 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU2AD: Uncertainty-based Unsupervised Anomaly Detection Framework for Detecting T2 Hyperintensity in MRI Spinal Cord
Mar 17, 2025T2 hyperintensities in spinal cord MR images are crucial biomarkers for conditions such as degenerative cervical myelopathy. However, current clinical diagnoses primarily rely on manual evaluation. Deep learning methods have shown promise in lesion detection, but most supervised approaches are heavily dependent on large, annotated datasets. Unsupervised anomaly detection (UAD) offers a compelling alternative by eliminating the need for abnormal data annotations. However, existing UAD methods rely on curated normal datasets and their performance frequently deteriorates when applied to clinical datasets due to domain shifts. We propose an Uncertainty-based Unsupervised Anomaly Detection framework, termed U2AD, to address these limitations. Unlike traditional methods, U2AD is designed to be trained and tested within the same clinical dataset, following a "mask-and-reconstruction" paradigm built on a Vision Transformer-based architecture. We introduce an uncertainty-guided masking strategy to resolve task conflicts between normal reconstruction and anomaly detection to achieve an optimal balance. Specifically, we employ a Monte-Carlo sampling technique to estimate reconstruction uncertainty mappings during training. By iteratively optimizing reconstruction training under the guidance of both epistemic and aleatoric uncertainty, U2AD reduces overall reconstruction variance while emphasizing regions. Experimental results demonstrate that U2AD outperforms existing supervised and unsupervised methods in patient-level identification and segment-level localization tasks. This framework establishes a new benchmark for incorporating uncertainty guidance into UAD, highlighting its clinical utility in addressing domain shifts and task conflicts in medical image anomaly detection. Our code is available: https://github.com/zhibaishouheilab/U2AD
Pathology-Guided AI System for Accurate Segmentation and Diagnosis of Cervical Spondylosis
Mar 08, 2025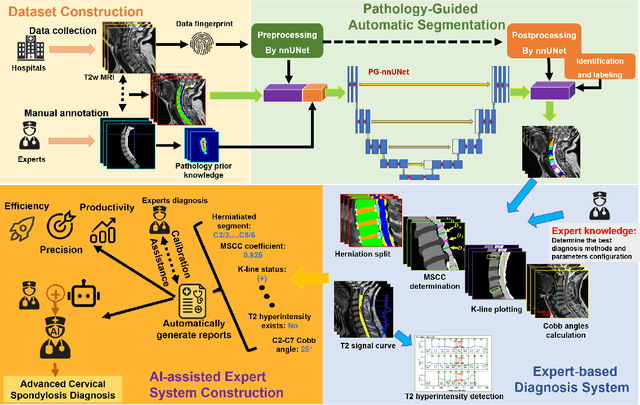
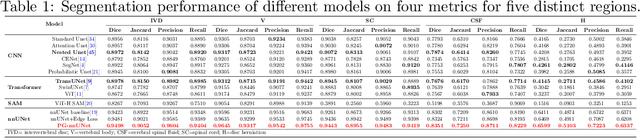
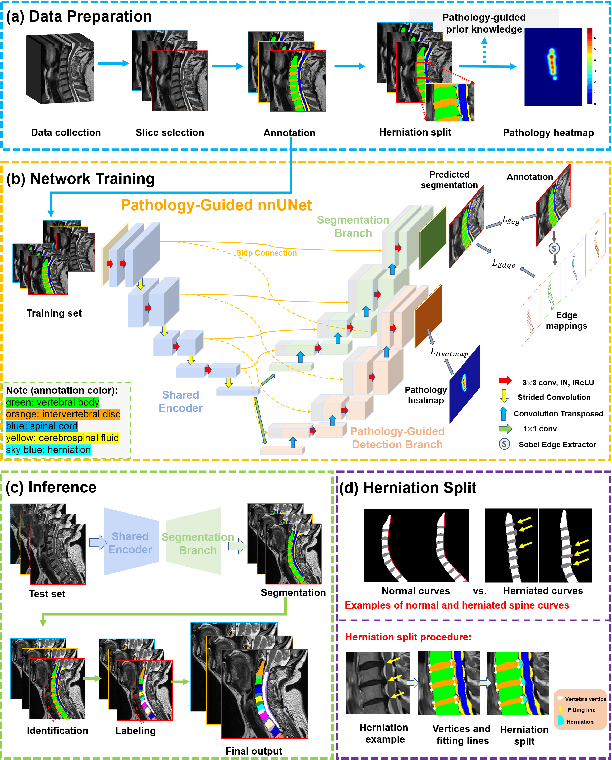
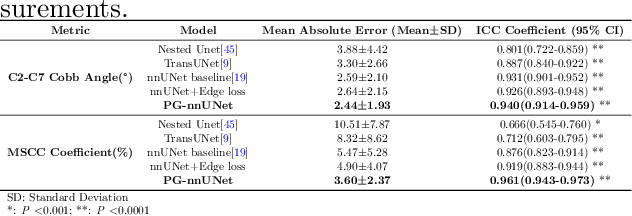
Cervical spondylosis, a complex and prevalent condition, demands precise and efficient diagnostic techniques for accurate assessment. While MRI offers detailed visualization of cervical spine anatomy, manual interpretation remains labor-intensive and prone to error. To address this, we developed an innovative AI-assisted Expert-based Diagnosis System that automates both segmentation and diagnosis of cervical spondylosis using MRI. Leveraging a dataset of 960 cervical MRI images from patients with cervical disc herniation, our system features a pathology-guided segmentation model capable of accurately segmenting key cervical anatomical structures. The segmentation is followed by an expert-based diagnostic framework that automates the calculation of critical clinical indicators. Our segmentation model achieved an impressive average Dice coefficient exceeding 0.90 across four cervical spinal anatomies and demonstrated enhanced accuracy in herniation areas. Diagnostic evaluation further showcased the system precision, with a mean absolute error (MAE) of 2.44 degree for the C2-C7 Cobb angle and 3.60 precentage for the Maximum Spinal Cord Compression (MSCC) coefficient. In addition, our method delivered high accuracy, precision, recall, and F1 scores in herniation localization, K-line status assessment, and T2 hyperintensity detection. Comparative analysis demonstrates that our system outperforms existing methods, establishing a new benchmark for segmentation and diagnostic tasks for cervical spondylosis.
AutoEval-Video: An Automatic Benchmark for Assessing Large Vision Language Models in Open-Ended Video Question Answering
Nov 25, 2023We propose a novel and challenging benchmark, AutoEval-Video, to comprehensively evaluate large vision-language models in open-ended video question answering. The comprehensiveness of AutoEval-Video is demonstrated in two aspects: 1) AutoEval-Video constructs open-ended video-questions across 9 skill dimensions, addressing capabilities of perception, comprehension, and generation. 2) AutoEval-Video contains newly collected videos that cover over 40 distinct themes. To efficiently evaluate responses to the open-ended questions, we employ an LLM-based evaluation approach, but instead of merely providing a reference answer, we annotate unique evaluation rules for every single instance (video-question pair). To maximize the robustness of these rules, we develop a novel adversarial annotation mechanism. By using instance-specific rules as prompt, GPT-4, as an automatic evaluator, can achieve a stable evaluation accuracy of around 97.0\%, comparable to the 94.9\% - 97.5\% accuracy of a human evaluator. Furthermore, we assess the performance of eight large vision-language models on AutoEval-Video. Among them, GPT-4V(ision) significantly outperforms other models, achieving an accuracy of 32.2\%. However, there is still substantial room for improvement compared to human accuracy of 72.8\%. By conducting an extensive case study, we uncover several drawbacks of GPT-4V, such as limited temporal and dynamic comprehension, and overly general responses. Code is available at \href{https://github.com/Xiuyuan-Chen/AutoEval-Video}{\color{magenta}https://github.com/Xiuyuan-Chen/AutoEval-Video}.
NIST: An Image Classification Network to Image Semantic Retrieval
Jul 02, 2016



This paper proposes a classification network to image semantic retrieval (NIST) framework to counter the image retrieval challenge. Our approach leverages the successful classification network GoogleNet based on Convolutional Neural Networks to obtain the semantic feature matrix which contains the serial number of classes and corresponding probabilities. Compared with traditional image retrieval using feature matching to compute the similarity between two images, NIST leverages the semantic information to construct semantic feature matrix and uses the semantic distance algorithm to compute the similarity. Besides, the fusion strategy can significantly reduce storage and time consumption due to less classes participating in the last semantic distance computation. Experiments demonstrate that our NIST framework produces state-of-the-art results in retrieval experiments on MIRFLICKR-25K dataset.