 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA survey on text generation using generative adversarial networks
Dec 20, 2022



This work presents a thorough review concerning recent studies and text generation advancements using Generative Adversarial Networks. The usage of adversarial learning for text generation is promising as it provides alternatives to generate the so-called "natural" language. Nevertheless, adversarial text generation is not a simple task as its foremost architecture, the Generative Adversarial Networks, were designed to cope with continuous information (image) instead of discrete data (text). Thus, most works are based on three possible options, i.e., Gumbel-Softmax differentiation, Reinforcement Learning, and modified training objectives. All alternatives are reviewed in this survey as they present the most recent approaches for generating text using adversarial-based techniques. The selected works were taken from renowned databases, such as Science Direct, IEEEXplore, Springer, Association for Computing Machinery, and arXiv, whereas each selected work has been critically analyzed and assessed to present its objective, methodology, and experimental results.
Small Character Models Match Large Word Models for Autocomplete Under Memory Constraints
Oct 06, 2022



Autocomplete is a task where the user inputs a piece of text, termed prompt, which is conditioned by the model to generate semantically coherent continuation. Existing works for this task have primarily focused on datasets (e.g., email, chat) with high frequency user prompt patterns (or focused prompts) where word-based language models have been quite effective. In this work, we study the more challenging setting consisting of low frequency user prompt patterns (or broad prompts, e.g., prompt about 93rd academy awards) and demonstrate the effectiveness of character-based language models. We study this problem under memory-constrained settings (e.g., edge devices and smartphones), where character-based representation is effective in reducing the overall model size (in terms of parameters). We use WikiText-103 benchmark to simulate broad prompts and demonstrate that character models rival word models in exact match accuracy for the autocomplete task, when controlled for the model size. For instance, we show that a 20M parameter character model performs similar to an 80M parameter word model in the vanilla setting. We further propose novel methods to improve character models by incorporating inductive bias in the form of compositional information and representation transfer from large word models.
Comparative Study Between Distance Measures On Supervised Optimum-Path Forest Classification
Feb 08, 2022



Machine Learning has attracted considerable attention throughout the past decade due to its potential to solve far-reaching tasks, such as image classification, object recognition, anomaly detection, and data forecasting. A standard approach to tackle such applications is based on supervised learning, which is assisted by large sets of labeled data and is conducted by the so-called classifiers, such as Logistic Regression, Decision Trees, Random Forests, and Support Vector Machines, among others. An alternative to traditional classifiers is the parameterless Optimum-Path Forest (OPF), which uses a graph-based methodology and a distance measure to create arcs between nodes and hence sets of trees, responsible for conquering the nodes, defining their labels, and shaping the forests. Nevertheless, its performance is strongly associated with an appropriate distance measure, which may vary according to the dataset's nature. Therefore, this work proposes a comparative study over a wide range of distance measures applied to the supervised Optimum-Path Forest classification. The experimental results are conducted using well-known literature datasets and compared across benchmarking classifiers, illustrating OPF's ability to adapt to distinct domains.
Learnergy: Energy-based Machine Learners
Mar 16, 2020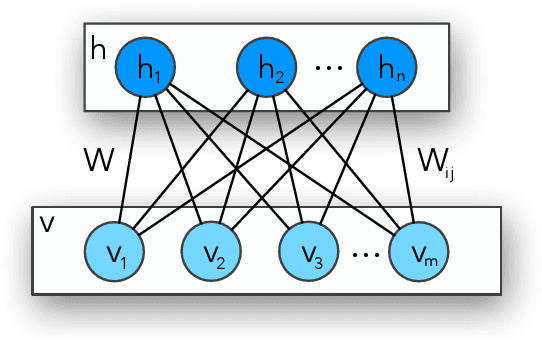

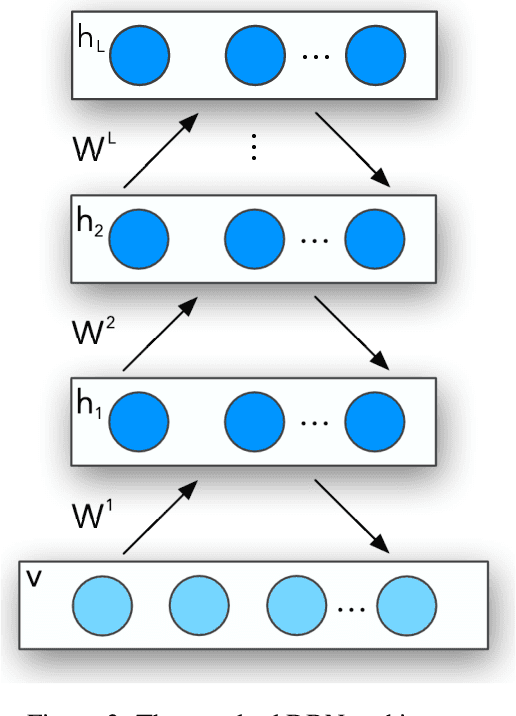
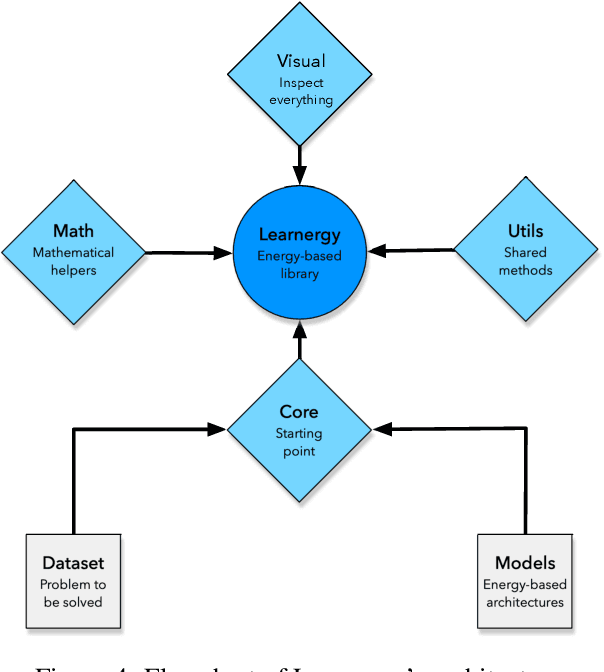
Throughout the last years, machine learning techniques have been broadly encouraged in the context of deep learning architectures. An interesting algorithm denoted as Restricted Boltzmann Machine relies on energy- and probabilistic-based nature to tackle with the most diverse applications, such as classification, reconstruction, and generation of images and signals. Nevertheless, one can see they are not adequately renowned when compared to other well-known deep learning techniques, e.g., Convolutional Neural Networks. Such behavior promotes the lack of researches and implementations around the literature, coping with the challenge of sufficiently comprehending these energy-based systems. Therefore, in this paper, we propose a Python-inspired framework in the context of energy-based architectures, denoted as Learnergy. Essentially, Learnergy is built upon PyTorch for providing a more friendly environment and a faster prototyping workspace, as well as, possibility the usage of CUDA computations, speeding up their computational time.
OPFython: A Python-Inspired Optimum-Path Forest Classifier
Jan 28, 2020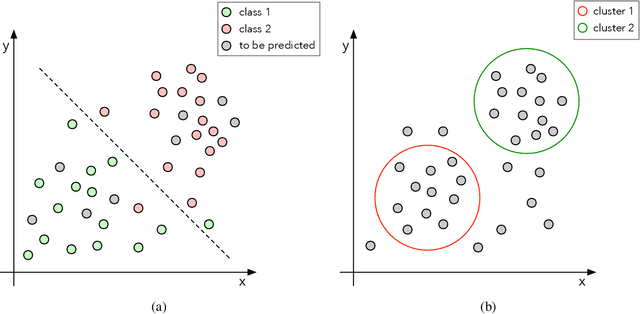
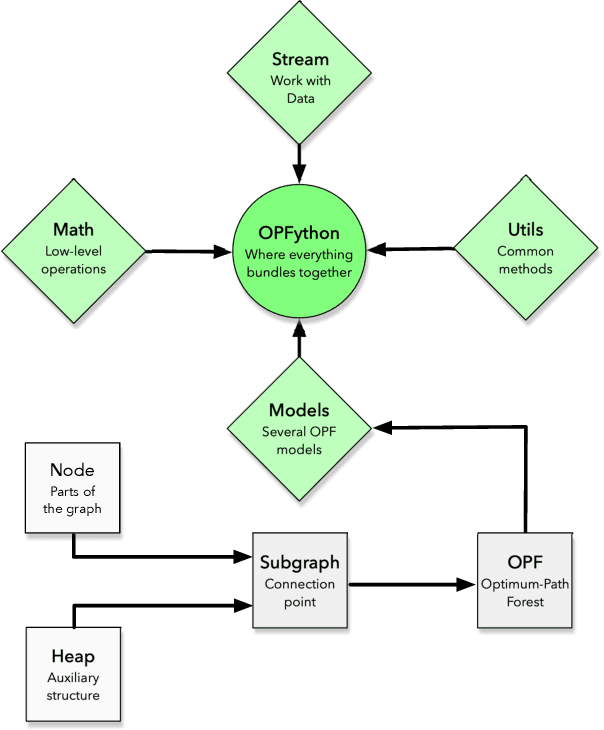
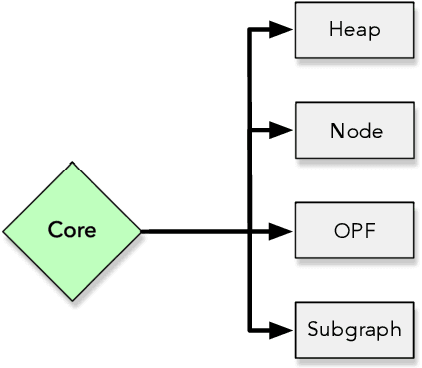
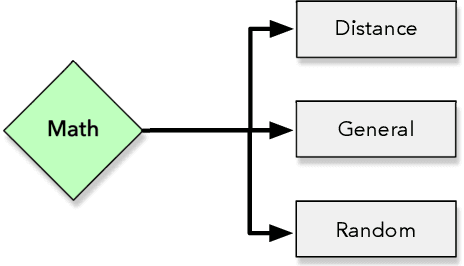
Machine learning techniques have been paramount throughout the last years, being applied in a wide range of tasks, such as classification, object recognition, person identification, image segmentation, among others. Nevertheless, conventional classification algorithms, e.g., Logistic Regression, Decision Trees, Bayesian classifiers, might lack complexity and diversity, not being suitable when dealing with real-world data. A recent graph-inspired classifier, known as the Optimum-Path Forest, has proven to be a state-of-the-art technique, comparable to Support Vector Machines and even surpassing it in some tasks. In this paper, we propose a Python-based Optimum-Path Forest framework, denoted as OPFython, where all of its functions and classes are based upon the original C language implementation. Additionally, as OPFython is a Python-based library, it provides a more friendly environment and a faster prototyping workspace than the C language.