 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Framework for Open-World Compositional Zero-shot Learning
Paper and Code
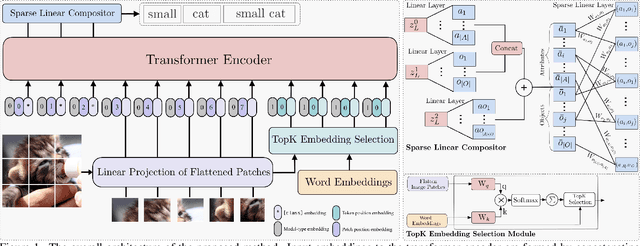



Open-World Compositional Zero-Shot Learning (OW-CZSL) addresses the challenge of recognizing novel compositions of known primitives and entities. Even though prior works utilize language knowledge for recognition, such approaches exhibit limited interactions between language-image modalities. Our approach primarily focuses on enhancing the inter-modality interactions through fostering richer interactions between image and textual data. Additionally, we introduce a novel module aimed at alleviating the computational burden associated with exhaustive exploration of all possible compositions during the inference stage. While previous methods exclusively learn compositions jointly or independently, we introduce an advanced hybrid procedure that leverages both learning mechanisms to generate final predictions. Our proposed model, achieves state-of-the-art in OW-CZSL in three datasets, while surpassing Large Vision Language Models (LLVM) in two datasets.