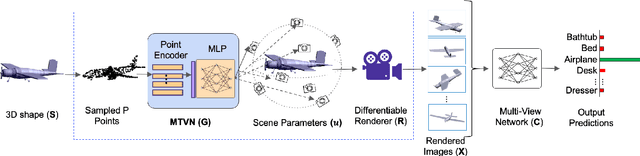
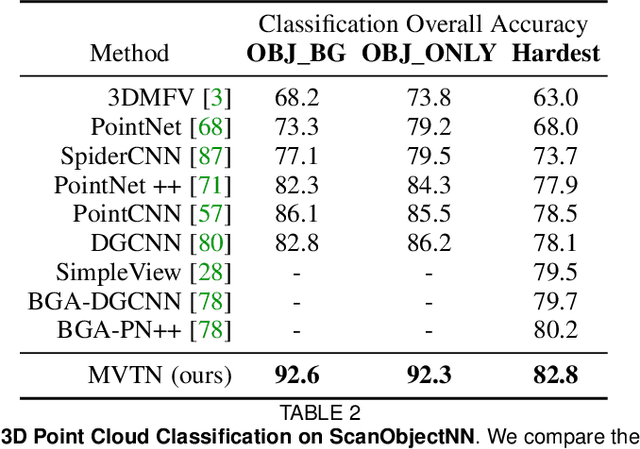
Multi-view projection techniques have shown themselves to be highly effective in achieving top-performing results in the recognition of 3D shapes. These methods involve learning how to combine information from multiple view-points. However, the camera view-points from which these views are obtained are often fixed for all shapes. To overcome the static nature of current multi-view techniques, we propose learning these view-points. Specifically, we introduce the Multi-View Transformation Network (MVTN), which uses differentiable rendering to determine optimal view-points for 3D shape recognition. As a result, MVTN can be trained end-to-end with any multi-view network for 3D shape classification. We integrate MVTN into a novel adaptive multi-view pipeline that is capable of rendering both 3D meshes and point clouds. Our approach demonstrates state-of-the-art performance in 3D classification and shape retrieval on several benchmarks (ModelNet40, ScanObjectNN, ShapeNet Core55). Further analysis indicates that our approach exhibits improved robustness to occlusion compared to other methods. We also investigate additional aspects of MVTN, such as 2D pretraining and its use for segmentation. To support further research in this area, we have released MVTorch, a PyTorch library for 3D understanding and generation using multi-view projections.