 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposing Object Relations and Attributes for Image-Text Matching
Paper and Code
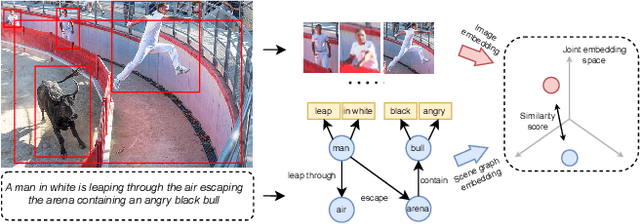
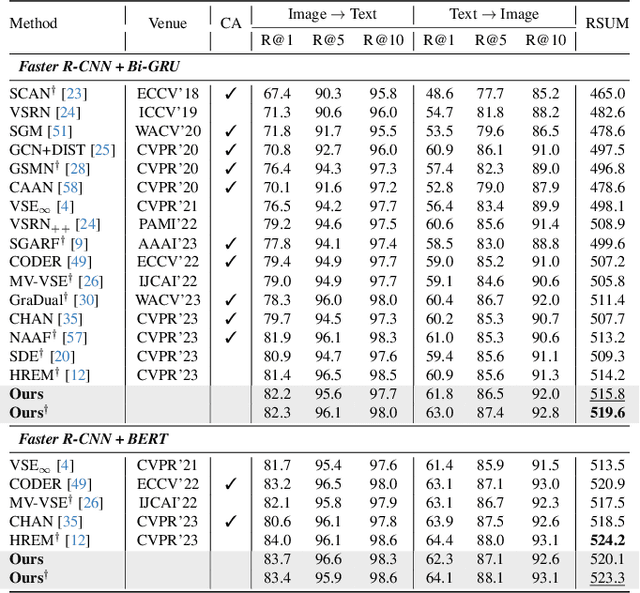

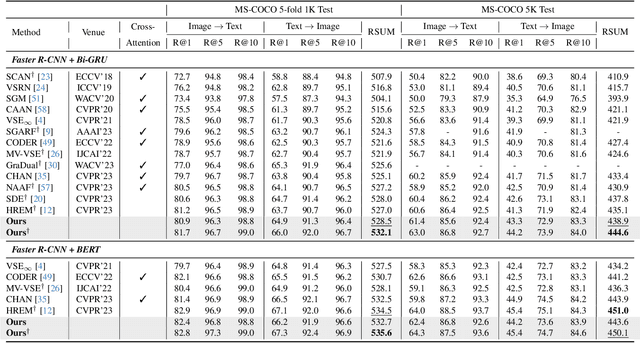
We study the visual semantic embedding problem for image-text matching. Most existing work utilizes a tailored cross-attention mechanism to perform local alignment across the two image and text modalities. This is computationally expensive, even though it is more powerful than the unimodal dual-encoder approach. This work introduces a dual-encoder image-text matching model, leveraging a scene graph to represent captions with nodes for objects and attributes interconnected by relational edges. Utilizing a graph attention network, our model efficiently encodes object-attribute and object-object semantic relations, resulting in a robust and fast-performing system. Representing caption as a scene graph offers the ability to utilize the strong relational inductive bias of graph neural networks to learn object-attribute and object-object relations effectively. To train the model, we propose losses that align the image and caption both at the holistic level (image-caption) and the local level (image-object entity), which we show is key to the success of the model. Our model is termed Composition model for Object Relations and Attributes, CORA. Experimental results on two prominent image-text retrieval benchmarks, Flickr30K and MSCOCO, demonstrate that CORA outperforms existing state-of-the-art computationally expensive cross-attention methods regarding recall score while achieving fast computation speed of the dual encoder.