 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNIRVANA: Neural Implicit Representations of Videos with Adaptive Networks and Autoregressive Patch-wise Modeling
Dec 30, 2022Implicit Neural Representations (INR) have recently shown to be powerful tool for high-quality video compression. However, existing works are limiting as they do not explicitly exploit the temporal redundancy in videos, leading to a long encoding time. Additionally, these methods have fixed architectures which do not scale to longer videos or higher resolutions. To address these issues, we propose NIRVANA, which treats videos as groups of frames and fits separate networks to each group performing patch-wise prediction. This design shares computation within each group, in the spatial and temporal dimensions, resulting in reduced encoding time of the video. The video representation is modeled autoregressively, with networks fit on a current group initialized using weights from the previous group's model. To further enhance efficiency, we perform quantization of the network parameters during training, requiring no post-hoc pruning or quantization. When compared with previous works on the benchmark UVG dataset, NIRVANA improves encoding quality from 37.36 to 37.70 (in terms of PSNR) and the encoding speed by 12X, while maintaining the same compression rate. In contrast to prior video INR works which struggle with larger resolution and longer videos, we show that our algorithm is highly flexible and scales naturally due to its patch-wise and autoregressive designs. Moreover, our method achieves variable bitrate compression by adapting to videos with varying inter-frame motion. NIRVANA achieves 6X decoding speed and scales well with more GPUs, making it practical for various deployment scenarios.
Revisiting Neighborhood-based Link Prediction for Collaborative Filtering
Mar 29, 2022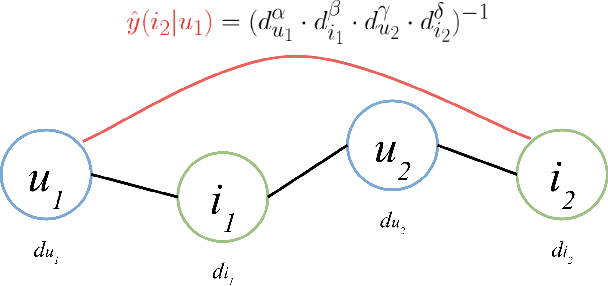
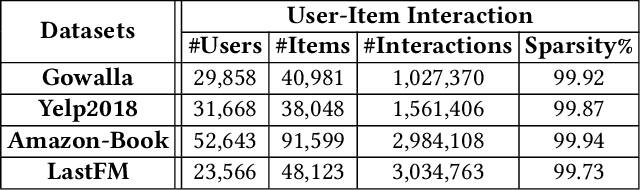
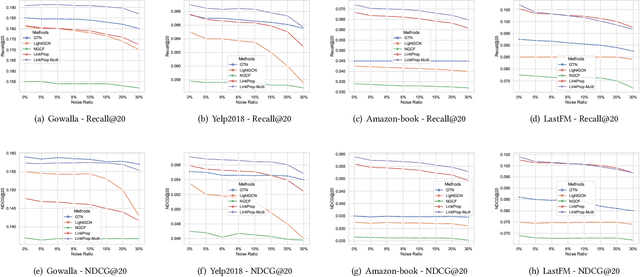
Collaborative filtering (CF) is one of the most successful and fundamental techniques in recommendation systems. In recent years, Graph Neural Network (GNN)-based CF models, such as NGCF [31], LightGCN [10] and GTN [9] have achieved tremendous success and significantly advanced the state-of-the-art. While there is a rich literature of such works using advanced models for learning user and item representations separately, item recommendation is essentially a link prediction problem between users and items. Furthermore, while there have been early works employing link prediction for collaborative filtering [5, 6], this trend has largely given way to works focused on aggregating information from user and item nodes, rather than modeling links directly. In this paper, we propose a new linkage (connectivity) score for bipartite graphs, generalizing multiple standard link prediction methods. We combine this new score with an iterative degree update process in the user-item interaction bipartite graph to exploit local graph structures without any node modeling. The result is a simple, non-deep learning model with only six learnable parameters. Despite its simplicity, we demonstrate our approach significantly outperforms existing state-of-the-art GNN-based CF approaches on four widely used benchmarks. In particular, on Amazon-Book, we demonstrate an over 60% improvement for both Recall and NDCG. We hope our work would invite the community to revisit the link prediction aspect of collaborative filtering, where significant performance gains could be achieved through aligning link prediction with item recommendations.
A Dataset for Developing and Benchmarking Active Vision
Mar 03, 2017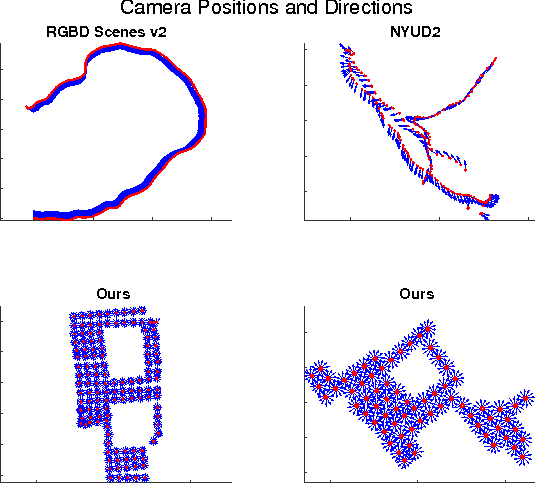


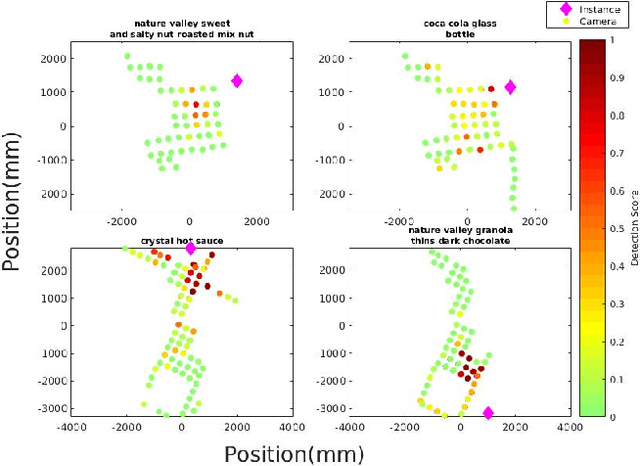
We present a new public dataset with a focus on simulating robotic vision tasks in everyday indoor environments using real imagery. The dataset includes 20,000+ RGB-D images and 50,000+ 2D bounding boxes of object instances densely captured in 9 unique scenes. We train a fast object category detector for instance detection on our data. Using the dataset we show that, although increasingly accurate and fast, the state of the art for object detection is still severely impacted by object scale, occlusion, and viewing direction all of which matter for robotics applications. We next validate the dataset for simulating active vision, and use the dataset to develop and evaluate a deep-network-based system for next best move prediction for object classification using reinforcement learning. Our dataset is available for download at cs.unc.edu/~ammirato/active_vision_dataset_website/.
Fast Single Shot Detection and Pose Estimation
Sep 19, 2016
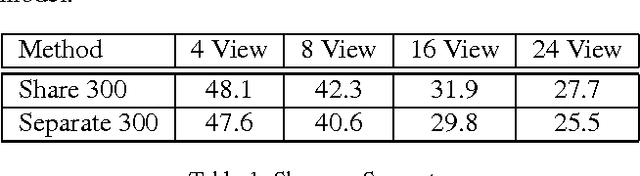
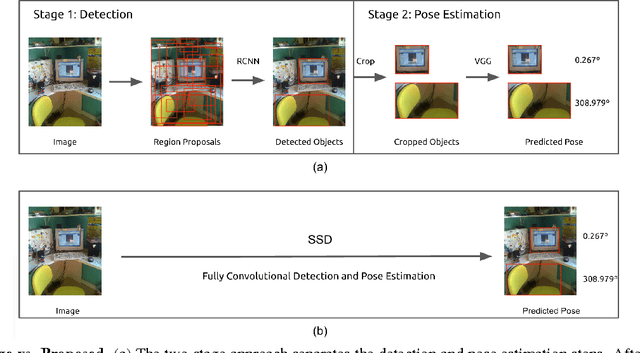
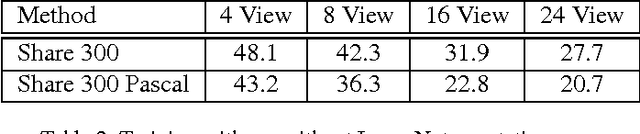
For applications in navigation and robotics, estimating the 3D pose of objects is as important as detection. Many approaches to pose estimation rely on detecting or tracking parts or keypoints [11, 21]. In this paper we build on a recent state-of-the-art convolutional network for slidingwindow detection [10] to provide detection and rough pose estimation in a single shot, without intermediate stages of detecting parts or initial bounding boxes. While not the first system to treat pose estimation as a categorization problem, this is the first attempt to combine detection and pose estimation at the same level using a deep learning approach. The key to the architecture is a deep convolutional network where scores for the presence of an object category, the offset for its location, and the approximate pose are all estimated on a regular grid of locations in the image. The resulting system is as accurate as recent work on pose estimation (42.4% 8 View mAVP on Pascal 3D+ [21] ) and significantly faster (46 frames per second (FPS) on a TITAN X GPU). This approach to detection and rough pose estimation is fast and accurate enough to be widely applied as a pre-processing step for tasks including high-accuracy pose estimation, object tracking and localization, and vSLAM.
Modeling Context in Referring Expressions
Aug 10, 2016

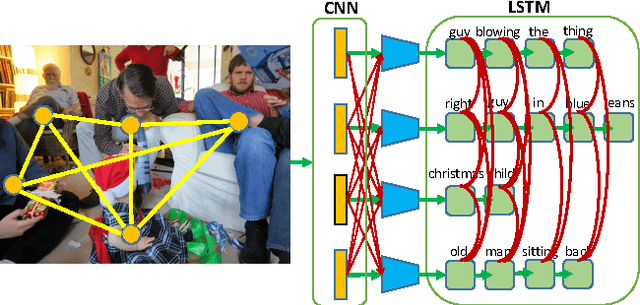
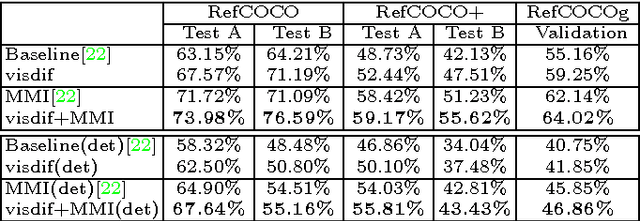
Humans refer to objects in their environments all the time, especially in dialogue with other people. We explore generating and comprehending natural language referring expressions for objects in images. In particular, we focus on incorporating better measures of visual context into referring expression models and find that visual comparison to other objects within an image helps improve performance significantly. We also develop methods to tie the language generation process together, so that we generate expressions for all objects of a particular category jointly. Evaluation on three recent datasets - RefCOCO, RefCOCO+, and RefCOCOg, shows the advantages of our methods for both referring expression generation and comprehension.