 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Character Models Match Large Word Models for Autocomplete Under Memory Constraints
Oct 06, 2022



Autocomplete is a task where the user inputs a piece of text, termed prompt, which is conditioned by the model to generate semantically coherent continuation. Existing works for this task have primarily focused on datasets (e.g., email, chat) with high frequency user prompt patterns (or focused prompts) where word-based language models have been quite effective. In this work, we study the more challenging setting consisting of low frequency user prompt patterns (or broad prompts, e.g., prompt about 93rd academy awards) and demonstrate the effectiveness of character-based language models. We study this problem under memory-constrained settings (e.g., edge devices and smartphones), where character-based representation is effective in reducing the overall model size (in terms of parameters). We use WikiText-103 benchmark to simulate broad prompts and demonstrate that character models rival word models in exact match accuracy for the autocomplete task, when controlled for the model size. For instance, we show that a 20M parameter character model performs similar to an 80M parameter word model in the vanilla setting. We further propose novel methods to improve character models by incorporating inductive bias in the form of compositional information and representation transfer from large word models.
One Network Doesn't Rule Them All: Moving Beyond Handcrafted Architectures in Self-Supervised Learning
Mar 15, 2022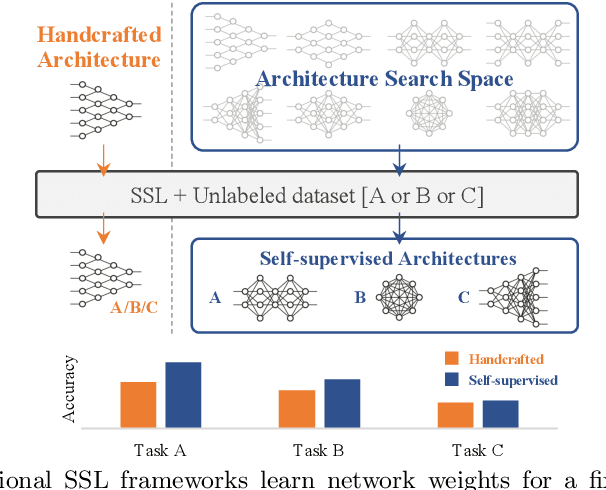
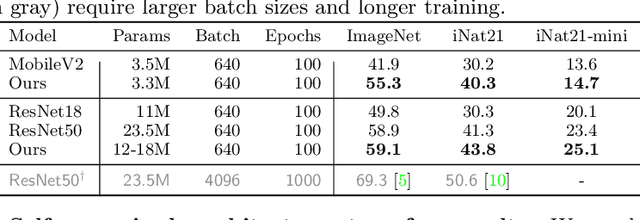
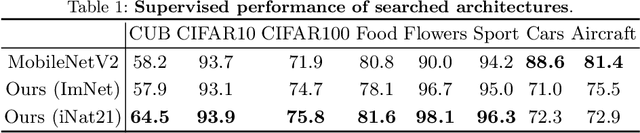
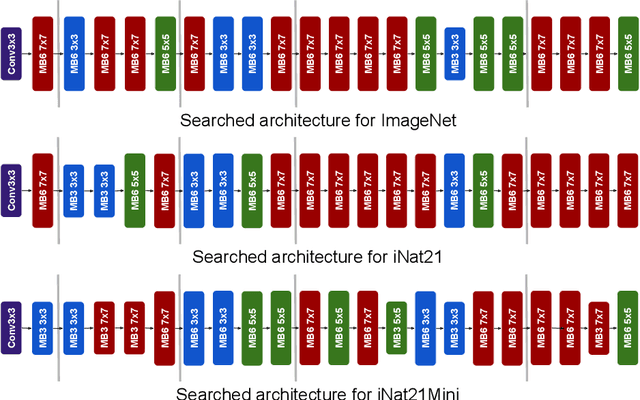
The current literature on self-supervised learning (SSL) focuses on developing learning objectives to train neural networks more effectively on unlabeled data. The typical development process involves taking well-established architectures, e.g., ResNet demonstrated on ImageNet, and using them to evaluate newly developed objectives on downstream scenarios. While convenient, this does not take into account the role of architectures which has been shown to be crucial in the supervised learning literature. In this work, we establish extensive empirical evidence showing that a network architecture plays a significant role in SSL. We conduct a large-scale study with over 100 variants of ResNet and MobileNet architectures and evaluate them across 11 downstream scenarios in the SSL setting. We show that there is no one network that performs consistently well across the scenarios. Based on this, we propose to learn not only network weights but also architecture topologies in the SSL regime. We show that "self-supervised architectures" outperform popular handcrafted architectures (ResNet18 and MobileNetV2) while performing competitively with the larger and computationally heavy ResNet50 on major image classification benchmarks (ImageNet-1K, iNat2021, and more). Our results suggest that it is time to consider moving beyond handcrafted architectures in SSL and start thinking about incorporating architecture search into self-supervised learning objectives.