Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Context in Referring Expressions
Paper and Code


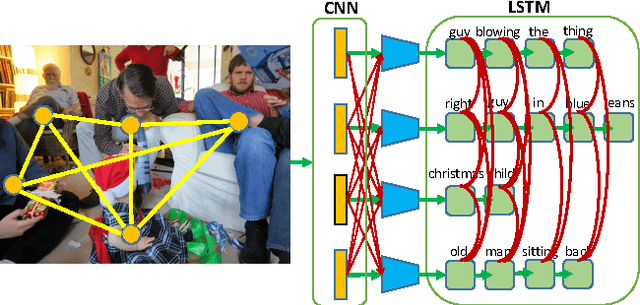
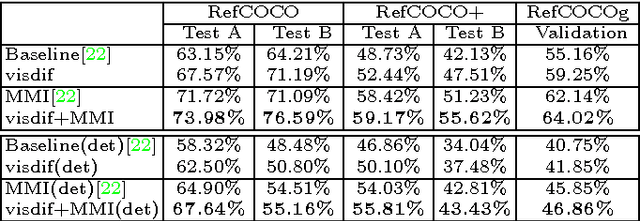
Humans refer to objects in their environments all the time, especially in dialogue with other people. We explore generating and comprehending natural language referring expressions for objects in images. In particular, we focus on incorporating better measures of visual context into referring expression models and find that visual comparison to other objects within an image helps improve performance significantly. We also develop methods to tie the language generation process together, so that we generate expressions for all objects of a particular category jointly. Evaluation on three recent datasets - RefCOCO, RefCOCO+, and RefCOCOg, shows the advantages of our methods for both referring expression generation and comprehension.
* 19 pages, 6 figures, in ECCV 2016; authors, references and
acknowledgement updated
View paper on